FaceSwap
1.0.0
FaceSwap 是我最初为华沙理工大学“多媒体数学”学生们创建的一个应用程序。该应用程序是用 Python 编写的,并使用面部对齐、高斯牛顿优化和图像混合来将相机看到的人脸与提供的图像中的人脸交换。
您可以在下面的视频中找到该程序功能的简短演示(点击即可转至 YouTube):
要启动该程序,您必须运行名为 zad2.py 的 Python 脚本(练习 2 的波兰语)。您需要安装 Python 3 和一些附加库。一旦 Python 安装在您的计算机上,您应该能够通过在存储库的根目录中运行pip install -r requirements.txt来自动安装库。
您还必须从此处下载面部对齐模型:http://sourceforge.net/projects/dclib/files/dlib/v18.10/shape_predictor_68_face_landmarks.dat.bz2 并将其解压到主项目目录。
Dropbox 上提供了更快、更稳定的 FaceSwap 版本。这个新版本基于深度对齐网络方法,如果在 GPU 上运行,该方法比当前使用的方法更快,并提供更稳定、更精确的面部标志。请参阅 Deep Alignment Network 的 GitHub 存储库以获取设置说明。
我希望尽快找到时间将这个更快的版本包含在存储库代码中。
该方法的概要如下:
首先,我们获取输入图像(我们想要在自己的脸上看到的人的图像)并找到面部区域及其标志。一旦我们将 3D 模型拟合到这些地标(稍后会详细介绍),投影到图像空间的模型的顶点将是我们的纹理坐标。
一旦完成并且一切都初始化后,相机就开始捕捉图像。对于每个捕获的图像,执行以下步骤:
整个过程中最关键的环节是3D模型的拟合。该模型本身包括:
使用以下方程将模型投影到图像空间:
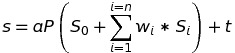
其中s是投影形状, a是缩放参数, P是旋转 3D 面部形状的旋转矩阵的前两行, S_0是中性面部形状, w_1-n是混合形状权重, S_1-n是blendshapes, t是 2D 平移向量, n是 Blendshape 的数量。
模型拟合是通过最小化投影形状和局部地标之间的差异来完成的。使用高斯牛顿方法完成混合形状权重、缩放、旋转和平移的最小化。
该代码获得MIT许可,项目中的部分数据是从第三方网站下载的:
如果需要帮助或者您发现该应用程序有用,请随时告诉我。
Marek Kowalski [email protected],主页:http://home.elka.pw.edu.pl/~mkowals6/


