The field of artificial intelligence has been committed to allowing machines to understand the complex physical world. Breakthroughs in this area are crucial to many fields. Recently, research teams from Renmin University of China, Beijing University of Posts and Telecommunications, Shanghai AI Lab and other institutions have developed Ref-AVS technology, providing a new solution to this problem. Ref-AVS technology integrates multiple modal information such as video object segmentation, video object reference segmentation and audio-visual segmentation through a clever multi-modal fusion method, enabling the AI system to more accurately understand natural language instructions and perform complex audio-visual tasks. The precise positioning of target objects in the scene breaks through the previous limitations of AI in multi-modal understanding.
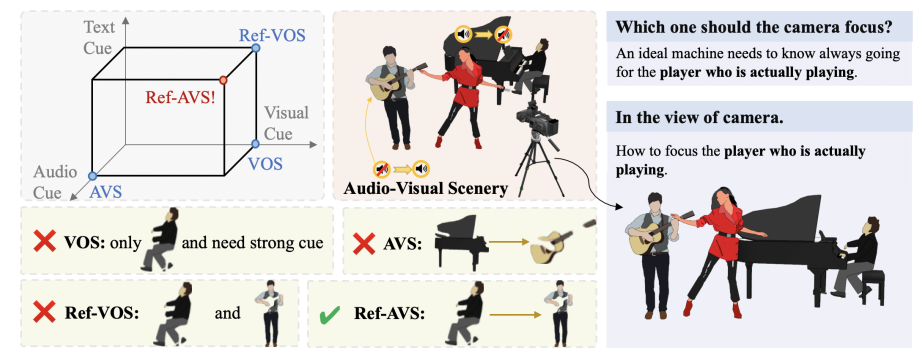
In the field of artificial intelligence, getting machines to understand the complex physical world like humans has always been a major challenge. Recently, a research team composed of Renmin University of China, Beijing University of Posts and Telecommunications, Shanghai AI Lab and other institutions proposed a breakthrough technology - Ref-AVS, which brings new hope to solve this problem.
The core of Ref-AVS technology lies in its unique multi-modal fusion method. It cleverly integrates multiple modal information such as video object segmentation (VOS), video object reference segmentation (Ref-VOS), and audio-visual segmentation (AVS). This innovative fusion enables the AI system to not only process objects that are making sounds, but also to identify non-sounding but equally important objects in the scene. This breakthrough allows AI to more accurately understand instructions described by users through natural language and accurately locate specific objects in complex audio-visual scenes.
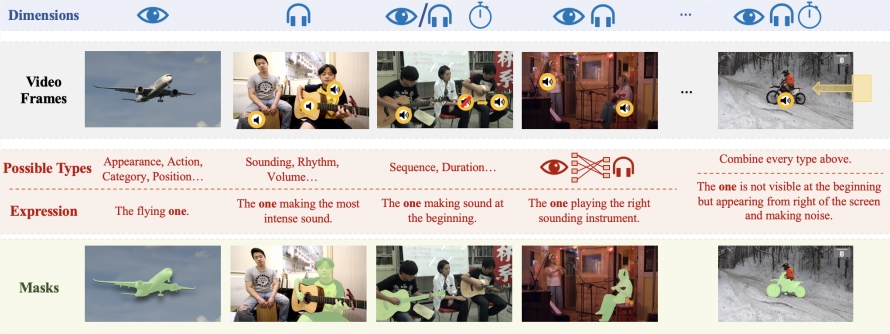
To support the research and verification of Ref-AVS technology, the research team constructed a large-scale data set called Ref-AVS Bench. This dataset contains 40,020 video frames covering 6,888 objects and 20,261 referring expressions. Each video frame is accompanied by corresponding audio and pixel-level detailed annotation. This rich and diverse dataset provides a solid foundation for multimodal research and opens up new possibilities for future research in related fields.
In a series of rigorous quantitative and qualitative experiments, Ref-AVS technology demonstrated excellent performance. Especially on the Seen subset, Ref-AVS outperforms other existing methods, fully proving its powerful segmentation capabilities. What’s more noteworthy is that the test results on the Unseen and Null subsets further verify the excellent generalization ability and robustness of Ref-AVS technology to null references, which are crucial for practical application scenarios.
The success of Ref-AVS technology has not only attracted widespread attention in academia, but also opened up new paths for future practical applications. We can foresee that this technology will play an important role in many fields such as video analysis, medical image processing, autonomous driving and robot navigation. For example, in the medical field, Ref-AVS may help doctors interpret complex medical images more accurately; in the field of autonomous driving, it may improve the vehicle's perception of the surrounding environment; in robotics, it may allow robots to better understand and carry out human verbal instructions.
The results of this research have been presented at ECCV2024, and relevant papers and project information have also been made public, providing valuable learning and exploration resources for researchers and developers around the world interested in this field. This open and sharing attitude not only reflects the academic spirit of the Chinese scientific research team, but will also promote the rapid development of the entire AI field.
The emergence of Ref-AVS technology marks an important step in multi-modal understanding of artificial intelligence. It not only demonstrates the innovative capabilities of the Chinese scientific research team in the field of AI, but also paints a more intelligent and natural blueprint for the future of human-computer interaction. As this technology continues to be improved and applied, we have reason to expect that future AI systems will be able to better understand and adapt to the complex world of humans and bring revolutionary changes to all walks of life.
Paper address: https://arxiv.org/abs/2407.10957
Project home page:
https://gewu-lab.github.io/Ref-AVS/
In short, the advent of Ref-AVS technology has brought new breakthroughs to the field of multi-modal understanding of artificial intelligence. Its powerful performance and broad application prospects are worth looking forward to. This technology will promote the development of artificial intelligence towards smarter and more natural interactions, bringing more convenience to human society.