Apache Kylin分析型数据仓库 v4.0.3 正式版
4.0.3
Apache Kylin:超大规模数据的亚秒级查询利器
Downcodes小编
Apache Kylin 是一个开源的、分布式的分析型数据仓库,它提供 Hadoop/Spark 之上的 SQL 查询接口和多维分析 (OLAP) 能力,可以高效地处理超大规模数据。最初由 eBay 开发并贡献给开源社区,它在亚秒级内完成对海量数据的查询。
Kylin 的三大步骤
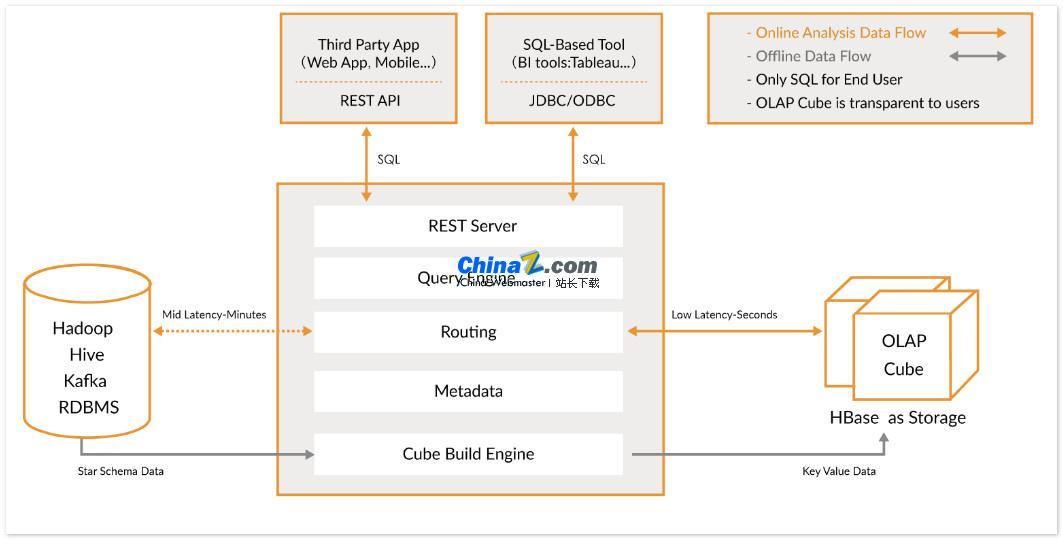
Kylin 使得用户仅需三步,即可实现对超大数据集的亚秒级查询:
1. 定义数据集上的星形或雪花形模型: 首先,你需要定义一个星形或雪花形模型来描述你的数据集。这将帮助 Kylin 理解数据之间的关系,从而优化查询性能。
2. 构建 Cube: 在定义的数据表上构建 Cube,Cube 是 Kylin 进行数据预计算和存储的单位,可以大幅提升查询速度。
3. 使用标准 SQL 查询: 通过 ODBC、JDBC 或 RESTFUL API 使用标准 SQL 语法查询 Cube,Kylin 能够在亚秒级内返回查询结果。
Kylin 的整合能力
Kylin 与多种数据可视化工具集成,例如 Tableau、Power BI 等。用户可以使用这些 BI 工具对 Hadoop 数据进行分析,直观地展示数据洞察。
总结
Apache Kylin 是一个强大的工具,它能够帮助用户在亚秒级内完成对超大规模数据的查询。其易用性、可扩展性和高效性使其成为处理大规模数据分析的理想选择。