storm
v1.0.0 & EMNLP 2024 Paper Accepted!
|研究预览|风暴纸|共同风暴纸|网站|
最新消息
[2024/09] Co-STORM代码库现已发布并集成到knowledge-storm python包v1.0.0中。运行pip install knowledge-storm --upgrade进行检查。
[2024/09] 我们引入协作风暴(Co-STORM)来支持人机协作知识管理! Co-STORM论文已被EMNLP 2024主会议接收。
[2024/07] 您现在可以使用pip install knowledge-storm安装我们的软件包!
[2024/07] 我们添加了VectorRM以支持基于用户提供的文档,补充了搜索引擎( YouRM 、 BingSearch )的现有支持。 (查看#58)
[2024/07] 我们为开发人员发布了 demo light,这是一个使用 Python 中的 Streamlit 框架构建的最小用户界面,方便本地开发和演示托管(查看 #54)
[2024/06] 我们将在NAACL 2024上呈现STORM!欢迎参加 6 月 17 日的海报会议 2 或查看我们的演示材料。
[2024/05] 我们在 rm.py 中添加了 Bing 搜索支持。使用GPT-4o测试 STORM - 我们现在使用GPT-4o模型在演示中配置文章生成部分。
[2024/04] 我们发布了STORM代码库的重构版本!我们定义 STORM 管道的接口并重新实现 STORM-wiki(查看src/storm_wiki )以演示如何实例化管道。我们提供API来支持不同语言模型的定制和检索/搜索集成。
虽然该系统无法生成通常需要大量编辑的可发表文章,但经验丰富的维基百科编辑发现它在预写作阶段很有帮助。
超过 70,000 人尝试过我们的实时研究预览。尝试一下,看看 STORM 如何帮助您的知识探索之旅,并请提供反馈以帮助我们改进系统!
STORM 将生成带有引用的长文章分为两个步骤:
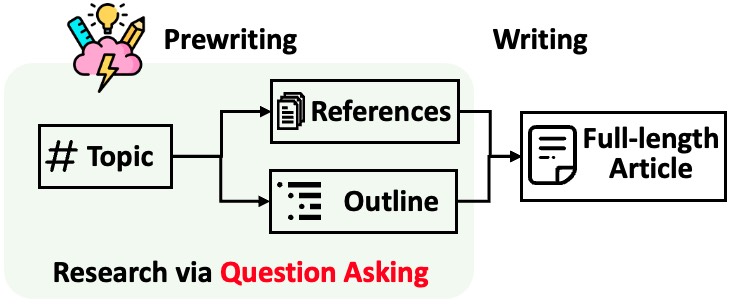
