Google DeepMind teamed up with a number of universities to develop a new method called the Generative Reward Model (GenRM), which aims to solve the problem of insufficient accuracy and reliability of generative AI in reasoning tasks. Although existing generative AI models are widely used in fields such as natural language processing, they often confidently output erroneous information, especially in fields that require extremely high accuracy, which limits their application scope. The innovation of GenRM is to redefine the verification process as a next word prediction task, integrate the text generation capabilities of large language models (LLMs) into the verification process, and support chain reasoning, thereby achieving more comprehensive and systematic verification.
Recently, Google DeepMind's research team teamed up with a number of universities to propose a new method called the Generative Reward Model (GenRM), which aims to improve the accuracy and reliability of generative AI in reasoning tasks.
Generative AI is widely used in many fields such as natural language processing. It mainly generates coherent text by predicting the next word of a series of words. However, these models sometimes confidently output incorrect information, which is a big problem especially in fields where accuracy is critical, such as education, finance, and healthcare.
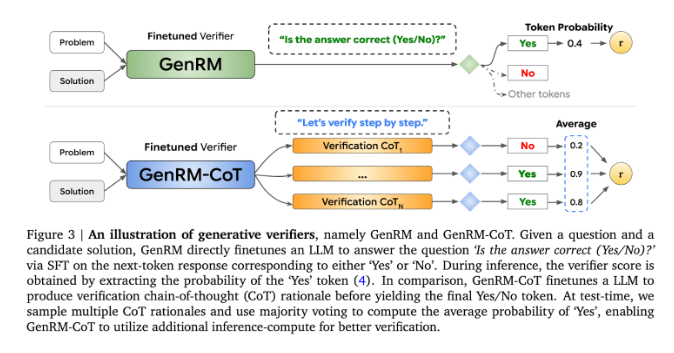
Currently, researchers have tried different solutions to the difficulties encountered by generative AI models in output accuracy. Among them, discriminative reward models (RMs) are used to determine whether potential answers are correct based on scores, but this method fails to fully utilize the generative capabilities of large language models (LLMs). Another commonly used method is "LLM as judge", but this method is often not as effective as a professional verifier when solving complex reasoning tasks.
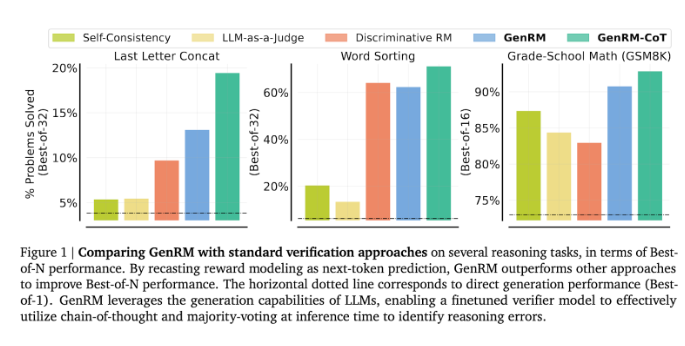
The innovation of GenRM is to redefine the verification process as a next word prediction task. This means that, unlike traditional discriminative reward models, GenRM incorporates the text generation capabilities of LLMs into the verification process, allowing the model to simultaneously generate and evaluate potential solutions. In addition, GenRM also supports chained reasoning (CoT), that is, the model can generate intermediate reasoning steps before reaching the final conclusion, thus making the verification process more comprehensive and systematic.
By combining generation and validation, the GenRM approach adopts a unified training strategy that enables the model to simultaneously improve generation and validation capabilities during training. In real applications, the model generates intermediate inference steps that are used to verify the final answer.
The researchers found that the GenRM model performed well on several rigorous tests, such as significantly improved accuracy on preschool math and algorithmic problem-solving tasks. Compared with the discriminative reward model and the LLM as judge method, GenRM's problem-solving success rate increased by 16% to 64%.
For example, when verifying the output of the Gemini1.0Pro model, GenRM increased the problem-solving success rate from 73% to 92.8%.
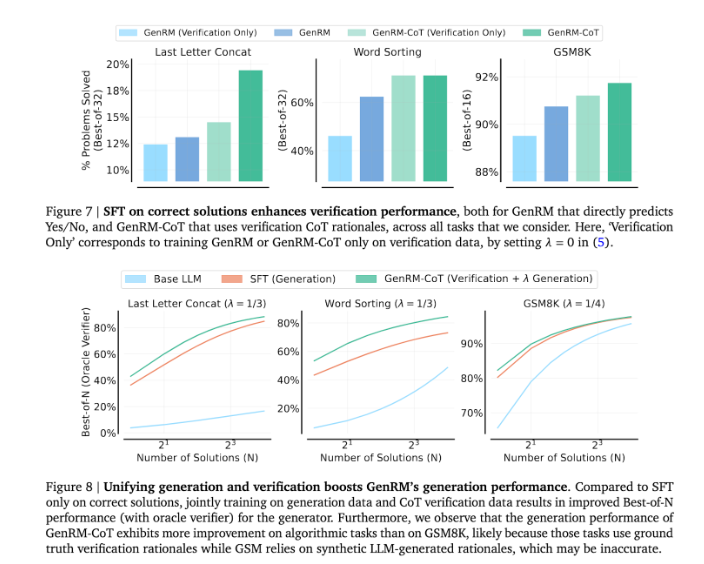
The introduction of the GenRM method marks a major advance in the field of generative AI, significantly improving the accuracy and trustworthiness of AI-generated solutions by unifying solution generation and verification into one process.
All in all, the emergence of GenRM provides new ideas for improving the reliability of generative AI. Its significant improvement in solving complex reasoning problems indicates the possibility of generative AI being applied in more fields, which is worthy of further research and exploration.