The rise of the Transformer architecture has revolutionized the field of natural language processing, but its high computational cost has become a bottleneck when processing long texts. In response to this problem, this article introduces a new method called Tree Attention, which effectively reduces the self-attention computational complexity of the long context Transformer model through tree reduction, and makes full use of the power of modern GPU clusters. The network topology greatly improves computing efficiency.
In this era of information explosion, artificial intelligence is like bright stars, lighting up the night sky of human wisdom. Among these stars, the Transformer architecture is undoubtedly the most dazzling one. With the self-attention mechanism as its core, it leads a new era of natural language processing. However, even the brightest stars have corners that are hard to reach. For long-context Transformer models, the high resource consumption of self-attention calculation becomes a problem. Imagine that you are trying to get AI to understand an article that is tens of thousands of words long. Each word has to be compared with every other word in the article. The amount of calculation is undoubtedly huge.
In order to solve this problem, a group of scientists from Zyphra and EleutherAI proposed a new method called Tree Attention.
Self-attention, as the core of the Transformer model, its computational complexity increases quadratically as the sequence length increases. This becomes an insurmountable obstacle when dealing with long texts, especially for large language models (LLMs).
The birth of Tree Attention is like planting trees that can perform efficient calculations in this computational forest. It decomposes the calculation of self-attention into multiple parallel tasks through tree reduction. Each task is like a leaf on the tree, which together form a complete tree.
What’s even more amazing is that the proposers of Tree Attention also derived the energy function of self-attention, which not only provides a Bayesian explanation for self-attention, but also closely connects it with energy models such as the Hopfield network stand up.
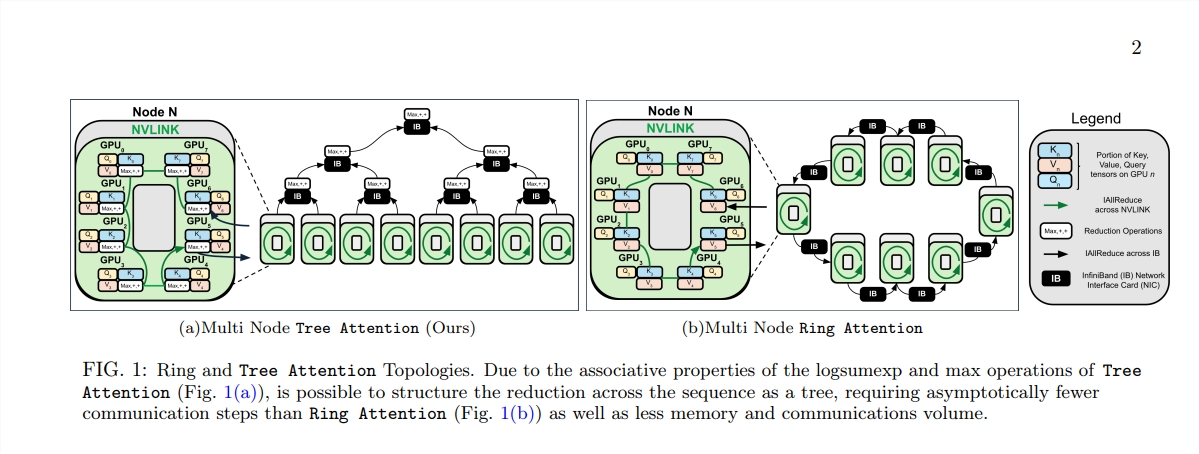
Tree Attention also takes special consideration of the network topology of modern GPU clusters and reduces cross-node communication requirements by intelligently utilizing high-bandwidth connections within the cluster, thereby improving computing efficiency.
Through a series of experiments, the scientists verified the performance of Tree Attention under different sequence lengths and number of GPUs. Results show that Tree Attention is up to 8 times faster than existing Ring Attention methods when decoding on multiple GPUs, while significantly reducing communication volume and peak memory usage.
The proposal of Tree Attention not only provides an efficient solution for the calculation of long-context attention models, but also provides a new perspective for us to understand the internal mechanism of the Transformer model. As AI technology continues to advance, we have reason to believe that Tree Attention will play an important role in future AI research and applications.
Paper address: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
The emergence of Tree Attention provides an efficient and innovative solution to solve the computational bottleneck of long text processing. It has far-reaching significance for the understanding and future development of the Transformer model. This method not only achieves significant improvements in performance, but more importantly, provides new ideas and directions for subsequent research, which is worthy of in-depth study and discussion.