ai toolkit
1.0.0
这是我的研究报告。我在其中做了很多实验,我可能会破坏一些东西。如果出现问题,请检查较早的提交。这个仓库可以训练很多东西,但很难跟上所有的东西。
如果没有 Glif 和团队中每个人的大力支持,我在这个项目上的工作就不可能实现。如果你想支持我,就支持Glif。加入网站,加入 Discord,在 Twitter 上关注我们,并与我们一起制作一些很酷的东西
要求:
Linux:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python3 -m venv venv
source venv/bin/activate
# .venvScriptsactivate on windows
# install torch first
pip3 install torch
pip3 install -r requirements.txt视窗:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
. v env S cripts a ctivate
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt要快速开始,请查看 @araminta_k 关于在具有 24GB VRAM 的 3090 上微调 Flux Dev 的教程。
您当前需要具有至少 24GB VRAM 的GPU 来训练 FLUX.1。如果您使用它作为 GPU 来控制显示器,您可能需要在model:下的配置文件中设置标志low_vram: true 。这将在 CPU 上量化模型,并允许其在连接监视器的情况下进行训练。用户已使其能够通过 WSL 在 Windows 上运行,但有一些报告称在 Windows 上本机运行时存在错误。我目前只在linux上进行了测试。这仍处于实验阶段,必须进行大量量化和技巧才能使其适合 24GB。
FLUX.1-dev 拥有非商业许可证。这意味着您训练的任何内容都将继承非商业许可证。它也是一个门控模型,因此您需要在使用之前接受 HF 上的许可证。否则,这将失败。以下是设置许可证所需的步骤。
.env的文件.env文件中,如下所示HF_TOKEN=your_key_hereFLUX.1-schnell 是 Apache 2.0。任何在其上训练的内容都可以根据您的需要获得许可,并且不需要 HF_TOKEN 进行训练。然而,它确实需要一个特殊的适配器来训练,ostris/FLUX.1-schnell-training-adapter。它也是高度实验性的。为了获得最佳整体质量,建议在 FLUX.1-dev 上进行培训。
