Recently, a study published in Cureus magazine showed that OpenAI’s GPT-4 model successfully passed the Japanese National Physical Therapy Examination without additional training. The researchers tested GPT-4 using 1,000 questions covering memory, comprehension, application, analysis and evaluation. The results showed that it had an accuracy rate of 73.4% and passed all five test parts. This research raises concerns about the potential of GPT-4 for medical applications, while also revealing its limitations in dealing with specific types of problems, such as practical problems and those containing picture tables.
A recent peer-reviewed study published in the journal Cureus shows that OpenAI’s GPT-4 language model successfully passed the Japanese National Physical Therapy Examination without any additional training.
The researchers fed 1,000 questions into GPT-4, covering areas such as memory, comprehension, application, analysis and evaluation. The results showed that GPT-4 answered 73.4% of the questions correctly overall, passing all five test parts. However, research has also revealed the limitations of AI in some areas.

GPT-4 performed well on general problems, with an accuracy of 80.1%, but only 46.6% on practical problems. Likewise, it does far better at handling text-only questions (80.5% correct) than questions with pictures and tables (35.4% correct). This finding is consistent with previous research on the limitations of GPT-4 visual understanding.
It is worth noting that question difficulty and text length have little impact on the performance of GPT-4. Although the model was primarily trained using English data, it also performed well when handling Japanese input.
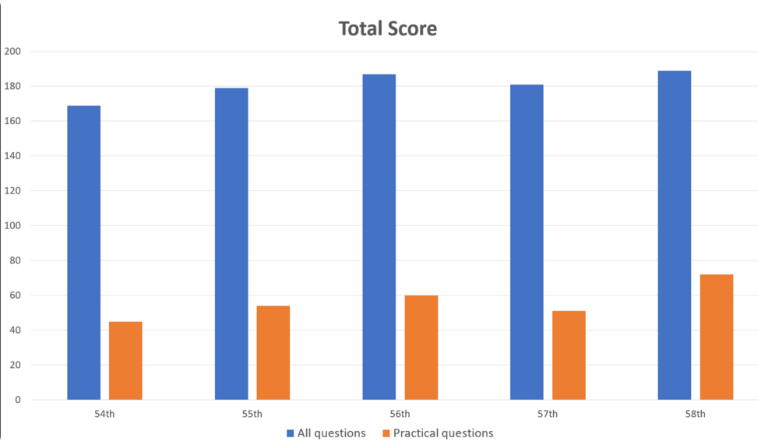
The researchers noted that while this study demonstrates the potential of GPT-4 in clinical rehabilitation and medical education, it should be viewed with caution. They emphasized that GPT-4 does not answer all questions correctly and that future evaluations of new versions and the model's capabilities in written and reasoning tests will be needed.
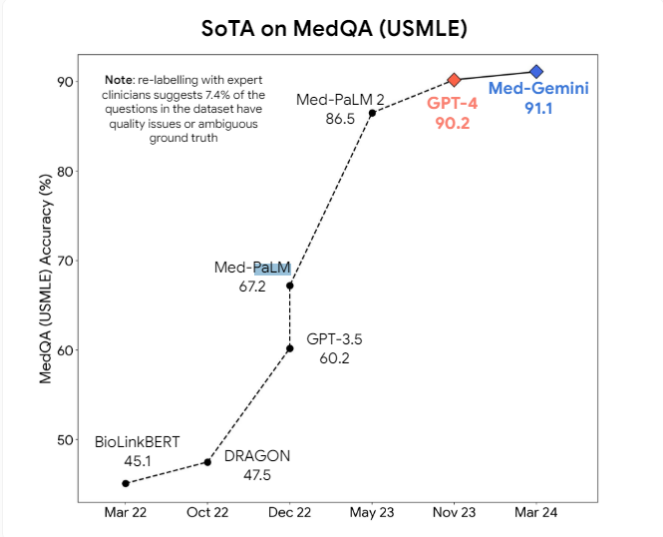
In addition, the researchers proposed that multi-modal models like GPT-4v may bring further improvements in visual understanding. Currently, professional medical AI models such as Google's Med-PaLM2 and Med-Gemini, as well as Meta's medical model based on Llama3, are actively being developed, aiming to surpass general-purpose models in medical tasks.
However, experts believe it may be a long time before medical AI models are widely used in practice. The error space of current models remains too large in medical settings, and significant advances in inference capabilities are required to safely integrate these models into daily medical practice.
Although this study demonstrates the potential of GPT-4 in the medical field, it also reminds us that AI technology still needs to be continuously improved before it can truly be applied to complex medical scenarios. In the future, multi-modal models and more powerful reasoning capabilities will be key improvements to ensure the safety and reliability of AI in medical care.