In large language model (LLM) training, the checkpoint mechanism is crucial, as it can effectively avoid huge losses caused by training interruptions. However, traditional checkpoint systems often face I/O bottlenecks and are inefficient. To this end, scientists from ByteDance and the University of Hong Kong proposed a new checkpoint system called ByteCheckpoint, which can significantly improve the efficiency of LLM training.
In a digital world dominated by data and algorithms, every step of the growth of artificial intelligence is inseparable from a key element - checkpoint. Imagine that when you are training a large-scale language model that can understand people's minds and answer questions fluently, this model is extremely smart, but it is also a big eater and requires massive computing resources to feed it. During the training process, if there is a sudden power outage or hardware failure, the loss will be huge. At this time, the checkpoint is like a time machine, allowing everything to return to the previous safe state and continue unfinished tasks.
However, the time machine itself also required careful design. Scientists from ByteDance and the University of Hong Kong brought us a new checkpoint system-ByteCheckpoint in the paper "ByteCheckpoint: A Unified Checkpointing System for LLM Development". It is not only a simple backup tool, but also an artifact that can greatly improve the training efficiency of large language models.
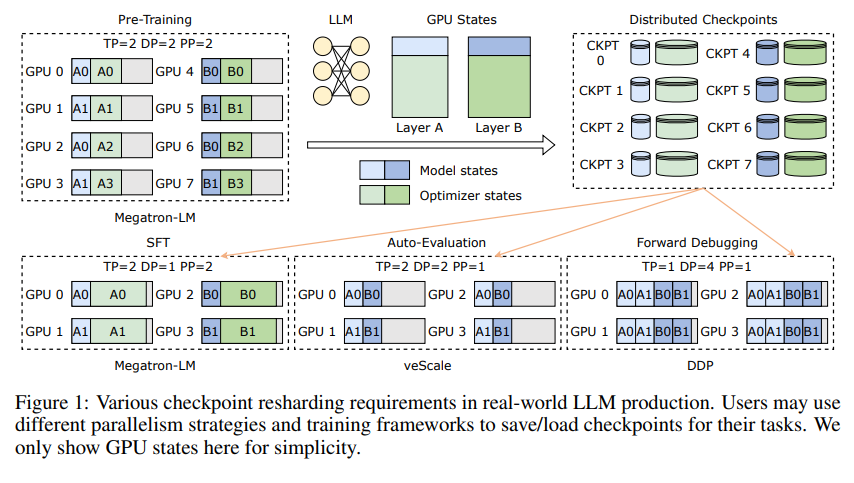
First, we need to understand the challenges faced by large language models (LLMs). The reason why these models are large is that they need to process and remember massive amounts of information, which brings problems such as high training costs, large resource consumption, and weak fault tolerance. Once a malfunction occurs, it may cause a long period of training to be unsatisfactory.
The checkpoint system is like a snapshot of the model, saving the state regularly during the training process, so that even if something goes wrong, it can be quickly restored to the most recent state and reduce losses. However, existing checkpoint systems often suffer from inefficiencies due to I/O (input/output) bottlenecks when processing large models.
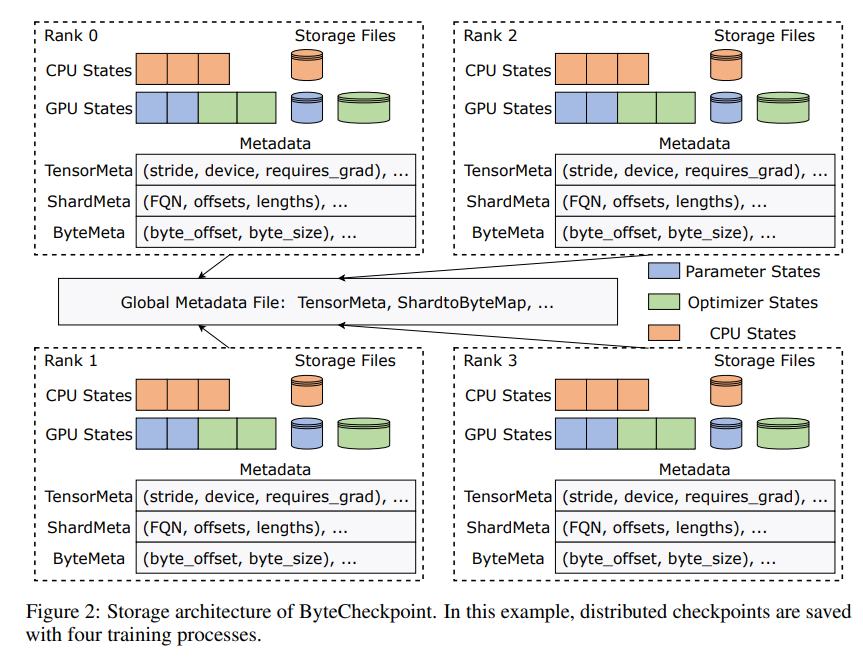
The innovation of ByteCheckpoint lies in the adoption of a novel storage architecture that separates data and metadata and more flexibly handles checkpoints under different parallel configurations and training frameworks. Even better, it supports automatic online checkpoint resharding, which can dynamically adjust checkpoints to adapt to different hardware environments without interrupting training.
