Meta’s experience in training Llama 3.1 large-scale language model has shown us unprecedented challenges and opportunities in the development of AI. The huge cluster of 16,384 GPUs experienced an average failure every 3 hours during the 54-day training period. This not only highlighted the rapid growth of the scale of the AI model, but also exposed the huge bottleneck in the stability of the supercomputing system. This article will delve into the challenges Meta encountered during the Llama 3.1 training process, the strategies they adopted to deal with these challenges, and analyze its implications for the entire AI industry.
In the world of artificial intelligence, every breakthrough is accompanied by jaw-dropping data. Imagine that 16,384 GPUs are running at the same time. This is not a scene in a science fiction movie, but a real portrayal of Meta when training the latest Llama3.1 model. However, behind this technological feast lies a failure that occurs on average every 3 hours. This astonishing number not only demonstrates the speed of AI development, but also exposes the huge challenges faced by current technology.
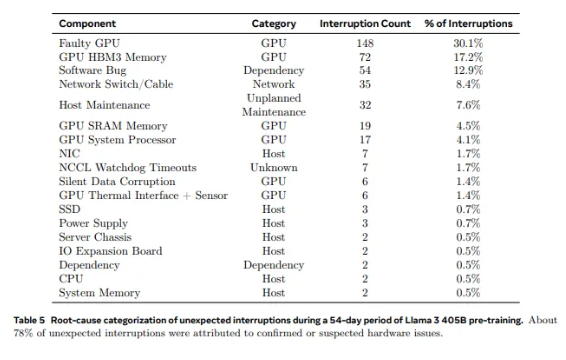
From the 2,028 GPUs used in Llama1 to the 16,384 GPUs used in Llama3.1, this leapfrog growth is not only a change in quantity, but also an extreme challenge to the stability of the existing supercomputing system. Meta's research data shows that during the 54-day training cycle of Llama3.1, a total of 419 unexpected component failures occurred, about half of which were related to the H100 GPU and its HBM3 memory. This data makes us have to think: while pursuing breakthroughs in AI performance, has the reliability of the system also improved simultaneously?
In fact, there is an indisputable fact in the field of supercomputing: the larger the scale, the more difficult it is to avoid failures. Meta’s Llama 3.1 training cluster consists of tens of thousands of processors, hundreds of thousands of other chips, and hundreds of miles of cables, a level of complexity comparable to that of a small city’s neural network. In such a behemoth, malfunctions seem to be a common occurrence.
Faced with frequent failures, the Meta team was not helpless. They adopted a series of coping strategies: reducing job startup and checkpoint times, developing proprietary diagnostic tools, leveraging PyTorch’s NCCL flight recorder, etc. These measures not only improve the fault tolerance of the system, but also enhance automated processing capabilities. Meta's engineers are like modern-day firefighters, ready to put out any fires that might disrupt the training process.
However, the challenges don't just come from the hardware itself. Environmental factors and power consumption fluctuations also bring unexpected challenges to supercomputing clusters. The Meta team found that day and night changes in temperature and drastic fluctuations in GPU power consumption will have a significant impact on training performance. This discovery reminds us that while pursuing technological breakthroughs, we cannot ignore the importance of environmental and energy consumption management.
The training process of Llama3.1 can be called an ultimate test of the stability and reliability of the supercomputing system. The strategies adopted by the Meta team to deal with challenges and the automated tools developed provide valuable experience and inspiration for the entire AI industry. Despite the difficulties, we have reason to believe that with the continuous advancement of technology, future supercomputing systems will be more powerful and stable.
In this era of rapid development of AI technology, Meta's attempt is undoubtedly a brave adventure. It not only pushes the performance boundaries of AI models, but also shows us the real challenges we face in pursuing the limits. Let us look forward to the infinite possibilities brought by AI technology, and at the same time praise those engineers who work tirelessly at the forefront of technology. Every attempt, every failure, and every breakthrough they make paves the way for human technological progress.
References:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- one-failure-every-three-hours-for-metas-16384-gpu-training-cluster
The training case of Llama 3.1 has provided us with valuable lessons and pointed out the future development direction of supercomputing systems: while pursuing performance, we must attach great importance to system stability and reliability, and actively explore strategies to deal with various failures. Only in this way can we ensure the continued and stable development of AI technology and benefit mankind.