用于训练任意多模式基础模型的框架。
可扩展。开源。跨越数十种模式和任务。
洛桑联邦理工学院 - 苹果
Website | BibTeX | ? Demo
官方实施和预训练模型:
4M:大规模多模态掩模建模,NeurIPS 2023(聚焦)
David Mizrahi*、Roman Bachmann*、Oğuzhan Fatih Kar、Teresa Yeo、高明飞、Afshin Dehghan、Amir Zamir
4M-21:适用于数十种任务和模式的任意视觉模型,NeurIPS 2024
Roman Bachmann*、Oğuzhan Fatih Kar*、David Mizrahi*、Ali Garjani、高明飞、David Griffiths、胡家明、Afshin Dehghan、Amir Zamir
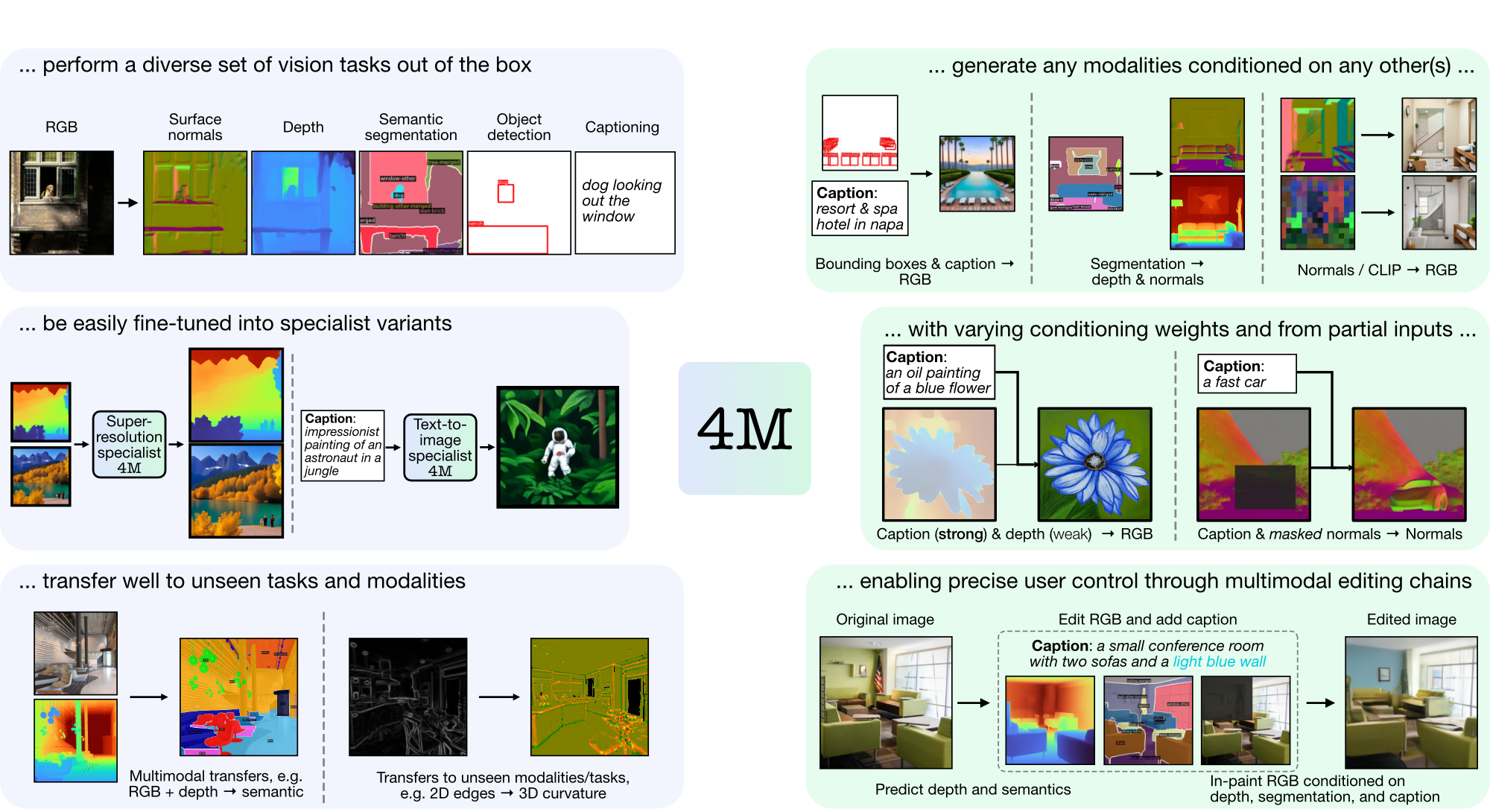
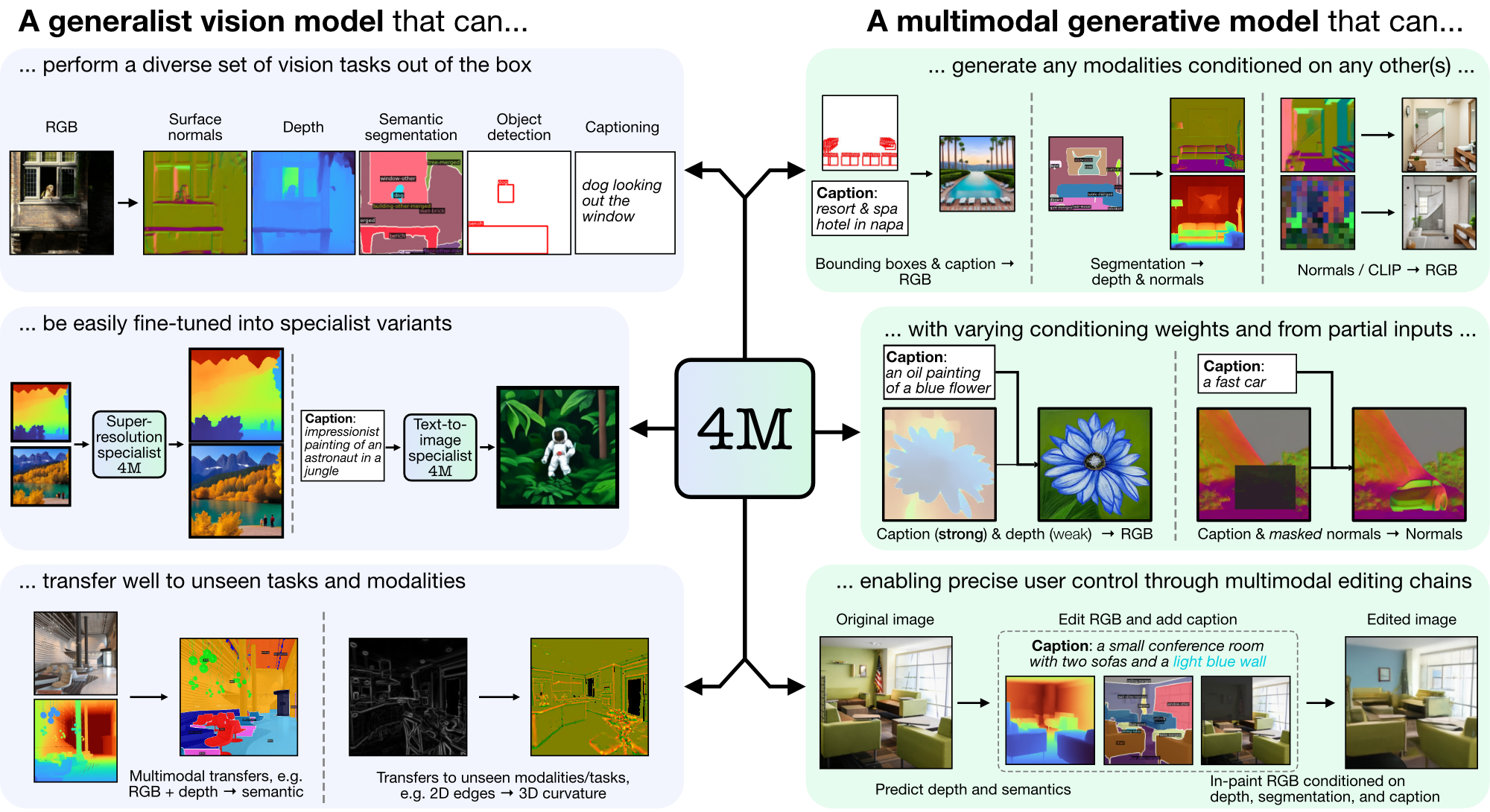
4M 是一个用于训练“任意到任意”基础模型的框架,使用标记化和掩蔽来扩展到多种不同的模式。使用 4M 训练的模型可以执行广泛的视觉任务,可以很好地迁移到看不见的任务和模式,并且是灵活且可操纵的多模式生成模型。我们正在发布“4M:大规模多模态掩蔽建模”(此处表示为 4M-7)的代码和模型,以及“4M-21:适用于数十种任务和模态的任意视觉模型”(此处表示为 4M) -21)。
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
如果 CUDA 不可用,请考虑按照官方安装说明重新安装 PyTorch。同样,如果您想安装 xFormers(可选,为了更快的分词器),请按照其 README 操作以确保 CUDA 版本正确。
我们提供了一个演示包装器,可以快速开始使用 4M 模型进行 RGB-to-all 或 {caption,bounding box}-to-all 生成任务。例如,要从给定的 RGB 输入生成所有模态,请调用:
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )您应该会看到如下所示的输出:


要执行“caption-to-all”生成,您可以将采样器输入替换为: preds = sampler({'caption': 'A lake house with a boat in front [S_1]'}) 。有关可用 4M 模型的列表,请参阅下面的模型动物园,并参阅 README_GENERATION.md 了解有关生成的更多说明。
有关如何准备对齐的多模式数据集的说明,请参阅 README_DATA.md。
有关如何训练特定于模态的分词器的说明,请参阅 README_TOKENIZATION.md。
有关如何训练 4M 模型的说明,请参阅 README_TRAINING.md。
