Today, with the rapid development of AI technology, small language models (SLM) have attracted much attention due to their ability to run on resource-constrained devices. The Nvidia team recently released Llama-3.1-Minitron4B, an excellent small language model based on compression of the Llama 3 model. It utilizes model pruning and distillation technologies to rival larger models in performance, while having efficient training and deployment advantages, bringing new possibilities to AI applications. The editor of Downcodes will take you to have an in-depth understanding of this technological breakthrough.
In an era when technology companies are chasing artificial intelligence on devices, more and more small language models (SLM) are emerging and can run on resource-constrained devices. Recently, Nvidia's research team used cutting-edge model pruning and distillation technology to launch Llama-3.1-Minitron4B, a compressed version of the Llama3 model. This new model is not only comparable in performance to larger models, but also competes with smaller models of the same size, while being more efficient in training and deployment.
Pruning and distillation are two key techniques for creating smaller, more efficient language models. Pruning refers to removing unimportant parts of the model, including "depth pruning" - removing entire layers, and "width pruning" - removing specific elements such as neurons and attention heads. Model distillation, on the other hand, transfers knowledge and capabilities from a large model (i.e., "teacher model") to a smaller, simpler "student model."
There are two main methods of distillation. The first is through "SGD training", which allows the student model to learn the input and response of the teacher model. The second is "classical knowledge distillation". Here, in addition to learning results, the student model also needs Internal activation of the learning teacher model.
In a previous study, Nvidia researchers successfully reduced the Nemotron15B model to an 800 million parameter model through pruning and distillation, and eventually further reduced it to 400 million parameters. This process not only improves performance by 16% on the famous MMLU benchmark, but also requires 40 times less training data than training from scratch.
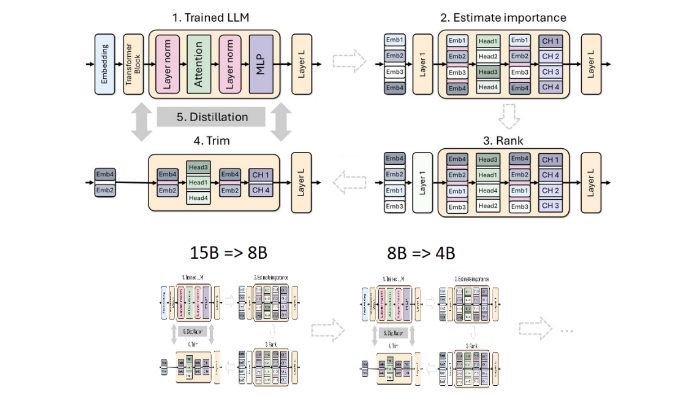
This time, the Nvidia team used the same method to create a 400 million parameter model based on the Llama3.18B model. First, they fine-tuned the unpruned 8B model on a dataset containing 94 billion tokens to cope with the distribution differences between the training data and the distilled dataset. Then, two methods of depth pruning and width pruning were used, and finally two different versions of Llama-3.1-Minitron4B were obtained.
The researchers fine-tuned the pruned model through NeMo-Aligner and evaluated its capabilities in instruction following, role playing, retrieval augmentation generation (RAG), and function calling.
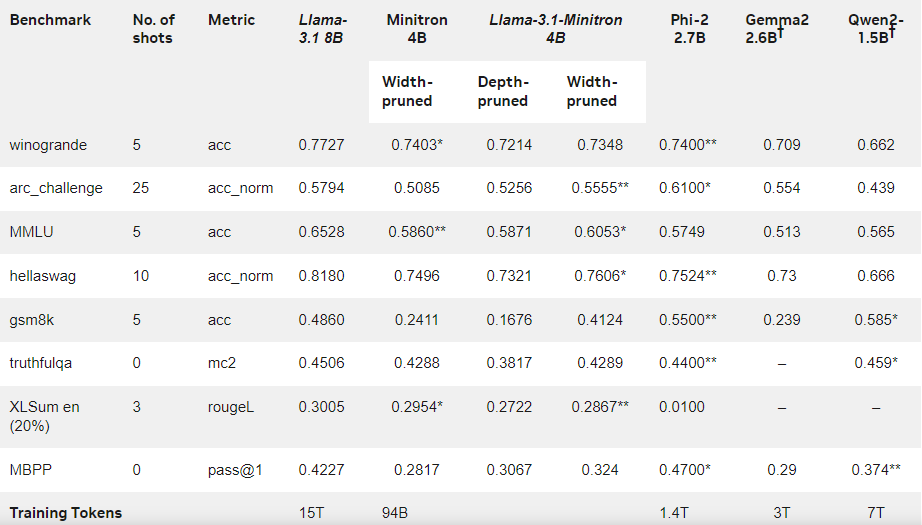
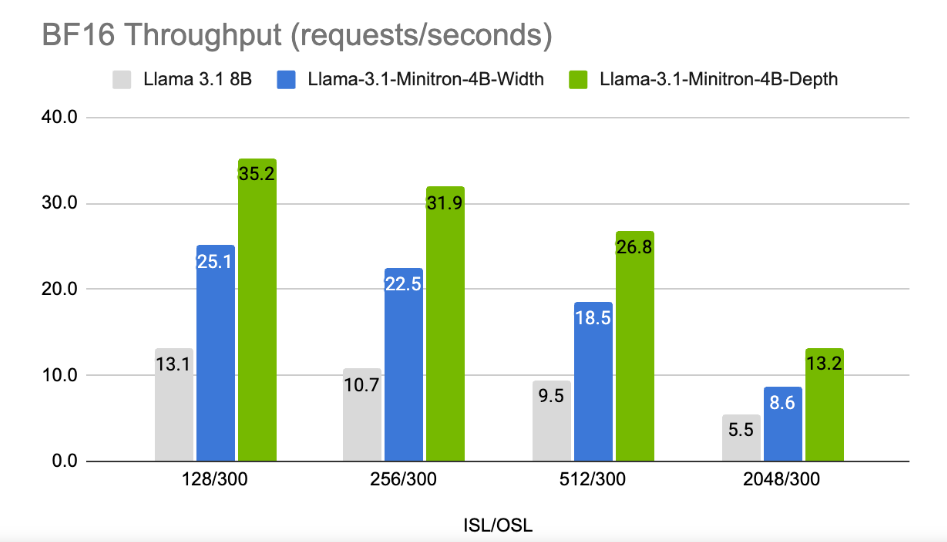
The results show that despite the small amount of training data, the performance of Llama-3.1-Minitron4B is still close to other small models and performs well. The width-pruned version of the model has been released on Hugging Face, allowing commercial use to help more users and developers benefit from its efficiency and excellent performance.
Official blog: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model /
Highlight:
Llama-3.1-Minitron4B is a small language model launched by Nvidia based on pruning and distillation technology, with efficient training and deployment capabilities.
The amount of markers used in the training process of this model is reduced by 40 times compared with training from scratch, but the performance is significantly improved.
? The width pruning version has been released on Hugging Face to facilitate users for commercial use and development.
All in all, the emergence of Llama-3.1-Minitron4B marks a new milestone in the development of small language models. Its efficient performance and convenient deployment method will bring good news to more developers and users and accelerate the popularization and application of AI technology. The editor of Downcodes looks forward to more similar innovations in the future.