NVIDIA recently released the Minitron series of small language models, including 4B and 8B versions. This move aims to reduce the training and deployment costs of large language models and allow more developers to easily use this advanced technology. Through "pruning" and "knowledge distillation" technologies, the Minitron model significantly reduces the model size while maintaining performance comparable to large models, and even surpasses other well-known models in some indicators. This is of great significance for promoting the popularization of artificial intelligence technology.
Recently, NVIDIA has made new moves in the field of artificial intelligence. They have launched the Minitron series of small language models, including 4B and 8B versions. These models not only increase training speed by a full 40 times, but also make it easier for developers to use them for various applications, such as translation, sentiment analysis, and conversational AI.
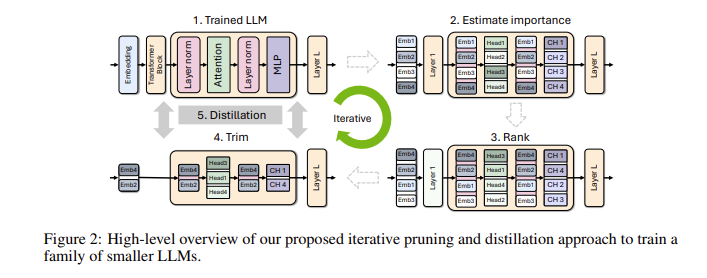
You may ask, why are small language models so important? In fact, although traditional large language models have strong performance, their training and deployment costs are very high, and they often require a large amount of computing resources and data. In order to make these advanced technologies affordable to more people, NVIDIA's research team came up with a brilliant way: combining two technologies: "pruning" and "knowledge distillation" to efficiently Reduce the size of the model.
Specifically, researchers will first start from an existing large model and prune it. They evaluate the importance of each neuron, layer, or attention head in the model and remove those that are less important. In this way, the model becomes much smaller, and the resources and time required for training are also greatly reduced. Next, they will also use a small-scale data set to perform knowledge distillation training on the pruned model to restore the accuracy of the model. Surprisingly, this process not only saves money, but also improves the performance of the model!
In actual testing, NVIDIA’s research team achieved good results on the Nemotron-4 model family. They successfully reduced the model size by 2 to 4 times while maintaining similar performance. What is even more exciting is that the 8B model surpasses other well-known models such as Mistral7B and LLaMa-38B in multiple indicators, and requires a full 40 times less training data during the training process, saving 1.8 times in computing costs. Imagine what this means? More developers can experience powerful AI capabilities with less resources and costs!
NVIDIA makes these optimized Minitron models open source on Huggingface for everyone to use freely.
Demo entrance: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
Highlights:
** Improved training speed **: Minitron model training speed is 40 times faster than traditional models, allowing developers to save time and effort.
**Cost Savings**: Through pruning and knowledge distillation technology, the computing resources and data volume required for training are significantly reduced.
? **Open source sharing**: The Minitron model has been open sourced on Huggingface, so more people can easily access and use it, promoting the popularization of AI technology.
The open source of the Minitron model marks an important breakthrough in the practical application of small language models. It also indicates that artificial intelligence technology will become more popular and easier to use, empowering more developers and application scenarios. In the future, we can expect more similar innovations to promote the continuous development of artificial intelligence technology.