有关如何使用 4M 模型进行推理/生成的说明,请参阅 README_GENERATION.md。我们还提供了一个生成笔记本,其中包含 4M 推理的示例,专门执行条件图像生成和常见视觉任务(即 RGB-to-All)。
我们提供 4M 和 tokenizer 检查点作为安全张量,并且还通过 Hugging Face Hub 提供轻松加载。
| 模型 | # 模组。 | 数据集 | # 参数 | 配置 | 重量 |
|---|---|---|---|---|---|
| 4M-B | 7 | CC12M | 198M | 配置 | 检查点/高频集线器 |
| 4M-B | 7 | 科约700M | 198M | 配置 | 检查点/高频集线器 |
| 4M-B | 21 | CC12M+COYO700M+C4 | 198M | 配置 | 检查点/高频集线器 |
| 4M-L | 7 | CC12M | 705M | 配置 | 检查点/高频集线器 |
| 4M-L | 7 | 科约700M | 705M | 配置 | 检查点/高频集线器 |
| 4M-L | 21 | CC12M+COYO700M+C4 | 705M | 配置 | 检查点/高频集线器 |
| 4M-XL | 7 | CC12M | 2.8B | 配置 | 检查点/高频集线器 |
| 4M-XL | 7 | 科约700M | 2.8B | 配置 | 检查点/高频集线器 |
| 4M-XL | 21 | CC12M+COYO700M+C4 | 2.8B | 配置 | 检查点/高频集线器 |
要从 Hugging Face Hub 加载模型:
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )要手动加载检查点,请首先从上面的链接下载 safetensors 文件并调用:
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )这些模型使用标准 4M-7 CC12M 模型进行初始化,但继续使用严重偏向于文本输入的模态混合进行训练。它们仍然能够执行所有其他任务,但与未微调的模型相比,它们在文本到图像生成方面表现更好。
| 模型 | # 模组。 | 数据集 | # 参数 | 配置 | 重量 |
|---|---|---|---|---|---|
| 4M-T2I-B | 7 | CC12M | 198M | 配置 | 检查点/高频集线器 |
| 4M-T2I-L | 7 | CC12M | 705M | 配置 | 检查点/高频集线器 |
| 4M-T2I-XL | 7 | CC12M | 2.8B | 配置 | 检查点/高频集线器 |
要从 Hugging Face Hub 加载模型:
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )从检查点手动加载的执行方式与上述基本 4M 模型相同。
