项目页面|纸|型号卡 ?
我们的后续工作《使用受控视觉语言模型进行野外照片逼真图像恢复》(CVPRW 2024) 提出了后采样,以实现更好的图像生成,并处理类似于 Real-ESRGAN 的真实世界混合降解图像。
[ 2024.04.16 ] 我们的后续论文“Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models”现已在 ArXiv 上发布!
[ 2024.04.15 ] 更新了用于现实世界退化的野生红外模型和后验采样以实现更好的图像生成。还为wild-ir提供了预训练权重wild-ir.pth和wild-daclip_ViT-L-14.pt。
[ 2024.01.20 ] ???我们的DA-CLIP论文被ICLR 2024接受了???我们进一步在模型卡中提供了更强大的模型。
[ 2023.10.25 ] 添加了用于训练和测试的数据集链接。
[ 2023.10.13 ] 添加复制演示和 api。感谢@chenxwh!!!我们更新了 Hugging Face 演示和在线 Colab 演示。感谢@fffiloni和@camenduru!我们还在抱脸里做了一张模特卡?并提供了更多测试示例。
[ 2023.10.09 ] DA-CLIP和Universal IR模型的预训练权重分别在link1和link2发布。此外,我们还为您想要测试自己的图像的情况提供了一个Gradio应用程序文件。
操作系统:Ubuntu 20.04
英伟达:
CUDA:11.4
蟒蛇3.8
我们建议您首先创建一个虚拟环境:
python3 -m venv .envsource .env/bin/activate pip安装-U pip pip install -r 要求.txt
进入universal-image-restoration目录并运行:
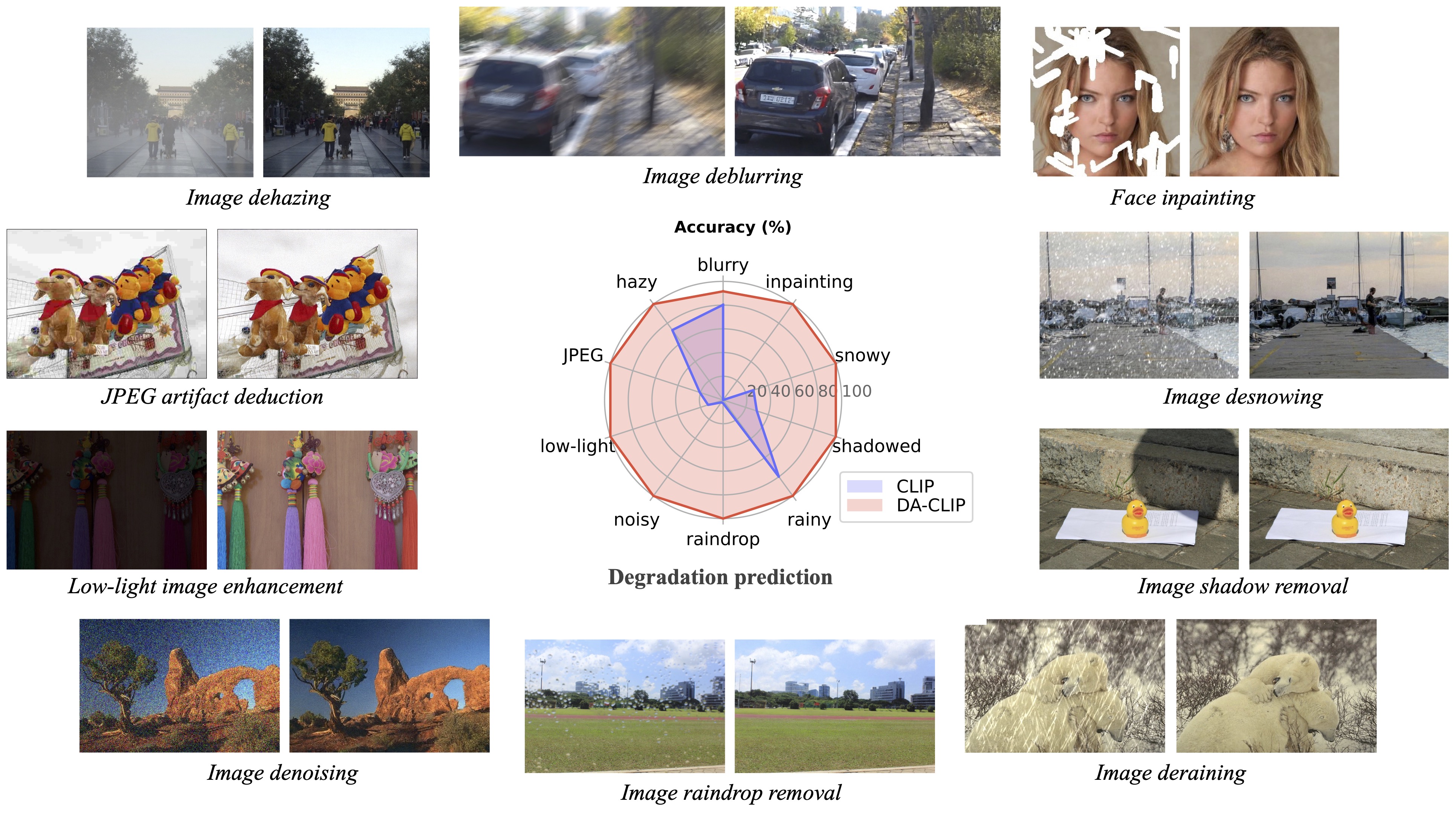
import torchfrom PIL import Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=checkpoint)tokenizer = open_clip.get_tokenizer('ViT-B-32 ')图像= preprocess(Image.open("haze_01.png")).unsqueeze(0)degradations = ['运动模糊','朦胧','jpeg压缩','低光','嘈杂','雨滴' ,'下雨','阴影','下雪','未完成']text = tokenizer(degradations)with torch.no_grad(), torch.cuda.amp.autocast():text_features = model.encode_text(text)image_features, degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, keepdim=True)text_features / = text_features.norm(dim=-1, keepdim=True)text_probs = (100.0 * degra_features @ text_features.T).softmax(dim=-1)index = torch.argmax(text_probs[0])print(f"任务: {task_name}: {degradations[index]} - {text_probs[0][index] }”)按照我们的论文数据集构建部分准备训练和测试数据集,如下所示:
#### 用于训练数据集 ########(未完成意味着修复)####datasets/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--朦胧|--jpeg压缩|--低光|--嘈杂|--雨滴|--雨天|--阴影|--下雪|--未完成## ## 用于测试数据集########(与train相同的结构)####datasets/universal/val ...#### 干净的字幕 ####datasets/universal/daclip_train.csv 数据集/通用/daclip_val.csv
然后进入universal-image-restoration/config/daclip-sde目录并修改options/train.yml和options/test.yml中选项文件中的数据集路径。
您可以将更多任务或数据集添加到train和val目录中,并将退化词添加到distortion 。
| 降解 | 运动模糊 | 朦胧 | jpeg 压缩* | 弱光 | 嘈杂*(与 jpeg 相同) |
|---|---|---|---|---|---|
| 数据集 | 戈普罗 | 居住-6k | DIV2K+Flickr2K | 哈哈 | DIV2K+Flickr2K |
| 降解 | 雨滴 | 下雨的 | 阴影下的 | 下雪的 | 未完成的 |
|---|---|---|---|---|---|
| 数据集 | 雨滴 | Rain100H:训练、测试 | SRD | 雪100K | 西莱巴HQ-256 |
您应该只提取用于训练的训练数据集,所有验证数据集都可以在Google Drive中下载。对于 jpeg 和噪声数据集,您可以使用此脚本生成 LQ 图像。
详细信息请参见 DA-CLIP.md。
训练的主要代码位于universal-image-restoration/config/daclip-sde ,DA-CLIP的核心网络位于universal-image-restoration/open_clip/daclip_model.py 。
将预训练的DA-CLIP 权重放入pretrained目录并检查daclip路径。
然后,您可以按照以下 bash 脚本训练模型:
cd universal-image-restoration/config/daclip-sde# 对于单 GPU:python3 train.py -opt=options/train.yml# 对于分布式训练,需要更改选项文件中的 gpu_ids python3 -m torch.distributed.launch - -nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcher pytorch
