Andrej Karpathy, an authority in the field of AI, recently questioned reinforcement learning based on human feedback (RLHF), believing that it is not the only way to achieve true human-level AI, which has triggered widespread concern and heated discussions in the industry. He believes that RLHF is more of a stopgap measure than the ultimate solution, and took AlphaGo as an example to compare the differences in problem solving between real reinforcement learning and RLHF. Karpathy’s views undoubtedly provide a new perspective on current AI research directions and also bring new challenges to future AI development.
Recently, Andrej Karpathy, a well-known researcher in the AI industry, put forward a controversial point of view. He believes that the currently widely praised reinforcement learning based on human feedback (RLHF) technology may not be the only way to achieve true human-level problem-solving capabilities. This statement undoubtedly dropped a heavy bomb on the current field of AI research.
RLHF was once regarded as a key factor in the success of large-scale language models (LLM) such as ChatGPT, and was hailed as the secret weapon that gives AI understanding, obedience, and natural interaction capabilities. In the traditional AI training process, RLHF is usually used as the last link after pre-training and supervised fine-tuning (SFT). However, Karpathy compared RLHF to a bottleneck and a stopgap measure, believing that it is far from the ultimate solution for AI evolution.
Karpathy cleverly compared RLHF to DeepMind’s AlphaGo. AlphaGo used what he calls true RL (reinforcement learning) technology, and by constantly playing against itself and maximizing its winning rate, it eventually surpassed top human chess players without human intervention. This approach achieves superhuman performance levels by optimizing neural networks to learn directly from game outcomes.
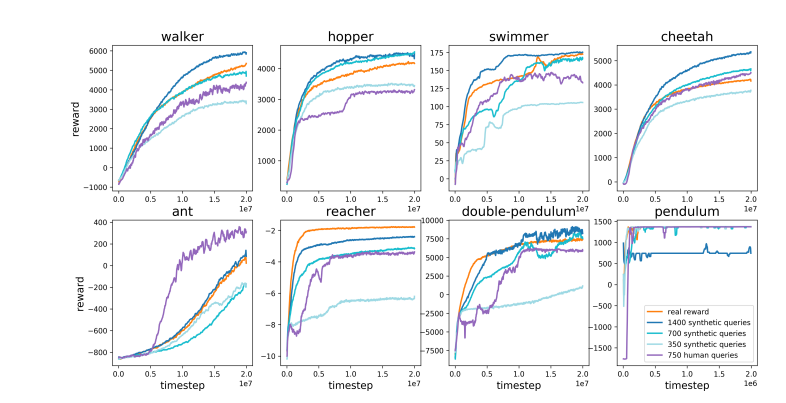
In contrast, Karpathy believes that RLHF is more about imitating human preferences than actually solving problems. He imagined that if AlphaGo adopts the RLHF method, human evaluators will need to compare a large number of game states and choose preferences. This process may require up to 100,000 comparisons to train a reward model that mimics human atmosphere checking. However, such atmosphere-based judgments can produce misleading results in a rigorous game like Go.
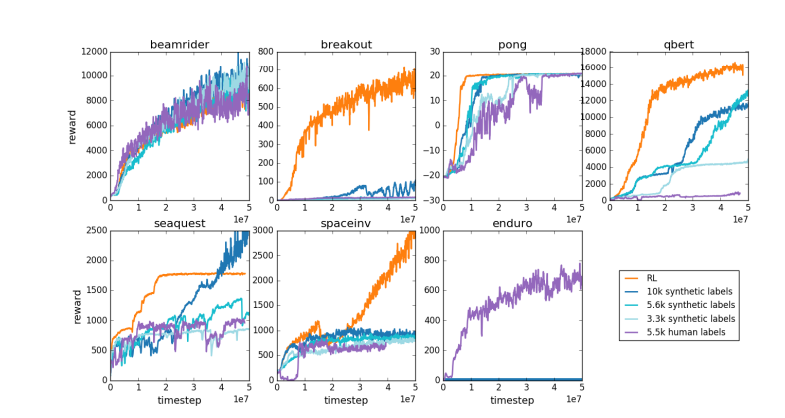
For the same reason, the current LLM reward model works similarly—it tends to rank high answers that human evaluators statistically seem to prefer. This is more of an agent catering to superficial human preferences than a reflection of true problem-solving ability. Even more worryingly, models may quickly learn how to exploit this reward function rather than actually improve their capabilities.
Karpathy points out that while reinforcement learning performs well in closed environments like Go, true reinforcement learning remains elusive for open language tasks. This is mainly because it is difficult to define clear goals and reward mechanisms in open tasks. How to give objective rewards for tasks such as summarizing an article, answering a vague question about pip installation, telling a joke, or rewriting Java code into Python? Karpathy asks this insightful question, and going in this direction is not a principle It's impossible, but it's not easy either, and it requires some creative thinking.

Still, Karpathy believes that if this difficult problem can be solved, language models have the potential to truly match or even surpass human problem-solving abilities. This view coincides with a recent paper published by Google DeepMind, which pointed out that openness is the foundation of artificial general intelligence (AGI).
As one of several senior AI experts who left OpenAI this year, Karpathy is currently working on his own educational AI startup. His remarks undoubtedly injected a new dimension of thinking into the field of AI research and provided valuable insights into the future direction of AI development.
Karpathy's views sparked widespread discussion in the industry. Supporters believe that he reveals a key issue in current AI research, which is how to make AI truly capable of solving complex problems rather than just imitating human behavior. Opponents worry that premature abandonment of RLHF may lead to a deviation in the direction of AI development.
Paper address: https://arxiv.org/pdf/1706.03741
Karpathy's views triggered in-depth discussions about the future development direction of AI. His doubts about RLHF prompted researchers to re-examine current AI training methods and explore more effective paths, with the ultimate goal of achieving true artificial intelligence.