Kunlun Technology recently announced that two reward models it developed, Skywork-Reward-Gemma-2-27B and Skywork-Reward-Llama-3.1-8B, achieved excellent results on RewardBench, with the 27B model topping the list. This marks that Kunlun Wanwei has made a major breakthrough in the field of artificial intelligence, especially in the research and development of reward models, and provides new technical support for large language model training. Reward models are crucial in reinforcement learning, as they can guide model learning and generate content that is more in line with human preferences. Kunlun Wanwei's model has unique advantages in data selection and model training, which makes it perform well in aspects such as dialogue and security, and especially shows strong capabilities when processing difficult samples.
Kunlun Wanwei Technology Co., Ltd. recently announced that two new reward models developed by the company, Skywork-Reward-Gemma-2-27B and Skywork-Reward-Llama-3.1-8B, performed well on RewardBench, the internationally authoritative reward model evaluation benchmark. Among them, the Skywork-Reward-Gemma-2-27B model won the top spot and was highly recognized by RewardBench officials.
The reward model occupies a core position in reinforcement learning, evaluating the performance of the agent in different states, and providing reward signals to guide the agent's learning process, so that it can make the optimal choice in a specific environment. In the training of large language models, the reward model plays a particularly critical role, helping the model to more accurately understand and generate content that conforms to human preferences.
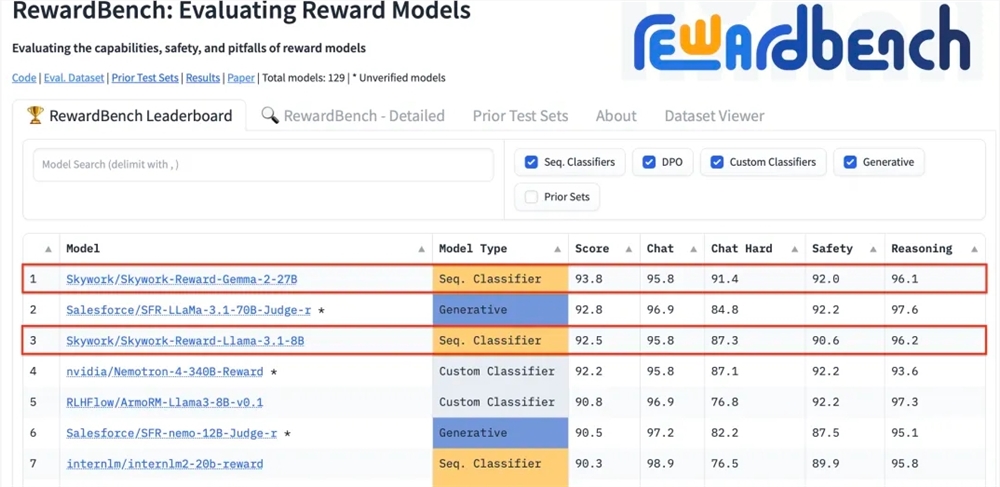
RewardBench is a benchmark list that specifically evaluates the effectiveness of reward models in large language models. It comprehensively evaluates models through multiple tasks, including dialogue, reasoning, and security. The test data set of this list consists of triples consisting of prompt words, selected responses, and rejected responses. It is used to test whether the reward model can correctly rank the selected responses among the rejected responses given the prompt words. before rejecting the response.
Kunlun Wanwei’s Skywork-Reward model is developed through carefully selected partially ordered data sets and relatively small base models. Compared with existing reward models, its partially ordered data only comes from public data on the Internet and is filtered through specific filters. Strategies to obtain high-quality preference data sets. The data covers a wide range of topics, including security, math and code, and is manually verified to ensure the objectivity of the data and the significance of reward gaps.
After testing, Kunlun Wanwei’s reward model showed excellent performance in fields such as dialogue and security. Especially when facing difficult samples, only the Skywork-Reward-Gemma-2-27B model gave correct predictions. This achievement marks Kunlun Wanwei’s technical strength and innovation capabilities in the global AI field, and also provides new possibilities for the development and application of AI technology.
27B model address:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
8B model address:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
Kunlun Wanwei's excellent performance on RewardBench demonstrates its leading technology and innovation capabilities in the field of artificial intelligence. It also provides new directions and possibilities for the future development of large language models. We look forward to its bringing more breakthroughs in the future. Results.