Meta AI's latest project Llama3 has attracted widespread attention. The editor of Downcodes will give you an in-depth understanding of its core technology and future development direction. Meta AI researcher Thomas Scialom was recently interviewed, sharing the details of the development of Llama3 and providing unique insights into the problems existing in large-scale language model training. He particularly emphasized the important role of synthetic data in Llama3 training and how to effectively use human feedback to improve model performance. This article will explain in detail the training methods, application areas and future development plans of Llama3, presenting readers with a comprehensive and in-depth perspective.
Thomas Scialom, a researcher at Meta AI, recently shared some insights into their latest project, Llama3, in an interview. He bluntly points out that the large amounts of text on the web are of varying quality, and he believes that training on this data is a waste of resources. Therefore, the training process of Llama3 does not rely on any human-written answers, but is entirely based on the synthetic data generated by Llama2.
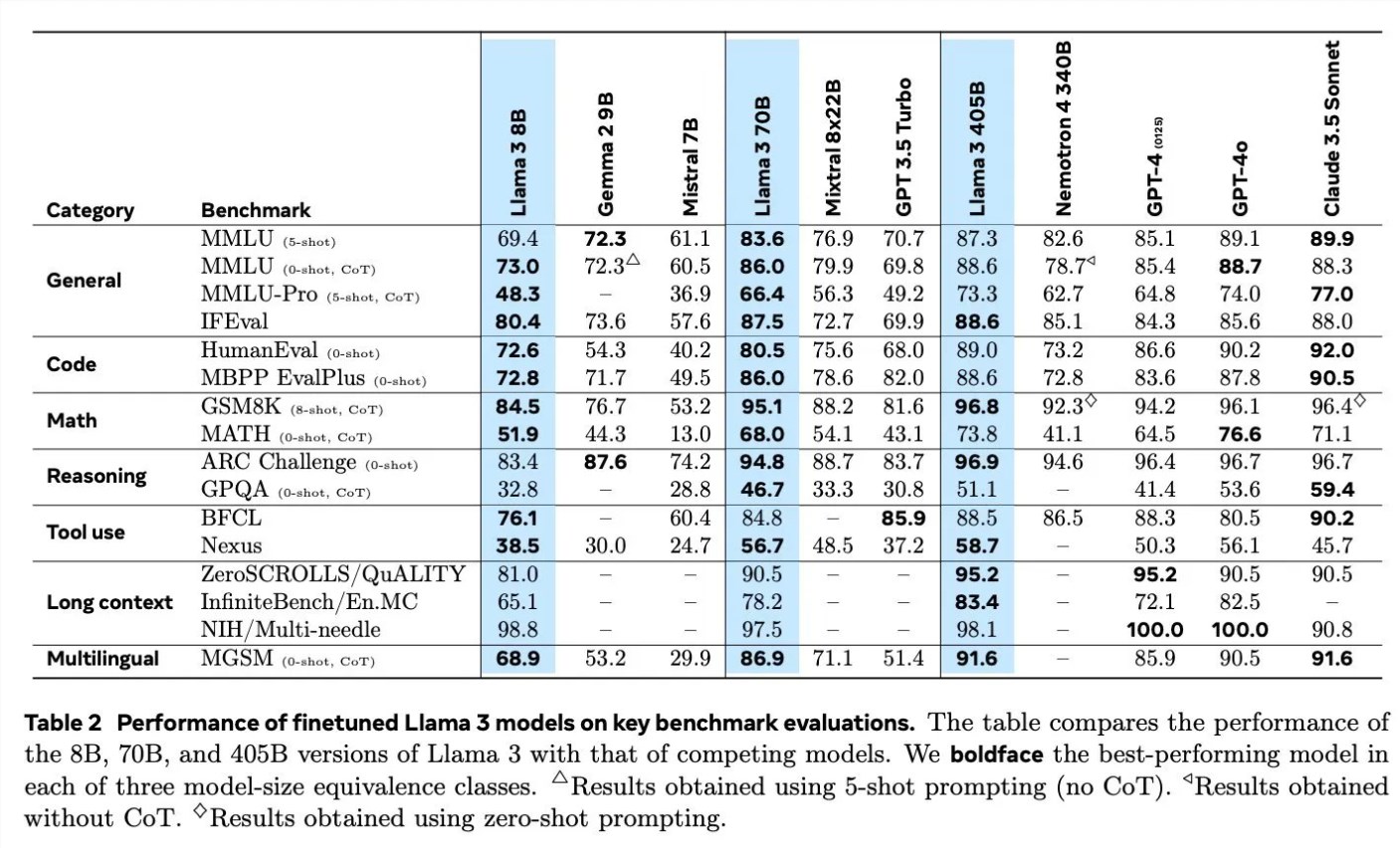
When discussing the training details of Llama3, Scialom detailed the application of synthetic data in different fields. For example, in terms of code generation, they used three different methods to generate synthetic data, including feedback from code execution, translation of programming languages, and back-translation of documentation. In terms of mathematical reasoning, they drew on the “let’s step-by-step” research approach to data generation. In addition, Llama3 continues to be pre-trained with 90% multi-language tokens to collect high-quality human annotations, which is particularly important in multi-language processing.
Long text processing is also a focus of Llama3, and they rely on synthetic data to handle long text question answering, long document summarization, and code base inference. In terms of tool usage, Llama3 was trained on Brave search, Wolfram Alpha and Python interpreters to implement single, nested, parallel and multi-round function calls.
Scialom also mentioned the importance of reinforcement learning with human feedback (RLHF) in Llama3 training. They made extensive use of human preference data to train the model, emphasizing humans' ability to make choices (such as choosing which of two poems to prefer) rather than starting from scratch.
Meta has started the training of Llama4 in June, and Scialom revealed that a main focus of Llama4 will be around the intelligent agent. In addition, he also mentioned a multi-modal version of Llama, which will have more parameters and is planned to be released in the near future.
Scialom’s interview reveals Meta AI’s latest progress and future development directions in the field of artificial intelligence, especially in how to use synthetic data and human feedback to improve model performance.
Through Scialom’s interview, we learned about Llama3’s innovations in data utilization and model training, as well as Meta AI’s continued exploration in the field of large-scale language models. The successful experience of Llama3 provides valuable reference for the development of future artificial intelligence models, and also indicates that artificial intelligence technology will develop in a more accurate and efficient direction. The editor of Downcodes looks forward to the release of Llama4 and multi-modal Llama, and continues to pay attention to Meta AI's breakthrough progress in the field of artificial intelligence.