
鞠轩1* 、高一鸣1* 、张朝阳1*# 、袁紫阳1 、王新涛1 、曾爱玲、熊宇、徐强、山英1
1腾讯 PCG ARC 实验室2香港中文大学*同等贡献#项目负责人
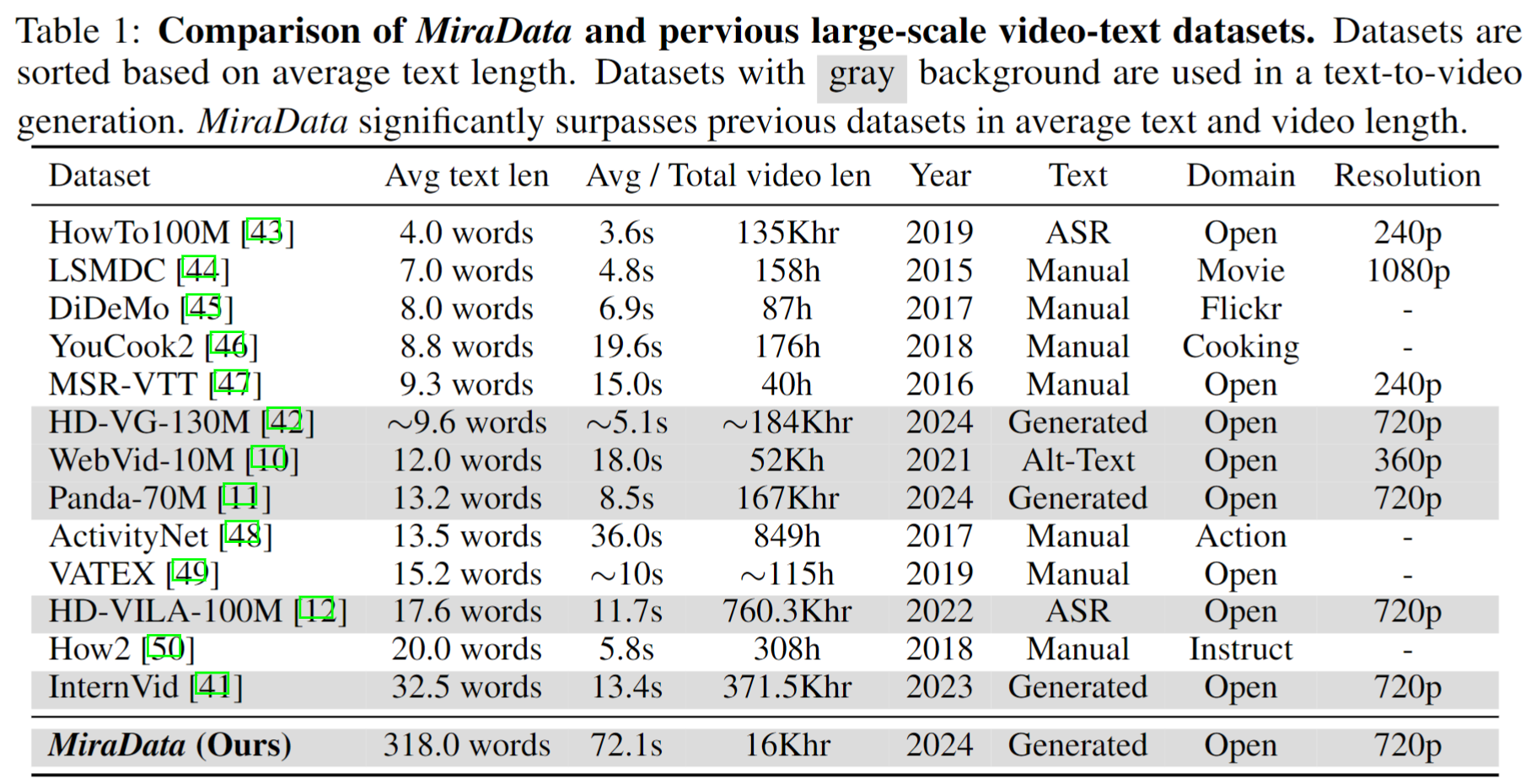
视频数据集在 Sora 等视频生成中发挥着至关重要的作用。然而,现有的文本视频数据集在处理长视频序列和捕获镜头过渡方面往往存在不足。为了解决这些限制,我们引入了MiraData ,这是一个专门为长视频生成任务设计的视频数据集。此外,为了更好地评估视频生成中的时间一致性和运动强度,我们引入了MiraBench ,它通过添加 3D 一致性和基于跟踪的运动强度指标来增强现有基准。您可以在我们的研究论文中找到更多详细信息。
我们发布了四个版本的 MiraData,包含 330K、93K、42K、9K 数据。
此版本的 MiraData 的元文件在 Google Drive 和 HuggingFace 数据集中提供。此外,为了更好、更快地了解我们的元文件组成,我们随机采样了一组 100 个视频剪辑,可以在此处访问。元文件包含以下索引信息:
{download_id}.{clip_id}组成要下载视频并将其分割成剪辑,请首先从 Google Drive 或 HuggingFace 数据集下载元文件。获得元文件后,您可以使用以下脚本下载视频示例:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
只要您需要,我们就会从我们的数据集/Github/项目网页中删除视频样本。请联系我们提出请求。
为了收集 MiraData,我们首先手动选择不同场景下的 YouTube 频道,包括来自 HD-VILA-100M、Videovo、Pixabay 和 Pexels 的视频。然后,使用 PySceneDetect 下载并分割相应频道中的所有视频。然后我们使用多个模型将短片拼接在一起并过滤掉低质量的视频。接下来,我们选择了持续时间较长的视频片段。最后,我们使用 GPT-4V 为所有视频剪辑添加了字幕。