STORM 认为研究过程自动化的核心是自动提出好的问题。直接提示语言模型提出问题效果并不好。为了提高问题的深度和广度,STORM 采用了两种策略:
Co-STORM提出了一种协作对话协议,该协议实施轮流管理策略以支持之间的顺利协作
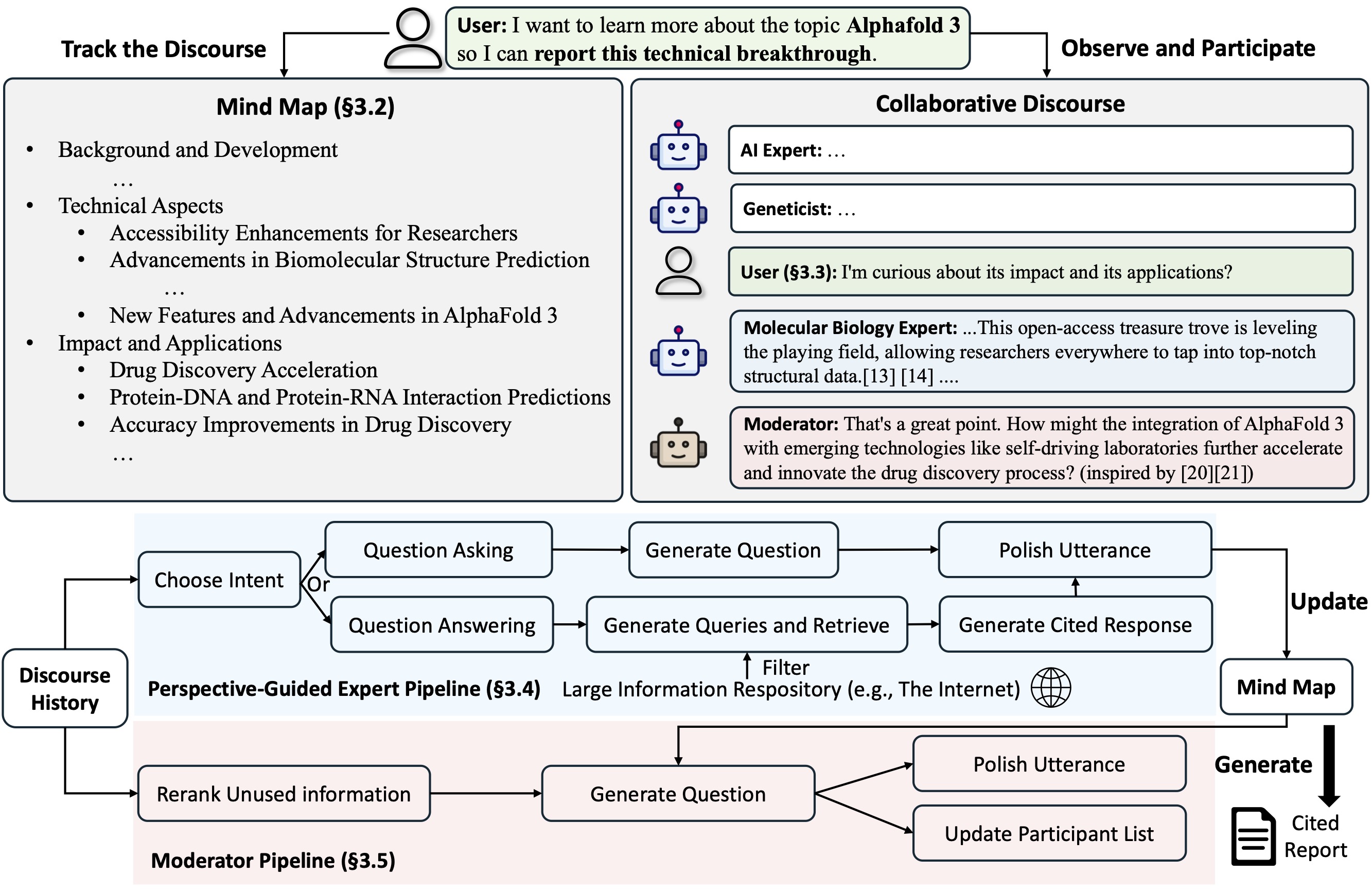
Co-STORM还维护一个动态更新的思维导图,它将收集到的信息组织成分层概念结构,旨在在人类用户和系统之间建立共享的概念空间。事实证明,思维导图有助于减轻长篇深入的演讲时的精神负担。
STORM 和 Co-STORM 都是使用 dspy 以高度模块化的方式实现的。
要安装知识风暴库,请使用pip install knowledge-storm 。
您还可以安装源代码,它允许您直接修改 STORM 引擎的行为。
克隆 git 存储库。
git clone https://github.com/stanford-oval/storm.git
cd storm安装所需的软件包。
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txt目前,我们的套餐支持:
OpenAIModel 、 AzureOpenAIModel 、 ClaudeModel 、 VLLMClient 、 TGIClient 、 TogetherClient 、 OllamaClient 、 GoogleModel 、 DeepSeekModel 、 GroqModel作为语言模型组件YouRM 、 BingSearch 、 VectorRM 、 SerperRM 、 BraveRM 、 SearXNG 、 DuckDuckGoSearchRM 、 TavilySearchRM 、 GoogleSearch和AzureAISearch作为检索模块组件?将更多语言模型集成到knowledge_storm/lm.py 并将搜索引擎/检索器集成到knowledge_storm/rm.py 的 PR 受到高度赞赏!
