The editor of Downcodes brings you the big news of MiniCPM-V2.6! This end-side multi-modal artificial intelligence model with only 8B parameters has achieved SOTA results of models below 20B in the three fields of single image, multi-image and video understanding. It can be called a miracle of small models! It not only has strong performance, but also achieves extremely high operating efficiency and friendliness on end-side devices, bringing new possibilities to end-side AI applications, even comparable to GPT-4V. Let's take a deeper look at the powerful functions and features of MiniCPM-V2.6.
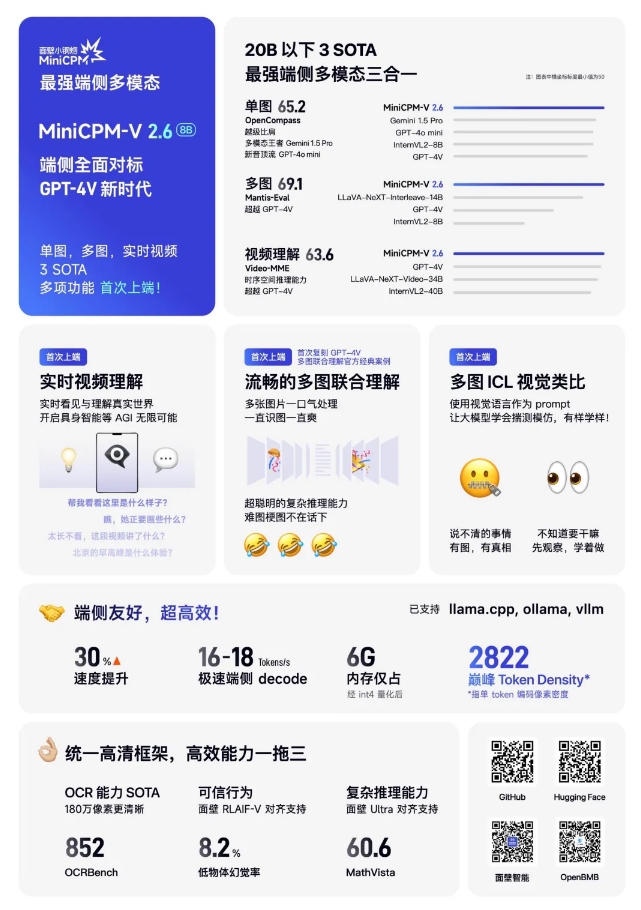
MiniCPM-V2.6's end-side multi-modal artificial intelligence model has only 8B parameters but has achieved three SOTA (State of the Art, the current best level) results of single image, multi-image and video understanding below 20B. The multi-modal capabilities of end-side AI have been significantly improved, and are fully aligned with GPT-4V levels.
The following is a summary of the features:
Model features: MiniCPM-V2.6 achieves comprehensive transcendence of core capabilities such as single image, multi-image and video understanding on the client side, and brings real-time video understanding, multi-image joint understanding and other functions to the client side for the first time, bringing it closer to complex Real world scenarios.
Efficiency and performance: This model is small and large, with extremely high pixel density (Token Density), which is twice as high as the single token encoding pixel density of GPT-4o, and achieves extremely high operating efficiency on end-side devices.
Client-side friendliness: The model requires only 6GB of memory after quantization, and the client-side inference speed is as high as 18 tokens per second, which is 33% faster than the previous generation model, and supports multiple languages and inference frameworks.
Function expansion: MiniCPM-V2.6 uses OCR capabilities to migrate the high-definition image analysis capabilities of single-image scenes to multi-image and video scenes, reducing the number of visual tokens and saving resources.
Reasoning ability: It shows excellent ability in multi-image understanding and complex reasoning tasks, such as the step-by-step instructions for adjusting a bicycle seat and the identification of the grooves behind the memes.
Multi-graph ICL: The model supports contextual few-shot learning, can quickly adapt to tasks in specific fields, and improves output stability.
High-definition visual architecture: Through a unified visual architecture, the OCR capabilities of the model are continued, enabling smooth expansion from single images to multiple images and videos.
Ultra-low hallucination rate: MiniCPM-V2.6 performs well in hallucination evaluation, demonstrating its credibility.
The launch of the MiniCPM-V2.6 model is of great significance to the development of end-side AI. It not only improves multi-modal processing capabilities, but also demonstrates the possibility of realizing high-performance AI on end-side devices with limited resources.
MiniCPM-V2.6 open source address:
GitHub:
https://github.com/OpenBMB/MiniCPM-V
HuggingFace:
https://huggingface.co/openbmb/MiniCPM-V-2_6
llama.cpp, ollama, vllm deployment tutorial address:
https://modelbest.feishu.cn/docx/Duptdntfro2Clfx2DzuczHxAnhc
MiniCPM series open source address:
https://github.com/OpenBMB/MiniCPM
The emergence of MiniCPM-V2.6 has undoubtedly injected a boost into the development of client-side AI technology. Its efficient, powerful performance and convenient open source method will provide valuable resources for more developers and researchers and promote the further innovation and popularization of device-side AI applications. We look forward to the MiniCPM series bringing more surprises in the future!