Recently, MLCommons released the results of MLPerf inference v4.1. Multiple AI inference chip manufacturers participated, and the competition was fierce. For the first time, this competition includes chips from AMD, Google, UntetherAI and other manufacturers, as well as Nvidia’s latest Blackwell chips. In addition to performance comparison, energy efficiency has also become an important competitive dimension. Various manufacturers have shown their special skills and demonstrated their respective advantages in different benchmark tests, bringing new vitality to the AI inference chip market.
In the field of artificial intelligence training, Nvidia's graphics cards are almost unrivaled, but when it comes to AI inference, competitors seem to be starting to catch up, especially in terms of energy efficiency. Despite the strong performance of Nvidia's latest Blackwell chips, it's unclear whether it can maintain its lead. Today, ML Commons announced the results of the latest AI inference competition - MLPerf Inference v4.1. For the first time, AMD's Instinct accelerator, Google's Trillium accelerator, Canadian startup UntetherAI's chips and Nvidia's Blackwell chips are participating. Two other companies, Cerebras and FuriosaAI, have launched new inference chips but have not submitted MLPerf for testing.
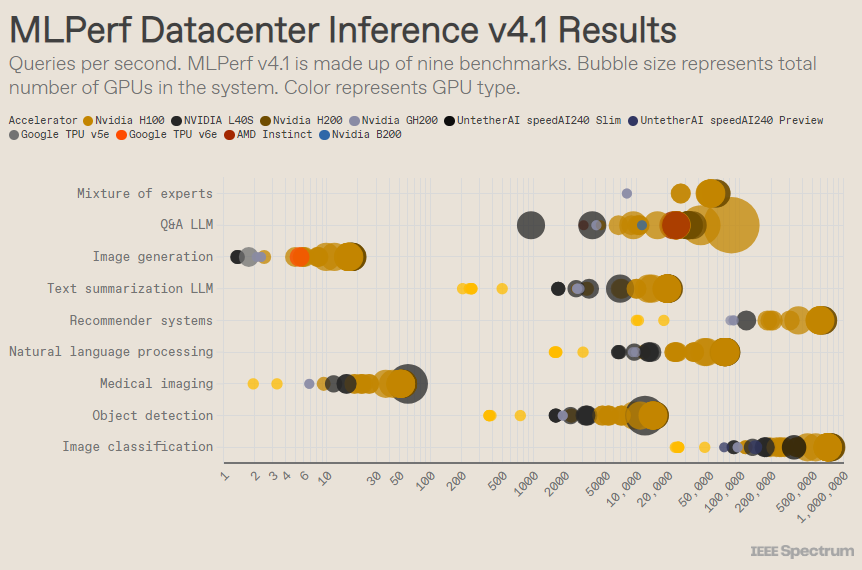
MLPerf is structured like an Olympic competition, with multiple events and sub-events. The “Data Center Enclosure” category had the most entries. Unlike the open category, the closed category requires entrants to perform inference directly on a given model without significantly modifying the software. The data center category primarily tests the ability to batch process requests, while the edge category focuses on reducing latency.
There are 9 different benchmarks under each category, covering a variety of AI tasks, including popular image generation (think Midjourney) and question answering with large language models (such as ChatGPT), as well as some important but lesser-known tasks, Such as image classification, object detection and recommendation engines.
This round adds a new benchmark - the "expert hybrid model". This is an increasingly popular method of language model deployment that splits a language model into multiple independent small models, each fine-tuned for a specific task, such as daily conversation, solving mathematical problems, or programming assistance. By assigning each query to its corresponding small model, resource utilization is reduced, lowering costs and increasing throughput, said Miroslav Hodak, senior technical staff member at AMD.

In the popular "data center closed" benchmark, the winning ones are still submissions based on the Nvidia H200 GPU and GH200 superchip, which combine GPU and CPU in one package. However, a closer look at the results reveals some interesting details. Some competitors used multiple accelerators, while others used just one. The results are even more confusing if we normalize the queries per second by the number of accelerators and retain the best-performing submissions for each accelerator type. It should be noted that this approach ignores the role of the CPU and interconnect.
