The ModelScope community has open sourced an upgraded version of its domestic open source Sora video generation model CogVideoX - CogVideoX-5B, which is a text-to-video generation model based on a large-scale DiT model. Compared with the previous CogVideoX-2B, the new model has significantly improved video quality and visual effects. CogVideoX-5B utilizes 3D causal variational autoencoder (3D causal VAE) and expert Transformer technology, and uses 3D-RoPE as the position encoding and 3D full attention mechanism for spatio-temporal joint modeling. It also uses progressive training technology. Able to generate longer, higher quality, more motion-featured videos.
Compared with the previous CogVideoX-2B, the new model has significantly improved the quality and visual effects of video generation.
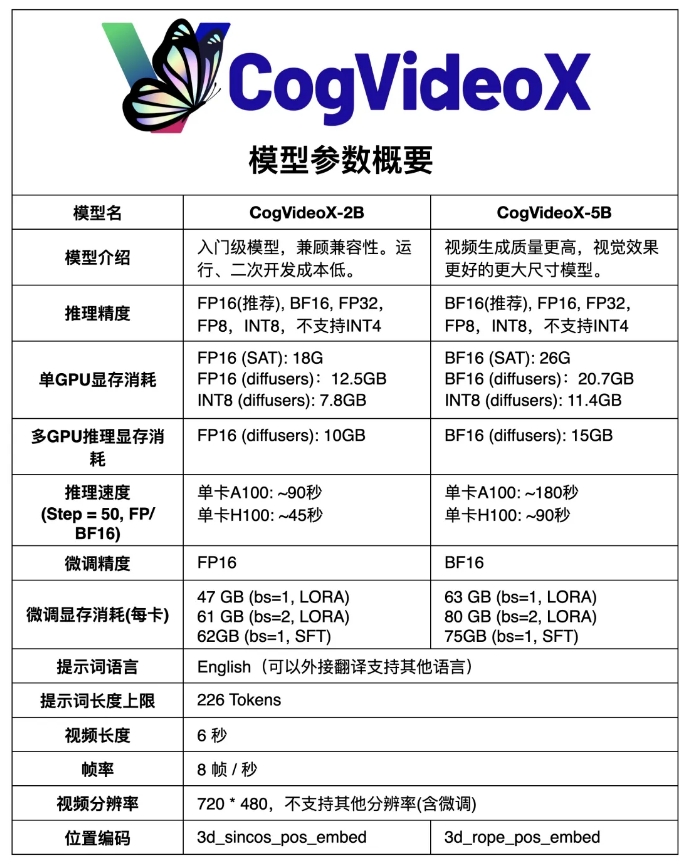
CogVideoX-5B is based on a large-scale DiT (diffusion transformer) model, specially designed for text-to-video generation tasks. The model adopts 3D causal variational autoencoder (3D causal VAE) and expert Transformer technology, combines text and video embeddings, uses 3D-RoPE as position encoding, and utilizes 3D full attention mechanism for spatio-temporal joint modeling.
In addition, the model adopts progressive training technology and is able to generate coherent and long-term high-quality videos with significant motion features.
Model link:
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
The open source of CogVideoX-5B has brought new technological breakthroughs and development opportunities to the field of domestic AI video generation, and also provided powerful tools and resources for researchers and developers. It is believed that more innovative applications based on CogVideoX-5B will appear in the future, promoting the continuous progress of AI video generation technology. The easy access to the model also lowers the threshold for research and application, promoting wider dissemination and application of technology.