要使用它,您只需将助手添加到配置文件的model部分,如下所示:
model :
name_or_path : " black-forest-labs/FLUX.1-schnell "
assistant_lora_path : " ostris/FLUX.1-schnell-training-adapter "
is_flux : true
quantize : true您还需要调整示例步骤,因为 schnell 不需要那么多
sample :
guidance_scale : 1 # schnell does not do guidance
sample_steps : 4 # 1 - 4 works wellconfig/examples/train_lora_flux_24gb.yaml示例配置文件(对于 schnell 为config/examples/train_lora_flux_schnell_24gb.yaml )复制到config文件夹并将其重命名为whatever_you_want.ymlpython run.py config/whatever_you_want.yml启动时,将创建一个具有配置文件名称和训练文件夹的文件夹。它将包含所有检查点和图像。您可以随时使用 ctrl+c 停止训练,当您恢复时,它将从最后一个检查点恢复。
重要的。如果在保存时按 crtl+c,则可能会损坏该检查点。所以等到保存完成
请不要打开错误报告,除非它是代码中的错误。欢迎您加入我的 Discord 并在那里寻求帮助。但是,请不要直接私信我提出一般性问题或支持。在不和谐中提问,我会尽可能回答。
要开始使用自定义 UI 进行本地训练,请按照上述步骤操作并安装ai-toolkit :
cd ai-toolkit # in case you are not yet in the ai-toolkit folder
huggingface-cli login # provide a `write` token to publish your LoRA at the end
python flux_train_ui.py您将实例化一个 UI,让您上传图像、为其添加标题、训练和发布您的 LoRA 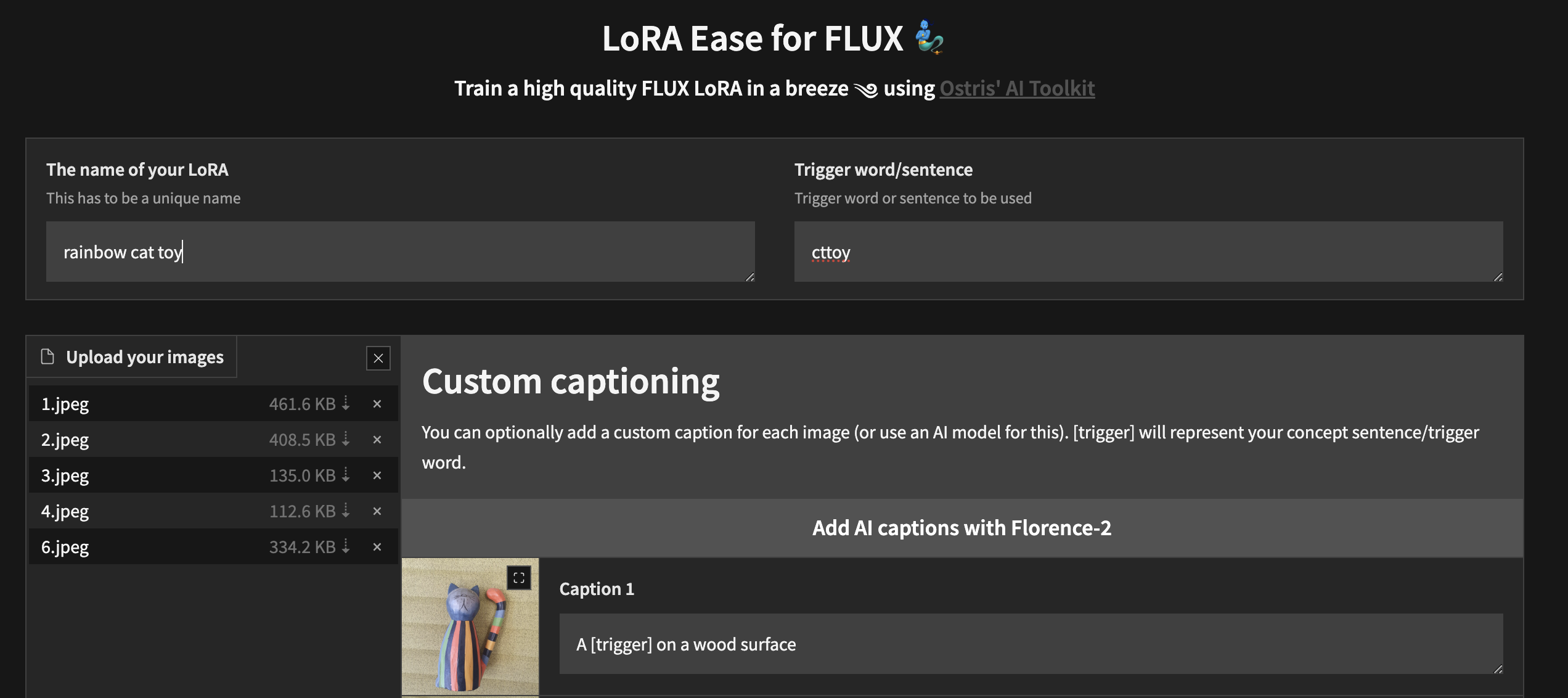
RunPod 模板示例: runpod/pytorch:2.2.0-py3.10-cuda12.1.1-devel-ubuntu22.04
