Database query optimizers rely heavily on cardinality estimation (CE) to predict query result sizes and thus select the best execution plan. Inaccurate cardinality estimates can cause query performance to degrade. Existing CE methods have limitations, especially when dealing with complex queries. Although the learning CE model is more accurate, its training cost is high and it lacks systematic benchmark evaluation.
In modern relational databases, cardinality estimation (CE) plays a crucial role. Simply put, cardinality estimation is a prediction of how many intermediate results a database query will return. This prediction has a huge impact on the query optimizer's execution plan choices, such as deciding the join order, whether to use indexes, and the choice of the best join method. If the cardinality estimate is inaccurate, the execution plan may be greatly compromised, resulting in extremely slow query speeds and seriously affecting the overall performance of the database.
However, existing cardinality estimation methods have many limitations. Traditional CE technology relies on some simplifying assumptions and often accurately predicts the cardinality of complex queries, especially when multiple tables and conditions are involved. Although learning CE models can provide better accuracy, their application is limited by long training times, the need for large data sets, and the lack of systematic benchmark evaluation.
To fill this gap, Google's research team launched CardBench, a new benchmarking framework. CardBench includes more than 20 real-world databases and thousands of queries, far exceeding previous benchmarks. This enables researchers to systematically evaluate and compare different learning CE models under various conditions. The benchmark supports three main settings: instance-based models, zero-shot models, and fine-tuned models, suitable for different training needs.
CardBench is also designed to include a set of tools that can calculate necessary statistics, generate real SQL queries, and create annotated query graphs for training CE models.
The benchmark provides two sets of training data: one for a single table query with multiple filter predicates, and one for a binary join query involving two tables. The benchmark includes 9125 single-table queries and 8454 binary join queries on one of the smaller datasets, ensuring a robust and challenging environment for model evaluation. Training data labels from Google BigQuery required 7 CPU years of query execution time, highlighting the significant computational investment in creating this benchmark. By providing these datasets and tools, CardBench lowers the barrier for researchers to develop and test new CE models.
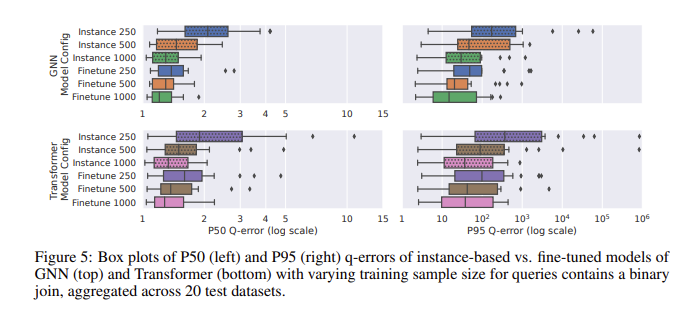
In the performance evaluation using CardBench, the fine-tuned model performed particularly well. While zero-shot models struggle to improve accuracy when applied to unseen datasets, especially in complex queries involving joins, fine-tuned models can achieve comparable accuracy to instance-based methods with much less training data . For example, a fine-tuned graph neural network (GNN) model achieved a median q-error of 1.32 and a 95th percentile q-error of 120 on binary join queries, significantly better than the zero-shot model. The results show that even with 500 queries, fine-tuning the pre-trained model can significantly improve its performance. This makes them suitable for practical applications where training data may be limited.
The introduction of CardBench brings new hope to the field of learned cardinality estimation, allowing researchers to more effectively evaluate and improve models, thereby driving further development in this important field.
Paper entrance: https://arxiv.org/abs/2408.16170
In short, CardBench provides a comprehensive and powerful benchmarking framework, provides important tools and resources for the research and development of learning cardinality estimation models, and promotes the advancement of database query optimization technology. The excellent performance of its fine-tuned model is particularly worthy of attention, providing new possibilities for practical application scenarios.