Zyphra's newly released Zamba2-2.7B language model is making waves in the field of small language models. This model significantly reduces inference resource requirements while maintaining comparable performance to the 7B model, making it ideal for mobile device applications. Zamba2-2.7B has significantly improved response speed, memory usage and latency, which is crucial for applications that require real-time interaction, such as virtual assistants and chatbots. Its improved interleaved shared attention mechanism and LoRA projector ensure efficient processing of complex tasks.
Recently, Zyphra released the new Zamba2-2.7B language model. This release is of great significance in the history of the development of small language models. The new model achieves significant improvements in performance and efficiency, with its training dataset reaching approximately 3 trillion tokens, making it comparable in performance to Zamba1-7B and other leading 7B models.
The most surprising thing is that Zamba2-2.7B's resource requirements during inference are significantly reduced, making it an efficient solution for mobile device applications.
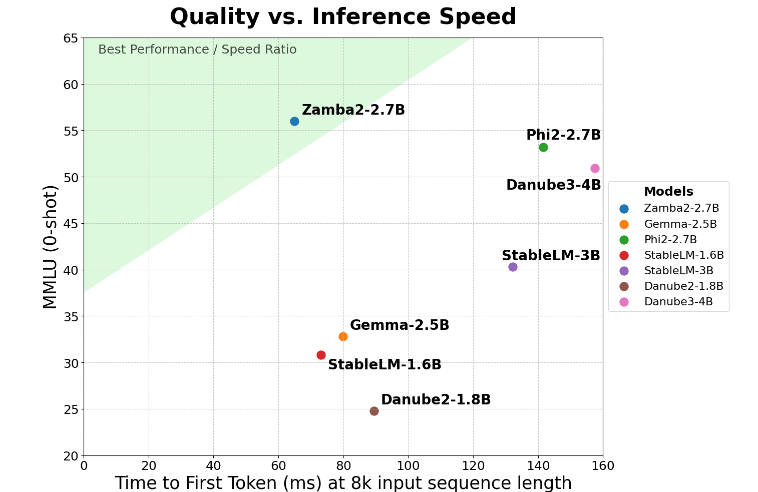
Zamba2-2.7B achieves a two-fold improvement in the key metric of “first-generate response time,” meaning it can generate initial responses faster than the competition. This is critical for applications such as virtual assistants and chatbots that require real-time interaction.
In addition to the speed improvement, Zamba2-2.7B also does an excellent job in memory usage. It reduces memory overhead by 27%, making it ideal for deployment on devices with limited memory resources. Such intelligent memory management ensures that the model can run effectively in environments with limited computing resources, expanding its application scope on various devices and platforms.
Zamba2-2.7B also has the significant advantage of lower build latency. Compared with Phi3-3.8B, its latency is reduced by 1.29 times, which makes the interaction smoother. Low latency is especially important in applications that require seamless, continuous communication, such as customer service bots and interactive educational tools. Therefore, Zamba2-2.7B is undoubtedly the first choice for developers in terms of improving user experience.
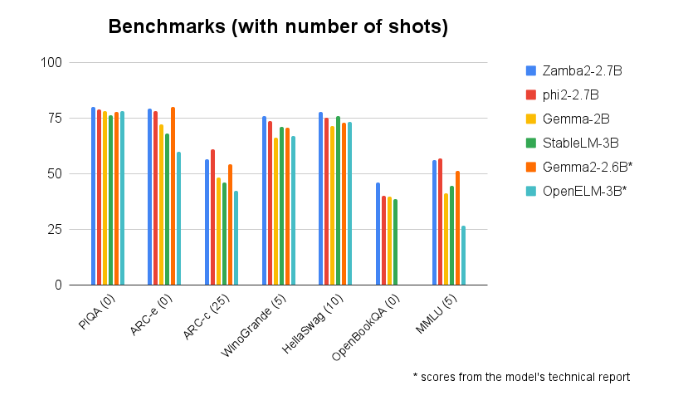
Zamba2-2.7B consistently outperforms in benchmark comparisons with other similarly sized models. Its superior performance proves Zyphra's innovation and efforts in promoting the development of artificial intelligence technology. This model uses an improved interleaved shared attention mechanism and is equipped with a LoRA projector on a shared MLP module to ensure high-performance output when processing complex tasks.
Model entrance: https://huggingface.co/Zyphra/Zamba2-2.7B
Highlights:
The Zamba2-27B model doubles the first response time, making it suitable for real-time interactive applications.
? This model reduces memory overhead by 27% and is suitable for devices with limited resources.
In terms of generation delay, Zamba2-2.7B outperforms similar models, improving user experience.
In short, Zamba2-2.7B has set a new benchmark for small language models with its excellent performance and efficiency, providing developers with more powerful and flexible AI tools, and is expected to play an important role in mobile applications. Its efficient resource utilization and smooth user experience make it a key driving force for the development of future AI applications.