Competition in the field of artificial intelligence is fierce, and the rise of open source models is challenging the dominance of technology giants. Recently, artificial intelligence hardware startup Groq released two open source language models-Llama-3-Groq-70B-Tool-Use and Llama3Groq Tool Use 8B, and achieved impressive results on the Berkeley Function Call Ranking (BFCL) Among them, the 70B parameter version surpassed the proprietary models of OpenAI, Google, Anthropic and other companies. The success of these models lies not only in their powerful performance, but also in their use of ethically generated synthetic data during the training process, which effectively solves problems such as data privacy and overfitting, and provides new opportunities for the sustainable development of the field of artificial intelligence. example.
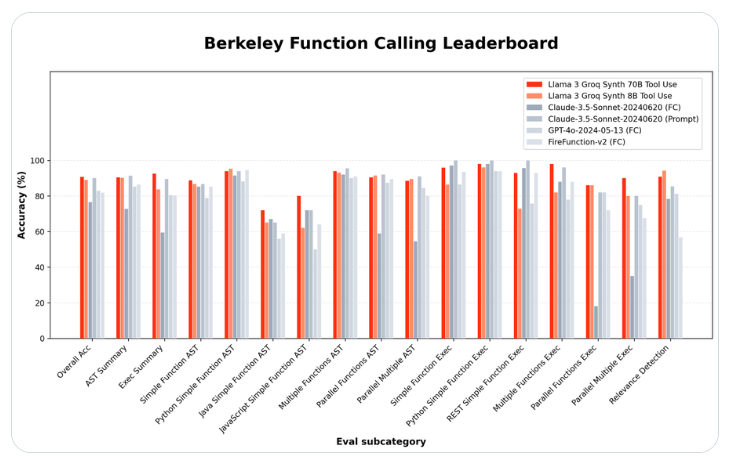
Artificial intelligence hardware startup Groq has released two open source language models that outperform the tech giants in their ability to use specialized tools. The new Llama-3-Groq-70B-Tool-Use model has captured the top spot on the Berkeley Function Call Ranking (BFCL), surpassing proprietary products from the likes of OpenAI, Google, and Anthropic.
Groq project leader Rick Lamers announced the breakthrough in an X.com article. He said: “I am proud to announce the Llama3Groq Tool Use 8B and 70B models. This is a fully fine-tuned version of Llama3’s open source tool that has reached the #1 position on the BFCL, beating all other models including proprietary models. Such as Claude Sonnet3.5, GPT-4Turbo, GPT-4o and Gemini1.5Pro.”
Synthetic data and ethical AI: a new paradigm in model training
The larger 70B parameter version achieved an overall accuracy of 90.76% on BFCL, while the smaller 8B model scored 89.06%, ranking third overall. These results show that open source models can match or even exceed the performance of closed source alternatives on specific tasks.
Groq developed the models in partnership with artificial intelligence research company Glaive, using full fine-tuning and direct preference optimization (DPO) on Meta's Llama-3 base model. The team emphasizes that they only use ethically generated synthetic data for training, addressing common concerns about data privacy and overfitting.
These models are now available through the Groq API and Hugging Face platform. This accessibility can accelerate innovation in areas that require complex tool usage and function calls, such as automated coding, data analysis, and interactive AI assistants.
Groq has also launched a public demo on Hugging Face Spaces, allowing users to interact with the model and test its tooling capabilities first-hand. Like Gradio, which Hugging Face acquired in December 2021, many of the demos on Hugging Face Spaces are created this way. The AI community has responded enthusiastically, with many researchers and developers eager to explore the capabilities of these models.
Highlights:
⭐ Open-source AI model released by Groq outperforms tech giant’s proprietary models at specific tasks
⭐ By using synthetic data for training, Groq challenges common data privacy and overfitting issues in AI model development
⭐ The launch of open source models may change the development path of the AI field and promote broader AI accessibility and the cultivation of innovative ecosystems
The success of the Groq open source model has injected new vitality into the development of the field of artificial intelligence, and also indicates that open source models will play an increasingly important role in the future. Its application of synthetic data provides new ideas in solving issues such as data privacy and model bias, which is worthy of in-depth study and reference by the industry. We look forward to the emergence of more excellent open source models in the future to promote the continued progress of artificial intelligence technology.