The latest ChatQA2 model released by Nvidia AI has achieved significant breakthroughs in the field of long text context understanding and retrieval enhanced generation (RAG). It is based on the powerful Llama3 model, which significantly improves instruction following capabilities, RAG performance and long text understanding capabilities by extending the context window to 128K tokens and adopting three-stage instruction fine-tuning. ChatQA2 is able to maintain contextual coherence and high recall when processing massive text data, and has demonstrated performance comparable to GPT-4-Turbo in multiple benchmark tests, and even surpassed it in some aspects. This marks a significant advance in the ability of large language models to handle long texts.
Performance breakthrough: ChatQA2 significantly improves instruction following capabilities, RAG performance, and long text understanding by extending the context window to 128K tokens and adopting a three-stage instruction adjustment process. This technological breakthrough enables the model to maintain contextual coherence and high recall when processing data sets of up to 1 billion tokens.
Technical details: ChatQA2 was developed using detailed and reproducible technical solutions. The model first expands the context window of Llama3-70B from 8K to 128K tokens through continuous pre-training. Next, a three-stage instruction tuning process was applied to ensure that the model could effectively handle a variety of tasks.
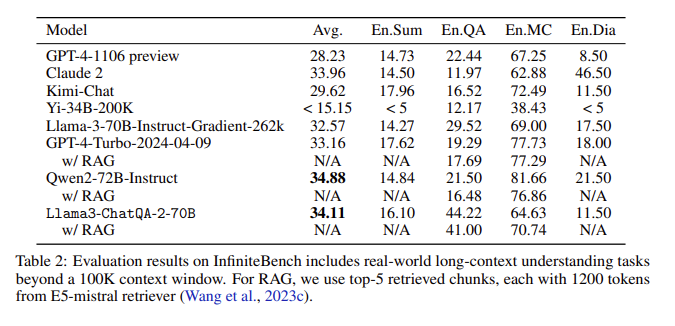
Evaluation results: In the InfiniteBench evaluation, ChatQA2 achieved accuracy comparable to GPT-4-Turbo-2024-0409 on tasks such as long text summary, question and answer, multiple choice, and dialogue, and surpassed it on the RAG benchmark. it. This achievement highlights ChatQA2's comprehensive capabilities across different context lengths and features.
Addressing key issues: ChatQA2 targets key issues in the RAG process, such as context fragmentation and low recall, by using a state-of-the-art long text retriever to improve retrieval accuracy and efficiency.
By extending the context window and implementing a three-stage instruction tuning process, ChatQA2 achieves long text understanding and RAG performance comparable to GPT-4-Turbo. This model provides flexible solutions for a variety of downstream tasks, balancing accuracy and efficiency through advanced long text and retrieval-enhanced generation techniques.
Paper entrance: https://arxiv.org/abs/2407.14482
The emergence of ChatQA2 brings new possibilities for long text processing and RAG applications. Its efficiency and accuracy provide important reference value for the future development of artificial intelligence. Open research on this model also fosters collaboration between academia and industry, driving continued progress in the field. Look forward to seeing more innovative applications based on this model in the future.