The Mamba team's research has made a breakthrough. They successfully "distilled" the large Transformer model Llama into a more efficient Mamba model. This research cleverly combines technologies such as progressive distillation, supervised fine-tuning and directional preference optimization, and designs a new inference decoding algorithm based on the unique structure of the Mamba model, which significantly improves the model's inference speed without ensuring performance. A substantial improvement in efficiency has been achieved without loss. This research not only reduces the cost of large-scale model training, but also provides new ideas for future model optimization, which has important academic significance and application value.
Recently, the Mamba team's research is eye-catching: researchers from universities such as Cornell and Princeton have successfully "distilled" Llama, a large Transformer model, into Mamba, and designed a new inference decoding algorithm that significantly Improved model inference speed.
The researchers' goal is to turn Llama into a Mamba. Why do this? Because training a large model from scratch is expensive, and Mamba has received widespread attention since its inception, but few teams actually train large-scale Mamba models themselves. Although there are some reputable variants on the market, such as AI21's Jamba and NVIDIA's Hybrid Mamba2, there is a wealth of knowledge embedded in the many successful Transformer models. If we could lock in this knowledge and fine-tune the Transformer to Mamba, the problem would be solved.
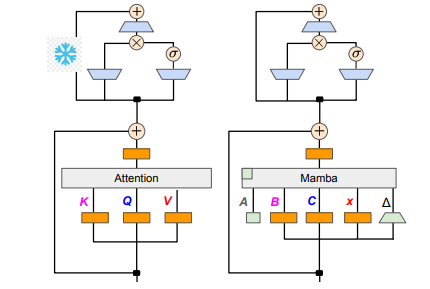
The research team successfully achieved this goal by combining various methods such as progressive distillation, supervised fine-tuning and directional preference optimization. It is worth noting that speed is also crucial without compromising performance. Mamba has obvious advantages in long sequence reasoning, and Transformer also has reasoning acceleration solutions, such as speculative decoding. Since Mamba's unique structure cannot directly apply these solutions, the researchers specially designed a new algorithm and combined it with hardware features to implement Mamba-based speculative decoding.
Finally, the researchers successfully converted Zephyr-7B and Llama-38B into linear RNN models, and their performance was comparable to the standard model before distillation. The entire training process only uses 20B tokens, and the results are comparable to the Mamba7B model trained from scratch using 1.2T tokens and the NVIDIA Hybrid Mamba2 model trained with 3.5T tokens.
In terms of technical details, linear RNN and linear attention are connected, so researchers can directly reuse the projection matrix in the attention mechanism and complete model construction through parameter initialization. In addition, the research team froze the parameters of the MLP layer in Transformer, gradually replaced the attention head with a linear RNN layer (ie Mamba), and processed group query attention for shared keys and values across heads.
During the distillation process, a strategy of gradually replacing the attention layers is adopted. Supervised fine-tuning includes two main methods: one is based on word-level KL divergence, and the other is sequence-level knowledge distillation. In the tuning phase of user preferences, the team used the Direct Preference Optimization (DPO) method to ensure that the model can better meet user expectations when generating content by comparing it with the output of the teacher model.
Next, the researchers began to apply Transformer's speculative decoding to the Mamba model. Speculative decoding can be simply understood as using a small model to generate multiple outputs, and then using a large model to verify these outputs. Small models run quickly and can quickly generate multiple output vectors, while large models are responsible for evaluating the accuracy of these outputs, thereby increasing overall inference speed.
In order to implement this process, the researchers designed a set of algorithms that use a small model to generate K draft outputs each time, and then the large model returns the final output and cache of intermediate states through verification. This method has achieved good results on GPU. Mamba2.8B achieved 1.5 times of inference acceleration, and the acceptance rate reached 60%. Although the effects vary on GPUs of different architectures, the research team further optimized by integrating kernels and adjusting implementation methods, and finally achieved the ideal acceleration effect.
In the experimental phase, the researchers used Zephyr-7B and Llama-3Instruct8B to conduct three-stage distillation training. In the end, it only took 3 to 4 days to run on an 8-card 80G A100 to successfully reproduce the research results. This research not only shows the transformation between Mamba and Llama, but also provides new ideas for improving the inference speed and performance of future models.
Paper address: https://arxiv.org/pdf/2408.15237
This research provides valuable experience and technical solutions for improving the efficiency of large-scale language models. The results are expected to be applied to more fields and promote the further development of artificial intelligence technology. The provision of the paper address facilitates readers to have a deeper understanding of the research details.