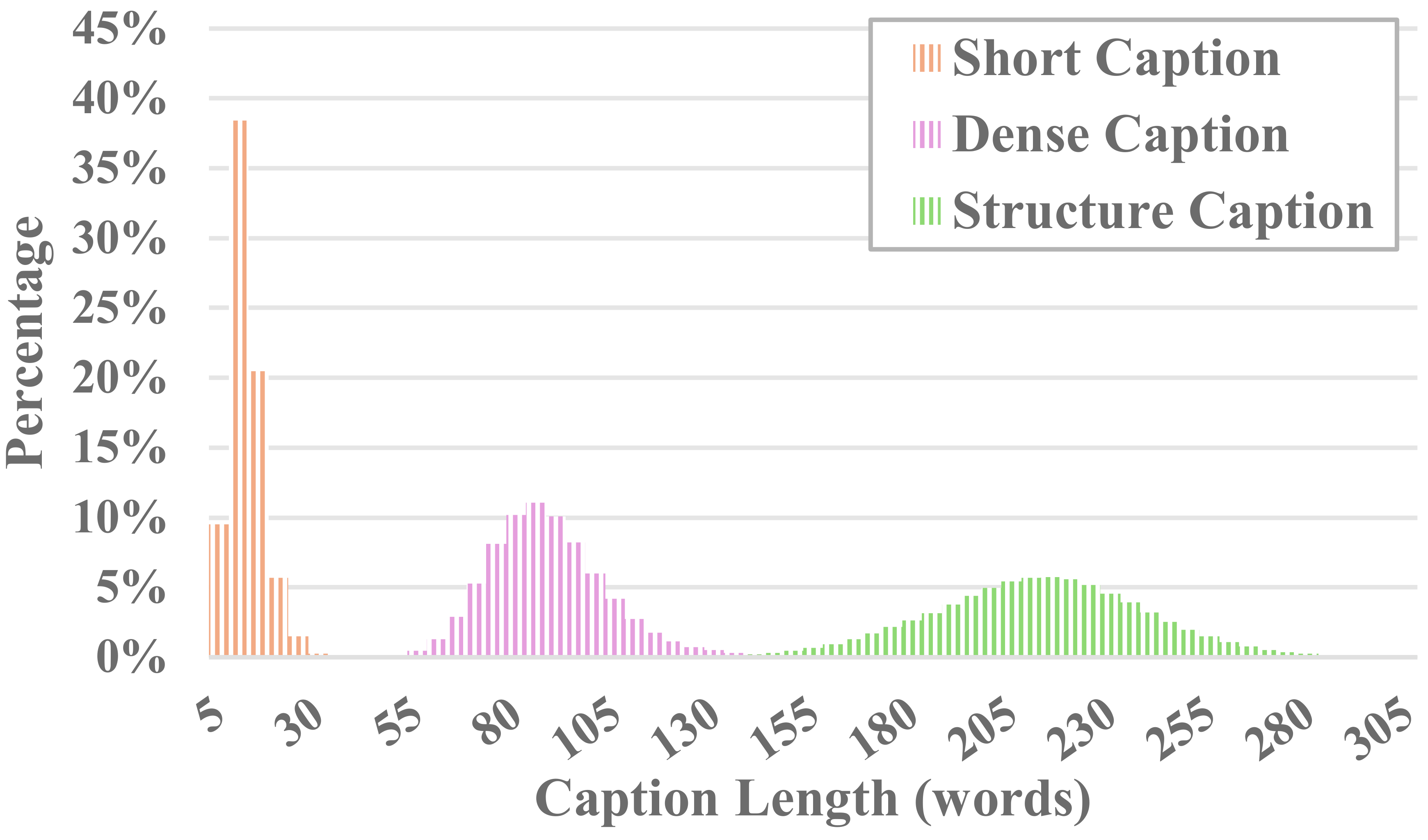
MiraData 中的每个视频都附有结构化字幕。这些标题从不同角度提供了详细描述,增强了数据集的丰富性。
六种类型的字幕
我们测试了现有的开源视觉LLM方法和GPT-4V,发现GPT-4V的字幕在时间序列方面的语义理解上表现出更好的准确性和连贯性。
为了平衡注释成本和字幕准确性,我们为每个视频统一采样 8 帧,并将它们排列成一张大图像的 2x4 网格。然后,我们使用Panda-70M的字幕模型为每个视频添加一句话字幕,作为主要内容的提示,并将其输入到我们微调的提示中。通过将微调的提示和 2x4 大图像输入 GPT-4V,我们可以在一轮对话中高效地输出多个维度的字幕。具体提示内容可以在caption_gpt4v.py中找到,欢迎大家贡献更多优质的文字视频数据。 ?

为了评估长视频生成,我们在MiraBench中从6个角度设计了17个评估指标,包括时间一致性、时间运动强度、3D一致性、视觉质量、文本视频对齐和分布一致性。这些指标涵盖了先前视频生成模型和文本到视频基准中使用的大多数常见评估标准。
要评估生成的视频,请首先通过以下方式设置 python 环境:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
然后,通过以下方式运行评估:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
您可以按照data/evaluation_example中的示例来评估您自己生成的视频。
请参阅许可证。
如果您发现该项目对您的研究有用,请引用我们的论文。 ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
如有任何疑问,请发送电子邮件[email protected] 。
MiraData 遵循 GPL-v3 许可证,支持商业用途。如果您需要 MiraData 的商业许可,请随时与我们联系。