On a per-accelerator basis, Nvidia's Blackwell excelled on large language model question-and-answer tasks, delivering a 2.5x speedup over previous chip iterations, the only benchmark it submitted to. Untether AI's speedAI240 preview chip performed almost as well as the H200 on the only image recognition task it was submitted to. Google's Trillium performs slightly lower than H100 and H200 on image generation tasks, while AMD's Instinct performs equivalent to H100 on large language model question and answer tasks.
Part of Blackwell's success stems from its ability to run large language models using 4-bit floating point precision. Nvidia and competitors have been working to reduce the number of bits represented in transformation models such as ChatGPT to speed up calculations. Nvidia introduced 8-bit math in the H100, and this submission is the first demonstration of 4-bit math in the MLPerf benchmark.
The biggest challenge with working with such low-precision numbers is maintaining accuracy, said Dave Salvator, Nvidia's director of product marketing. To maintain high accuracy in MLPerf submissions, the Nvidia team has made numerous innovations in the software.
In addition, Blackwell's memory bandwidth nearly doubles to 8 terabytes per second, compared to the H200's 4.8 terabytes.
Nvidia's Blackwell submission uses a single chip, but Salvator says it's designed for networking and scaling, and will perform best when combined with Nvidia's NVLink interconnect. Blackwell GPUs support up to 18 NVLink 100GB per second connections, with a total bandwidth of 1.8 terabytes per second, nearly twice the interconnect bandwidth of the H100.
Salvator believes that as large language models continue to scale, even inference will require multi-GPU platforms to meet the demand, and Blackwell is designed for this situation. “Havel is a platform,” Salvator said.
Nvidia submitted its Blackwell chip system to the Preview subcategory, meaning it's not yet available, but is expected to be available before the next MLPerf release, which is about six months from now.
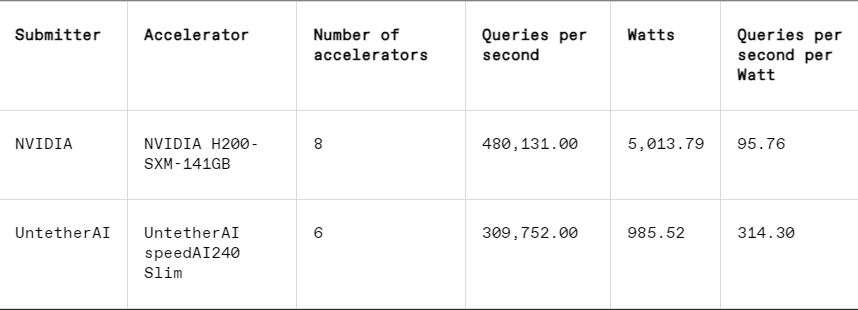
In each benchmark, MLPerf also includes an energy measurement section that systematically tests each system's actual power consumption while performing tasks. This round's main competition (Data Center Enclosed Energy Category) had only two submitters, Nvidia and Untether AI. While Nvidia participated in all benchmarks, Untether only submitted results on the image recognition task.
Untether AI excels in this regard, successfully achieving excellent energy efficiency. Their chip uses an approach called "in-memory computing." Untether AI's chip is made up of a bank of memory cells with a small processor sitting nearby. Each processor works in parallel, processing data simultaneously with adjacent memory units, significantly reducing the time and energy spent transferring model data between memory and computing cores.
“We found that when running AI workloads, 90% of the energy consumption is moving data from DRAM to cache processing units,” said Robert Beachler, vice president of product at Untether AI. “So what Untether does is move the computation closer to the data, rather than moving the data to the compute unit.”
This approach works particularly well in another subcategory of MLPerf: edge closure. This category focuses on more practical use cases, such as machine inspection in factories, guided vision robots, and autonomous vehicles—applications that have stringent requirements for energy efficiency and fast processing, Beachler explained.
