Meta Company’s big release! Open source its latest large language model Llama 3.1 405B, with a parameter volume of up to 128 billion, and its performance is comparable to GPT-4 in multiple tasks. After a year of careful preparation, from project planning to final review, the Llama 3 series models finally meet the public. This open source not only includes the model itself, but also its optimized pre-training data processing, post-training data quality assurance, and efficient quantification technology to reduce computing requirements and make it easier for developers to use. The editor of Downcodes will explain in detail the improvements and highlights of Llama 3.1 405B.
Last night, Meta announced the open source of its latest large language model Llama3.1 405B. This big news marks that after a year of careful preparation, from project planning to final review, the Llama3 series models have finally met the public.
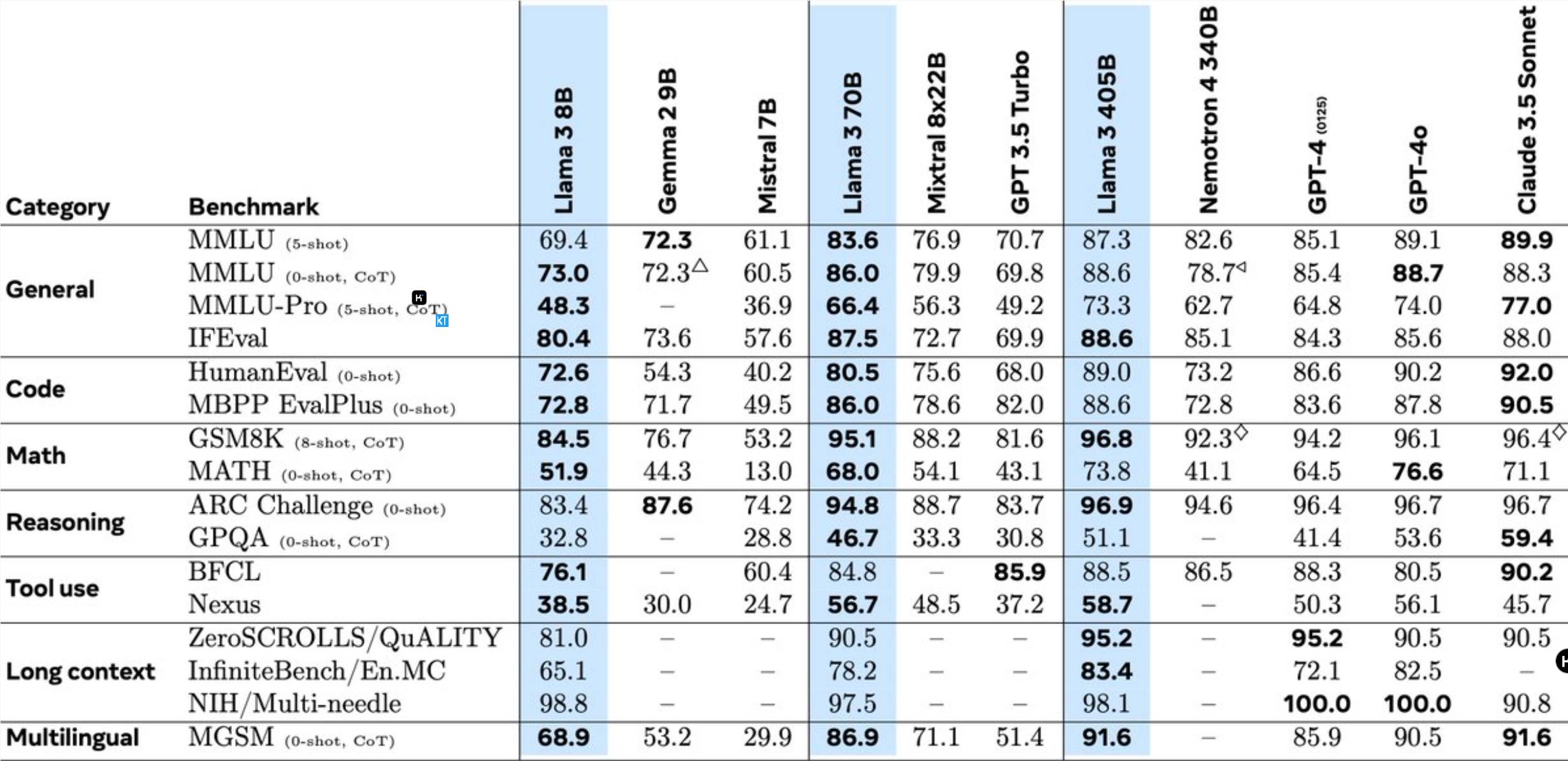
Llama3.1405B is a multilingual tool usage model with 128 billion parameters. After pre-training with a context length of 8K, the model is further trained with a context length of 128K. According to Meta, this model’s performance on multiple tasks is comparable to the industry-leading GPT-4.
Compared with the previous Llama model, Meta has been optimized in many aspects:
Pre-training of the 405B model is a huge challenge, involving 15.6 trillion tokens and 3.8x10^25 floating point operations. To this end, Meta optimized the entire training architecture and used more than 16,000 H100 GPUs.
To support mass production inference of the 405B model, Meta quantized it from 16-bit (BF16) to 8-bit (FP8), significantly reducing computing requirements and enabling a single server node to run the model.
In addition, Meta uses the 405B model to improve the post-training quality of the 70B and 8B models. In the post-training phase, the team refined the chat model through multiple rounds of alignment processes, including supervised fine-tuning (SFT), rejection sampling, and direct preference optimization. It is worth noting that most SFT samples are generated using synthetic data.
Llama3 also integrates image, video and voice functions, using a combined approach to enable the model to recognize images and videos, and support voice interaction. However, these features are still under development and have not yet been officially released.
Meta has also updated its license agreement to allow developers to use the output of the Llama model to improve other models.
Researchers at Meta said: It is extremely exciting to work at the forefront of AI with top talents in the industry and publish research results openly and transparently. We look forward to seeing the innovation that open source models bring, and the potential for future Llama series models!
This open source initiative will undoubtedly bring new opportunities and challenges to the AI field and promote the further development of large language model technology.
The open source of Llama 3.1 405B will greatly promote the advancement of large language model technology and bring more possibilities to the AI field. We look forward to developers creating more amazing applications based on this model!