模型和训练日志将保存在log/universal-ir中。您可以通过运行tail -f log/universal-ir/train_universal-ir_***.log -n 100来打印日志。
相同的训练步骤可用于野外(wild-ir)图像恢复。
| 型号名称 | 描述 | 谷歌云端硬盘 | 抱脸 |
|---|---|---|---|
| DA-CLIP | 退化感知 CLIP 模型 | 下载 | 下载 |
| 通用红外 | 基于DA-CLIP的通用图像修复模型 | 下载 | 下载 |
| DA-CLIP-混合 | 退化感知 CLIP 模型(添加高斯模糊 + 面部修复和高斯模糊 + Rainy) | 下载 | 下载 |
| 通用红外混合 | 基于 DA-CLIP 的通用图像恢复模型(添加鲁棒训练和混合降级) | 下载 | 下载 |
| 野生DA-CLIP | 野外环境中的降解感知 CLIP 模型 (ViT-L-14) | 下载 | 下载 |
| 野生红外 | 基于DA-CLIP的野外图像恢复模型 | 下载 | 下载 |
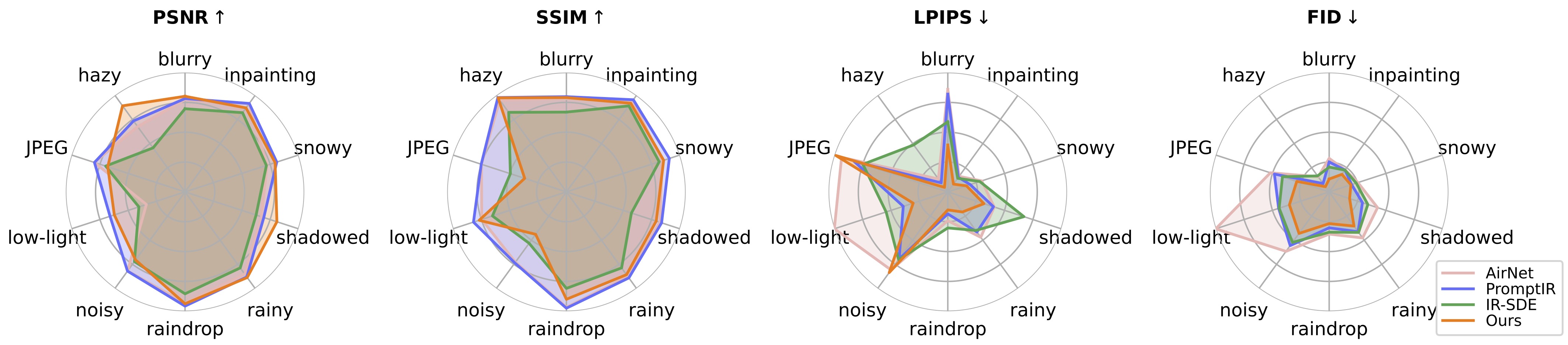
要评估我们的图像恢复方法,请修改基准路径和模型路径并运行
cd 通用图像恢复/config/universal-ir python test.py -opt=选项/test.yml
这里我们提供了一个 app.py 文件来测试您自己的图像。在此之前,您需要下载预训练的权重(DA-CLIP和UIR)并修改options/test.yml中的模型路径。然后只需运行python app.py ,您就可以打开http://localhost:7860来测试模型。 (我们还在images目录中提供了几个具有不同降级的图像)。我们还提供了来自谷歌驱动器中测试数据集的更多示例。
相同的步骤可用于野外 (wild-ir) 图像恢复。



?在测试中,我们发现当前的预训练模型仍然难以处理一些现实世界的图像,这些图像可能与我们的训练数据集(从不同的设备捕获或具有不同的分辨率或退化)发生分布变化。我们将其视为未来的工作,并将努力使我们的模型更加实用!我们还鼓励对我们的工作感兴趣的用户使用更大的数据集和更多的退化类型来训练自己的模型。
?顺便说一句,我们还发现直接调整输入图像的大小会导致大多数任务的性能不佳。我们可以尝试在训练中添加调整大小步骤,但由于插值,它总是会破坏图像质量。
?对于修复任务,由于数据集限制,我们当前的模型仅支持面部修复。我们提供了遮罩示例,您可以使用generate_masked_face脚本来生成未完成的脸部。
致谢:我们的 DA-CLIP 基于 IR-SDE 和 open_clip。感谢他们的代码!
如有任何疑问,请联系:[email protected]
如果我们的代码对您的研究或工作有帮助,请考虑引用我们的论文。以下是 BibTeX 参考文献:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