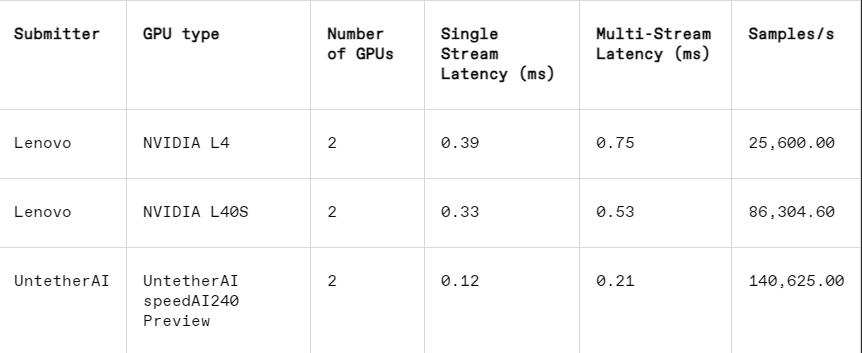
In the image recognition task, the latency performance of Untether AI's speedAI240 preview chip is 2.8 times faster than Nvidia's L40S, and the throughput (number of samples per second) is also increased by 1.6 times. The startup also submitted power consumption results in this category, but Nvidia's competitors did not, making direct comparisons difficult. However, Untether AI's speedAI240 preview chip has a nominal power consumption of 150 watts, while Nvidia's L40S is 350 watts, showing a 2.3x advantage in power consumption and better latency performance.
Although Cerebras and Furiosa did not participate in MLPerf, they also released new chips respectively. Cerebras unveiled its inference service at the IEEE Hot Chips conference at Stanford University. Sunny Valley, Calif.-based Cerebras manufactures giant chips that are as large as silicon wafers allow, thus avoiding interconnections between chips and greatly increasing the memory bandwidth of the device. They are mainly used to train giant neural networks. network. Now, they have upgraded their latest computer, CS3, to support inference.
Although Cerebras did not submit an MLPerf, the company claims that its platform outperforms the H100 by 7x and the competing Groq chip by 2x in the number of LLM tokens generated per second. “Today, we are in the dial-up era of generative AI,” said Andrew Feldman, CEO and co-founder of Cerebras. "This is all because there is a memory bandwidth bottleneck. Whether it's Nvidia's H100 or AMD's MI300 or TPU, they all use the same external memory, resulting in the same limitations. We break that barrier because we do it at the wafer level design."
At the Hot Chips conference, Furiosa from Seoul also demonstrated its second-generation chip RNGD (pronounced "rebel"). Furiosa's new chip features its Tensor Contraction Processor (TCP) architecture. In AI workloads, the basic mathematical function is matrix multiplication, often implemented in hardware as a primitive. However, the size and shape of the matrix, i.e. the wider tensor, can vary significantly. RNGD implements this more general tensor multiplication as a primitive. “During inference, batch sizes vary greatly, so it’s critical to take full advantage of the inherent parallelism and data reuse of a given tensor shape,” June Paik, founder and CEO of Furiosa, said at Hot Chips.
Although Furiosa doesn't have MLPerf, they compared the RNGD chip to MLPerf's LLM summary benchmark in internal testing, and the results were comparable to Nvidia's L40S chip, but only consumed 185 watts compared to the L40S's 320 watts. Paik said performance will improve with further software optimizations.
IBM also announced the launch of its new Spyre chip, which is designed for enterprises to generate AI workloads and is expected to be available in the first quarter of 2025.
Clearly, the AI inference chip market will be bustling for the foreseeable future.
Reference: https://spectrum.ieee.org/new-inference-chips
All in all, the results of MLPerf v4.1 show that the AI inference chip market competition is becoming increasingly fierce. Although Nvidia still maintains the lead, the rise of manufacturers such as AMD, Google and Untether AI cannot be ignored. In the future, energy efficiency will become a key competitive factor, and new technologies such as in-memory computing will also play an important role. The technological innovations of various manufacturers will continue to promote the improvement of AI reasoning capabilities and provide strong impetus for the popularization and development of AI applications.