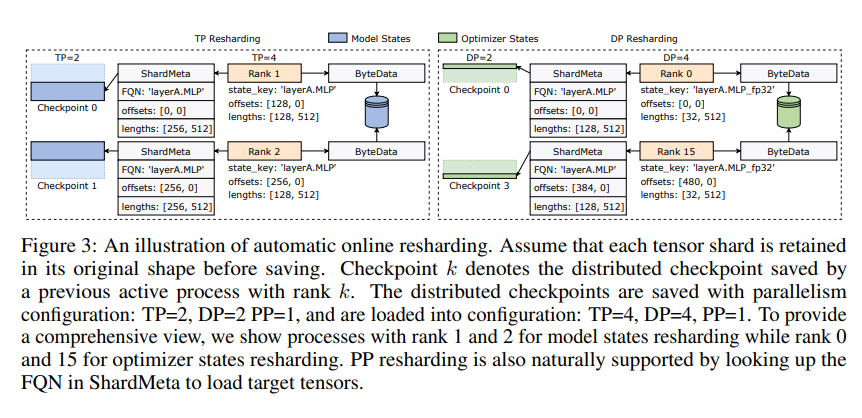
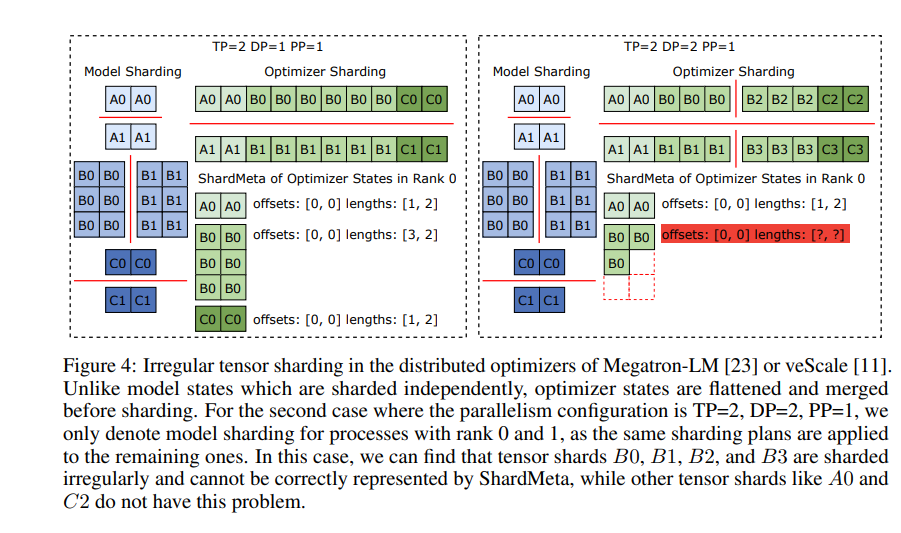
ByteCheckpoint also introduces a key technology - asynchronous tensor merging. This can efficiently handle tensors that are unevenly distributed on different GPUs, ensuring that the integrity and consistency of the model are not affected when checkpointing is resharded.
In order to improve the speed of checkpoint saving and loading, ByteCheckpoint also integrates a series of I/O performance optimization measures, such as sophisticated save/load pipeline, Ping-Pong memory pool, workload balanced save and zero-redundant load, etc., which greatly reduces The waiting time during the training process.
Through experimental verification, compared with traditional methods, ByteCheckpoint's checkpoint saving and loading speeds are increased by dozens or even hundreds of times respectively, significantly improving the training efficiency of large language models.
ByteCheckpoint is not only a checkpoint system, but also a powerful assistant in the training process of large language models. It is the key to more efficient and stable AI training.
Paper address: https://arxiv.org/pdf/2407.20143
The editor of Downcodes summarizes: The emergence of ByteCheckpoint solves the problem of low checkpoint efficiency in LLM training and provides strong technical support for AI development. It is worth paying attention to!