| 模型 | # 模组。 | 数据集 | # 参数 | 配置 | 重量 |
|---|---|---|---|---|---|
| 4M-SR-L | 7 | CC12M | 198M | 配置 | 检查点/高频集线器 |
要从 Hugging Face Hub 加载模型:
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )从检查点手动加载的执行方式与上述基本 4M 模型相同。
| 模态 | 解决 | 代币数量 | 码本大小 | 扩散解码器 | 重量 |
|---|---|---|---|---|---|
| RGB | 224-448 | 196-784 | 16k | ✓ | 检查点/高频集线器 |
| 深度 | 224-448 | 196-784 | 8k | ✓ | 检查点/高频集线器 |
| 法线 | 224-448 | 196-784 | 8k | ✓ | 检查点/高频集线器 |
| 边缘(Canny、SAM) | 224-512 | 196-1024 | 8k | ✓ | 检查点/高频集线器 |
| COCO语义分割 | 224-448 | 196-784 | 4k | ✗ | 检查点/高频集线器 |
| 夹子-B/16 | 224-448 | 196-784 | 8k | ✗ | 检查点/高频集线器 |
| 恐龙v2-B/14 | 224-448 | 256-1024 | 8k | ✗ | 检查点/高频集线器 |
| DINOv2-B/14(全球) | 224 | 16 | 8k | ✗ | 检查点/高频集线器 |
| 图像绑定-H/14 | 224-448 | 256-1024 | 8k | ✗ | 检查点/高频集线器 |
| ImageBind-H/14(全球) | 224 | 16 | 8k | ✗ | 检查点/高频集线器 |
| SAM 实例 | - | 64 | 1k | ✗ | 检查点/高频集线器 |
| 3D人体姿势 | - | 8 | 1k | ✗ | 检查点/高频集线器 |
要从 Hugging Face Hub 加载模型:
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )要手动加载检查点,请首先从上面的链接下载 safetensors 文件并调用:
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )此存储库中的代码是根据 Apache 2.0 许可证发布的,如 LICENSE 文件中所示。
此存储库中的模型权重是在 LICENSE_WEIGHTS 文件中找到的示例代码许可证下发布的。
如果您发现此存储库有帮助,请考虑引用我们的工作:
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


