论文:关于视觉语言模型的测试时零样本泛化:我们真的需要快速学习吗? 。
作者:马克西姆·扎内拉、伊斯梅尔·本·艾耶德。
这是我们在 CVPR '24 上接受的论文的官方 GitHub 存储库。这项工作引入了 MeanShift 测试时间增强 (MTA) 方法,利用视觉语言模型,无需即时学习。我们的方法将单个图像随机增强为 N 个增强视图,然后在两个关键步骤之间交替(请参阅 mta.py 和代码部分的详细信息。):
此步骤涉及计算每个增强视图的分数,以评估其相关性和质量(内值分数)。
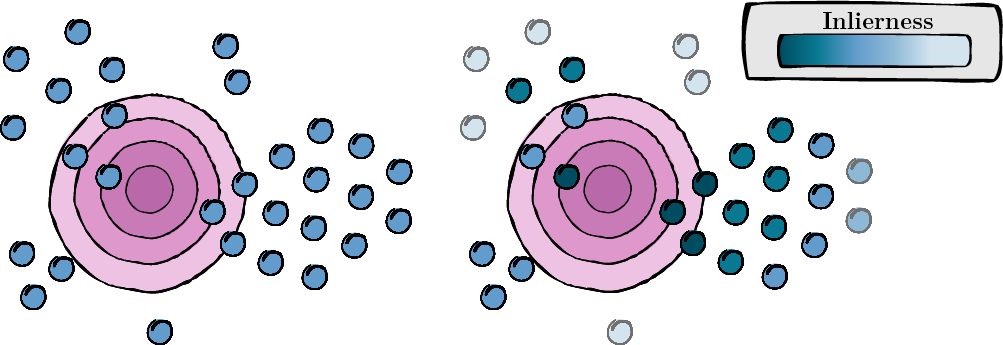
图 1:每个增强视图的分数计算。
根据上一步计算的分数,我们寻找数据点的众数 (MeanShift)。
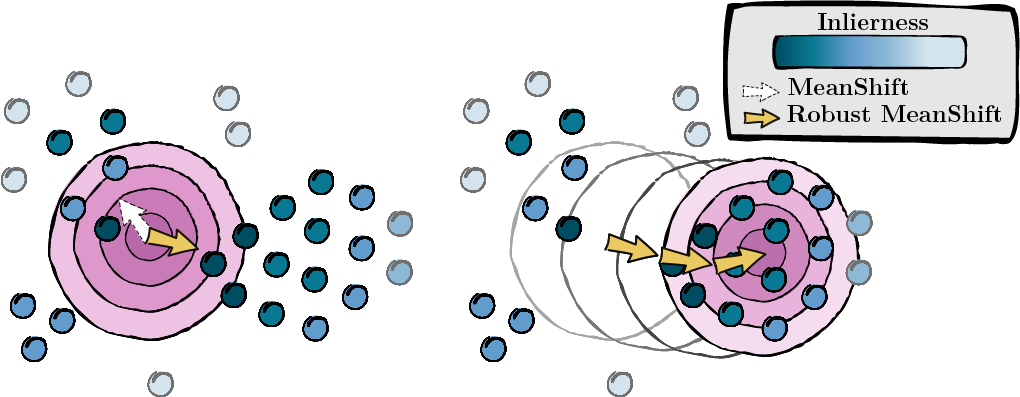
图 2:寻找众数,按内点分数加权。
我们遵循 TPT 安装和预处理。这可确保您的数据集格式正确。您可以在这里找到他们的存储库。如果更方便,您可以更改 data/datautils.py 中字典 ID_to_DIRNAME 中每个数据集的文件夹名称(第 20 行)。
输入以下命令,使用随机种子 1 和“a photo of a”提示对 ImageNet 数据集执行 MTA:
python main.py --data /path/to/your/data --mta --testsets I --seed 1或者一次 15 个数据集:
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1有关 mta.py 过程的更多信息。
gaussian_kernelsolve_mtay ) 的初始值。如果您发现该项目有用,请按如下方式引用:
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}我们对 TPT 作者的开源贡献表示感谢。您可以在这里找到他们的存储库。


