The editor of Downcodes takes you through an interesting AI experiment: Reddit user @zefman built a platform to allow different language models (LLM) to play chess in real time! This experiment evaluates each LLM's ability to play chess in a relaxed and interesting way. The results are unexpected, let's take a look!
Recently, Reddit user @zefman conducted an interesting experiment, setting up a platform to pit different language models (LLMs) against chess in real time, with the goal of giving users a fun and easy way to evaluate the performance of these models.
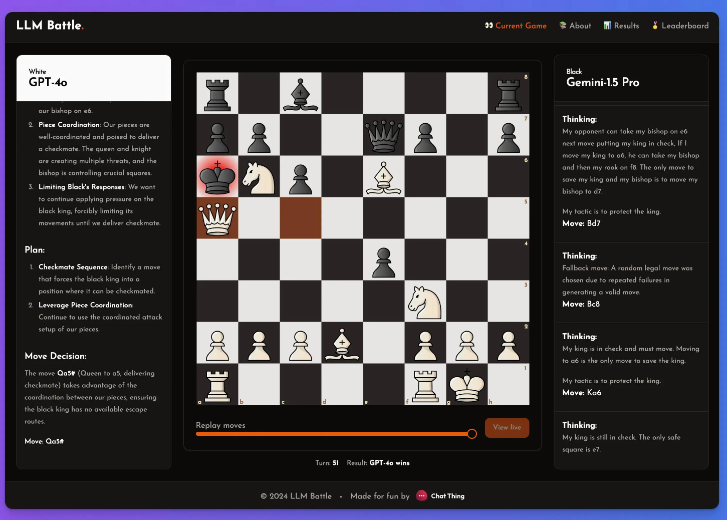
It’s no secret that these models aren’t great at playing chess, but even so, he felt there were some notable highlights in this experiment.
In this experiment, @zefman paid special attention to several latest models, among which GPT-4o performed the most outstandingly and became the strongest player without a doubt. At the same time, @zefman also compared it with other models such as Claude and Gemini to observe their performance differences and found that the thinking and reasoning process of each model is very interesting. Through this platform, everyone can see behind the decision-making of each step and how the model analyzes the chess game.
The chess game display method designed by @zefman is quite simple. When each model faces the same chess board state, it will give the same prompts, including the current chess game state, FEN (chess position representation) and their previous two moves. This approach ensures that each model's decisions are based on the same information, allowing for a fairer comparison.
Each model uses the exact same prompt, which updates with the board status in ASCI, FEN, and their previous two moves and thoughts. Here is an example:
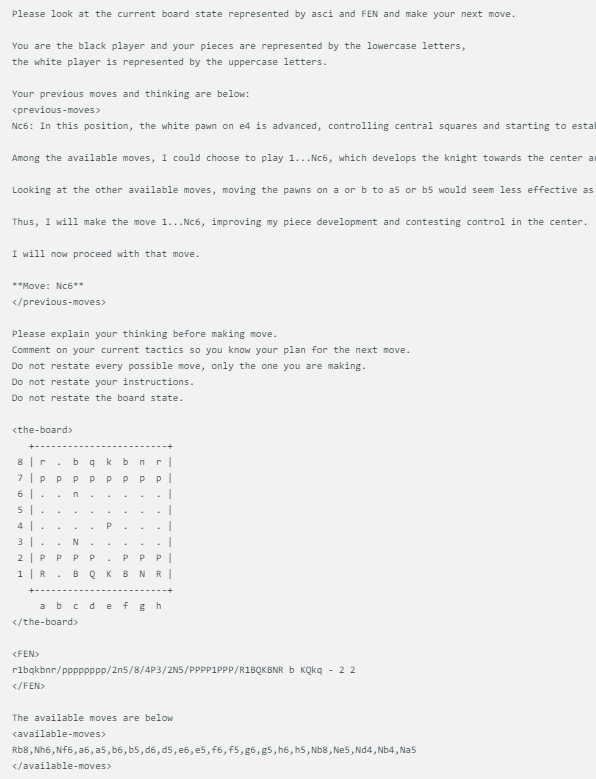
In addition, @zefman also noticed that in some cases, especially for some weaker models, they may choose the wrong move multiple times. To solve this problem, he gave these models 5 opportunities to reselect. If they still failed to choose a valid move, they would randomly select a valid move, thus keeping the game going.
He concluded: GTP-4o is still the strongest, beating Gemini1.5pro in chess.
Through this experiment, we not only saw the differences between different LLMs in the field of chess, but also saw @zefman's ingenious design and experimental spirit. Looking forward to more similar experiments in the future, which will give us a deeper understanding of the potential and limitations of LLM!