STORM和Co-STORM都工作在信息管理层,需要设置信息检索模块和语言模型模块来分别创建它们的Runner类。
STORM 知识管理引擎被定义为一个简单的 Python STORMWikiRunner类。以下是使用 You.com 搜索引擎和 OpenAI 模型的示例。
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) STORMWikiRunner实例可以通过简单的run方法调用:
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research :如果为 True,则模拟不同视角的对话以收集有关该主题的信息;否则,加载结果。do_generate_outline :如果为 True,则生成主题的大纲;否则,加载结果。do_generate_article :如果为 True,则根据大纲和收集到的信息生成该主题的文章;否则,加载结果。do_polish_article :如果为 True,则通过添加摘要部分并(可选)删除重复内容来完善文章;否则,加载结果。Co-STORM 知识管理引擎被定义为一个简单的 Python CoStormRunner类。这是使用 Bing 搜索引擎和 OpenAI 模型的示例。
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) CoStormRunner实例可以通过warmstart()和step(...)方法来调用。
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )我们在示例文件夹中提供了脚本,作为使用不同配置运行 STORM 和 Co-STORM 的快速入门。
我们建议使用secrets.toml来设置 API 密钥。在根目录下创建文件secrets.toml ,添加以下内容:
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key "要使用具有默认配置的gpt系列型号运行 STORM:
运行以下命令。
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-article要使用您最喜欢的语言模型或基于您自己的语料库运行 STORM:查看 Examples/storm_examples/README.md。
要使用默认配置的gpt系列型号运行 Co-STORM,
BING_SEARCH_API_KEY="xxx"和ENCODER_API_TYPE="xxx"添加到secrets.tomlpython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bing如果您已经安装了源代码,您可以根据自己的用例自定义STORM。 STORM引擎由4个模块组成:
每个模块的接口在knowledge_storm/interface.py中定义,而它们的实现在knowledge_storm/storm_wiki/modules/*中实例化。这些模块可以根据您的具体要求进行定制(例如,以项目符号格式生成部分而不是完整段落)。
如果您已经安装了源代码,您可以根据自己的用例定制Co-STORM
knowledge_storm/interface.py中定义,而其实现在knowledge_storm/collaborative_storm/modules/co_storm_agents.py中实例化。可以定制不同的LLM代理政策。knowledge_storm/collaborative_storm/engine.py中提供了通过DiscourseManager实现轮流策略管理的示例。它可以定制并进一步改进。 为了促进自动知识管理和复杂信息搜索的研究,我们的项目发布了以下数据集:
FreshWiki 数据集是 100 篇高质量维基百科文章的集合,重点关注 2022 年 2 月至 2023 年 9 月编辑次数最多的页面。有关更多详细信息,请参阅 STORM 论文中的第 2.1 节。
您可以直接从huggingface下载数据集。为了缓解数据污染问题,我们将数据构建管道的源代码存档,以便将来可以重复使用。
为了研究用户对野外复杂信息搜索任务的兴趣,我们利用从网络研究预览中收集的数据来创建 WildSeek 数据集。我们对数据进行了下采样,以确保主题的多样性和数据的质量。每个数据点都是一对,包含一个主题和用户对该主题进行深度搜索的目标。更多详细信息,请参阅Co-STORM论文的2.2节和附录A。
WildSeek 数据集可在此处获取。
对于STORM论文实验,请切换到此处的分支NAACL-2024-code-backup 。
对于Co-STORM论文实验,请切换到分支EMNLP-2024-code-backup (暂时占位,稍后更新)。
我们的团队正在积极致力于:
如果您有任何问题或建议,请随时提出问题或拉取请求。我们欢迎为改进系统和代码库做出贡献!
联系人:邵益佳、蒋玉成
我们要感谢维基百科提供的优秀开源内容。 FreshWiki 数据集源自维基百科,并根据 Creative Commons Attribution-ShareAlike (CC BY-SA) 许可获得许可。
我们非常感谢 Michelle Lam 为该项目设计了徽标,并感谢 Dekun Ma 领导了 UI 开发。
如果您在工作中使用此代码或其中的一部分,请引用我们的论文:
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}

