In the booming field of AI, data acquisition methods are increasingly becoming the focus. This article explores the controversy caused by the large-scale data scraping behavior of the Claude team under the AI company Anthropic. The Claude team's crawler program ClaudeBot crawled a large amount of data from multiple websites without authorization, which not only violated the website's regulations, but also caused a huge consumption of server resources, triggering widespread criticism and concern. This incident highlights the contradiction between AI development and data copyright protection, triggering the industry to rethink the ethics and legal norms of data acquisition.
The cause of the incident was that Claude's team's crawler visited a company's server 1 million times within 24 hours, crawling website content for free. This behavior not only blatantly ignored the website's crawling ban announcement, but also forcibly occupied a large amount of server resources.
Despite its best efforts to defend itself, the victim company ultimately failed to prevent Claude's team from scraping data. Company leaders angrily took to social media to condemn Claude's team's actions. Many netizens also expressed their dissatisfaction, and some even suggested using the word stealing to describe this behavior.
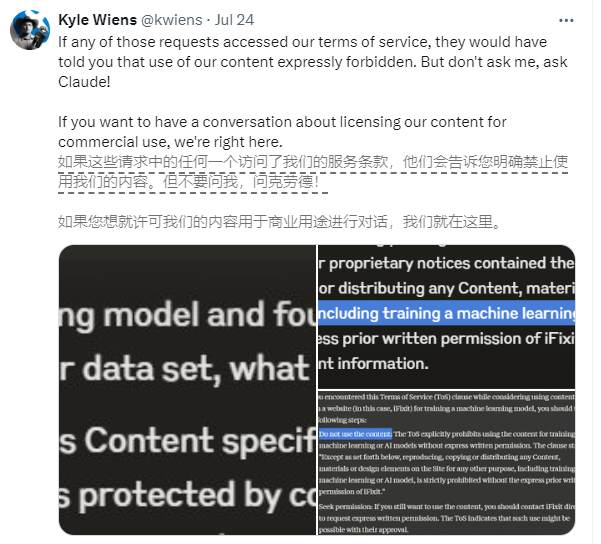
The company involved is iFixit, an American e-commerce and how-to website. iFixit offers millions of pages of free online repair guides covering consumer electronics and gadgets. However, iFixit discovered that Claude's crawler program ClaudeBot initiated a large number of requests in a short period of time, accessing 10TB of files in one day, and a total of 73TB in the entire month of May.
iFixit CEO Kyle Wiens said that ClaudeBot stole all their data without permission and occupied server resources. Although iFixit explicitly states on its website that unauthorized data scraping is prohibited, the Claude team seems to be turning a blind eye to this.
Claude's team's behavior is not unique. In April this year, the Linux Mint forum also suffered from frequent visits by ClaudeBot, causing the forum to run slowly or even crash. In addition, some voices pointed out that in addition to Claude and OpenAI's GPT, there are many other AI companies that are also ignoring the website's robots.txt settings and forcibly grabbing data.
Faced with this situation, it has been suggested that website owners add fake content with traceable or unique information to the page to detect whether the data has been illegally scraped. iFixit has actually taken this step and discovered that their data was scraped not only by Claude, but also by OpenAI.
The incident sparked widespread discussion about the data scraping practices of AI companies. On the one hand, the development of AI does require a large amount of data to support it; on the other hand, data capture should also respect the rights and regulations of the website owner. How to find a balance between promoting technological progress and protecting copyright is a question that the entire industry needs to think about.
The data grabbing incident of Claude's team sounded the alarm, reminding AI companies that while pursuing technological progress, they must respect intellectual property rights, comply with laws and regulations, and actively explore compliant ways to obtain data. Only in this way can we ensure the healthy development of AI technology and avoid damaging industry reputation and public trust due to improper behavior.