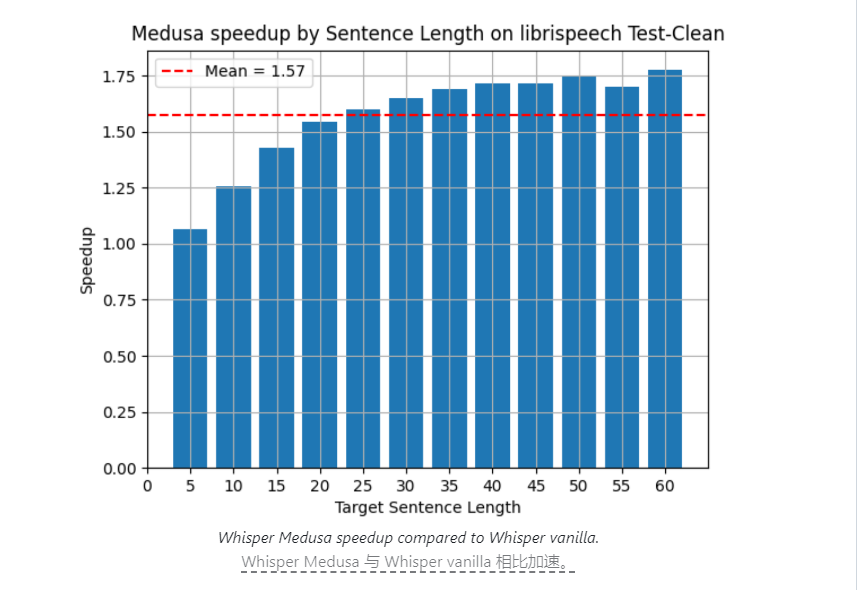
Israeli artificial intelligence company aiOla recently released an open source speech recognition model called Whisper Medusa. The model has achieved a significant breakthrough in speed, and its processing speed is 50% faster than OpenAI's Whisper model. This breakthrough has attracted widespread attention in the industry, and its core lies in improved architectural design and innovative training methods. Whisper Medusa is not only faster, but also maintains a high level of accuracy and stability, bringing new possibilities to the development of speech recognition technology.
Israeli artificial intelligence company aiOla has recently made a major breakthrough in the field of speech recognition technology and launched an open source speech recognition model called Whisper Medusa. This new model's processing speed is 50% faster than OpenAI's Whisper model, which has attracted widespread attention in the industry.
The core innovation of Whisper Medusa is its improved architectural design. aiOla has modified Whisper's original architecture and introduced a multi-head attention mechanism. This mechanism allows the model to simultaneously focus on information from different representation subspaces by using multiple attention heads in parallel. This innovation enables the model to predict ten tokens at a time instead of the traditional one token at a time, significantly improving speech prediction speed and generation runtime.
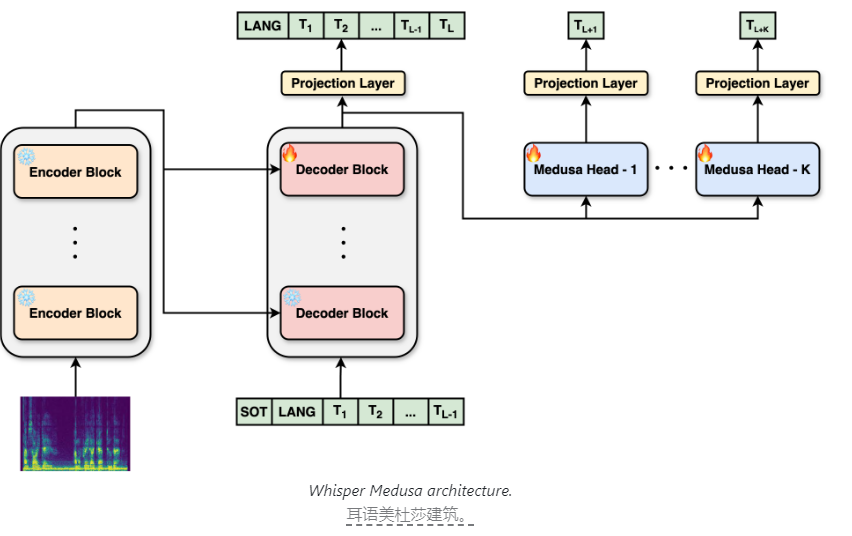
It's worth noting that Whisper Medusa increases speed without sacrificing performance. This is due to the fact that its backbone system is still based on Whisper, ensuring the accuracy and stability of the model. During the training process, aiOla uses a machine learning method called weak supervision. Specifically, they froze the main components of Whisper and used the audio transcriptions generated by the model as labels to train additional token prediction modules. This innovative training method further improves the model’s learning efficiency and accuracy.
The open source release of Whisper Medusa could have a profound impact on the development of speech recognition technology. Not only does it provide researchers and developers with a powerful new tool, it may also drive the development of faster and more efficient speech processing applications. In the context of the growing demand for voice interaction, this technological breakthrough will undoubtedly open up new possibilities for the application of artificial intelligence in the field of speech recognition.
With the launch of Whisper Medusa, we can expect to see more innovative applications based on this model, from smart assistants to real-time translation to voice control systems, all of which may gain significant performance improvements as a result. This progress not only marks an important milestone in speech recognition technology, but also paints a more efficient and smooth blueprint for the future of interaction between artificial intelligence and humans.
Project address: https://github.com/aiola-lab/whisper-medusa
huggingface: https://huggingface.co/aiola/whisper-medusa-v1
Whisper Medusa's open source and high performance indicate that speech recognition technology will usher in a new wave of development, bringing a smoother and more efficient experience to various voice applications and promoting the application of artificial intelligence technology in more fields. We look forward to seeing more innovative applications based on this model emerge.