In recent years, the performance of large language models (LLM) has attracted much attention. This article introduces an exciting research. The research uses the search strategy cleverly to significantly improve the performance of small LLM, and even make it comparable to large models in certain tasks. This research challenges the concept of traditional "bigger models and better", provides new ideas and directions for the future development of LLM, and also provides more possibilities for researchers and developers with limited resources. It reveals the huge potential of search strategies in improving model reasoning capabilities and triggers in -depth thinking about the relationship between computing resources and model parameters.
Recently, a new study has been exciting and proves that large language models (LLM) can significantly improve performance through search function. In particular, the LLAMA3.1 model with a parameter volume of only 800 million passed through 100 searches, and it was not comparable to the GPT-4O in Python code.
This idea seems to remind people of the pioneer of learning, Rich Sutton's classic blog post "The Bitter Lesson" in 2019. He mentioned that with the improvement of computing power, we need to recognize the power of general methods. In particular, the two methods of "search" and "learning" seem to be an excellent choice that can continue to expand.
Although Sutton emphasizes the importance of learning, that is, greater models can usually learn more knowledge, but we often ignore the potential of search in the process of reasoning. Recently, researchers from Stanford, Oxford and DeepMind found that increasing the number of repeated sampling times during the reasoning stage can significantly improve the performance of models in the fields of mathematics, reasoning and code generation.
After being inspired by these studies, the two engineers decided to perform experiments. They found that using 100 small LLAMA models for search can surpass and even tie GPT-4O in Python programming tasks. They use vivid metaphors to describe: "In the past, a Malaysian Malaysia could achieve some ability. Now, only 100 ducklings can complete the same thing."
In order to achieve higher performance, they used the VLLM library to conduct batch reasoning and run on 10 A100-40GB GPUs. The output speed reached an amazing 40K tokens / second. The author chose the benchmark test of Humaneval because it can run the code generated by running test evaluation, which is more objective and accurate.
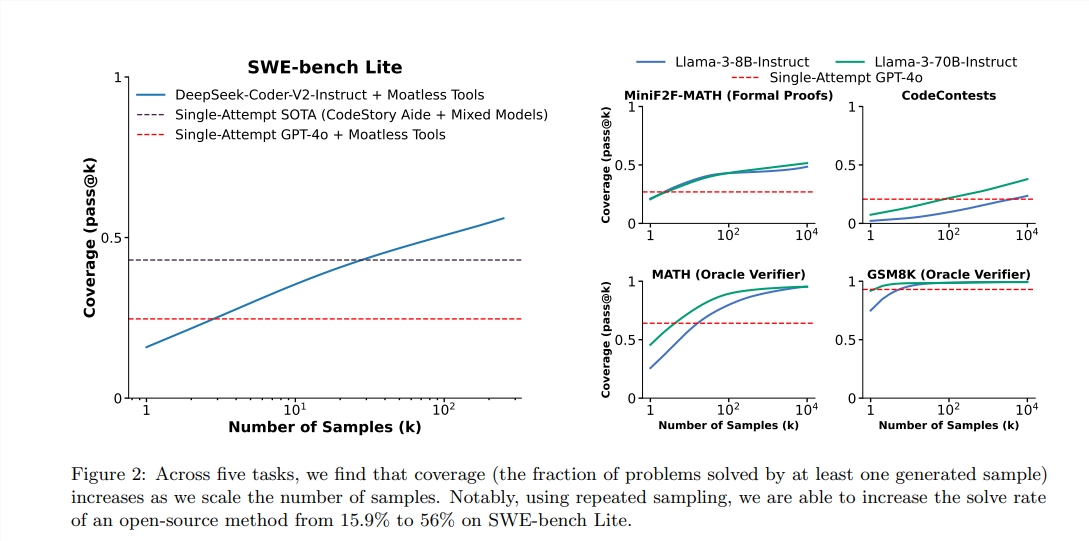
According to the report, the PASS@1 score of GPT-4O is 90.2%in the zero sample reasoning. Through the above methods, the PASS@K score of LLAMA3.18B has also improved significantly. When the number of repeated sampling is 100, LLAMA's score reached 90.5%; when the number of repeated sampling increased to 1,000, the results were further increased to 95.1%, which was significantly better than GPT-4O.
It is worth mentioning that although this experiment is not a strict reproduction of the original research, it emphasizes that when the search method enhances the reasoning stage, the smaller model can also surpass the possibility of large models within the foreseeable range.
The search is strong because it can "transparently" expand with the increase in calculation and transfer resources from memory to calculation, thereby achieving the balance of resources. Recently, DeepMind has made important progress in the field of mathematics, proving the power of search.
However, the success of search first needs to conduct high -quality assessment of the results. The DeepMind model has achieved effective supervision by converting mathematical problems in natural language to form a formal expression. In other areas, open NLP tasks such as "Summary Email" are much more difficult to conduct effective search.
This study shows that the performance improvement of generating models in specific fields is related to its evaluation and search capabilities, and future research can explore how to improve these capabilities through a repeated digital environment.
Thesis address: https: //arxiv.org/pdf/2407.21787
All in all, this research provides a new perspective for the performance improvement of large language models. Through searching strategies rather than simply pursuing larger model parameters, it can achieve unexpected results. In the future, how to effectively combine learning and search strategies will be an important direction for LLM development. The linked linked of this study has also been provided, and interested readers can further understand it.