您至少需要 24GB VRAM,根据您的喜好选择 GPU。
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
dataset或任何您喜欢的名称。huggingface-cli login并粘贴您的令牌。config/examples示例配置文件复制到 config 文件夹并将其重命名为whatever_you_want.yml 。folder_path: "/path/to/images/folder"更改为您的数据集路径,例如folder_path: "/workspace/ai-toolkit/your-dataset" 。python run.py config/whatever_you_want.yml 。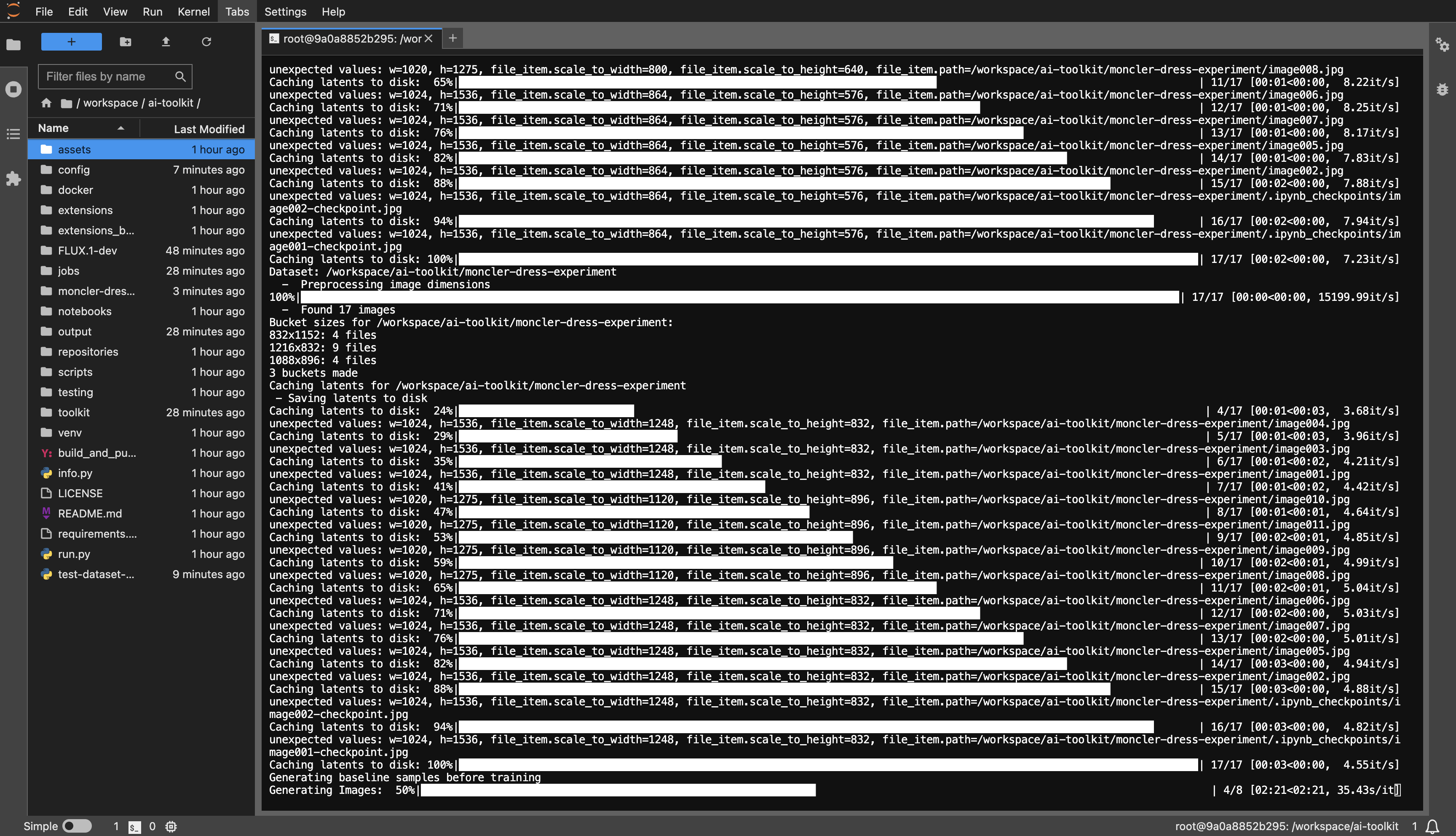
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
pip install modal以安装模态 Python 包。modal setup进行身份验证(如果这不起作用,请尝试python -m modal setup )。 huggingface-cli login并粘贴您的令牌。ai-toolkit中。config/examples/modal示例配置文件复制到config文件夹并将其重命名为whatever_you_want.yml 。/root/ai-toolkit paths 。将整个本地ai-toolkit路径设置为code_mount = modal.Mount.from_local_dir如下所示:
code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit")
在@app.function中选择GPU和Timeout (默认为 A100 40GB 和 2 小时超时) 。
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.yml 。Storage > flux-lora-models中。modal volume ls flux-lora-models检查卷的内容。modal volume get flux-lora-models your-model-name下载内容。modal volume get flux-lora-models my_first_flux_lora_v1 。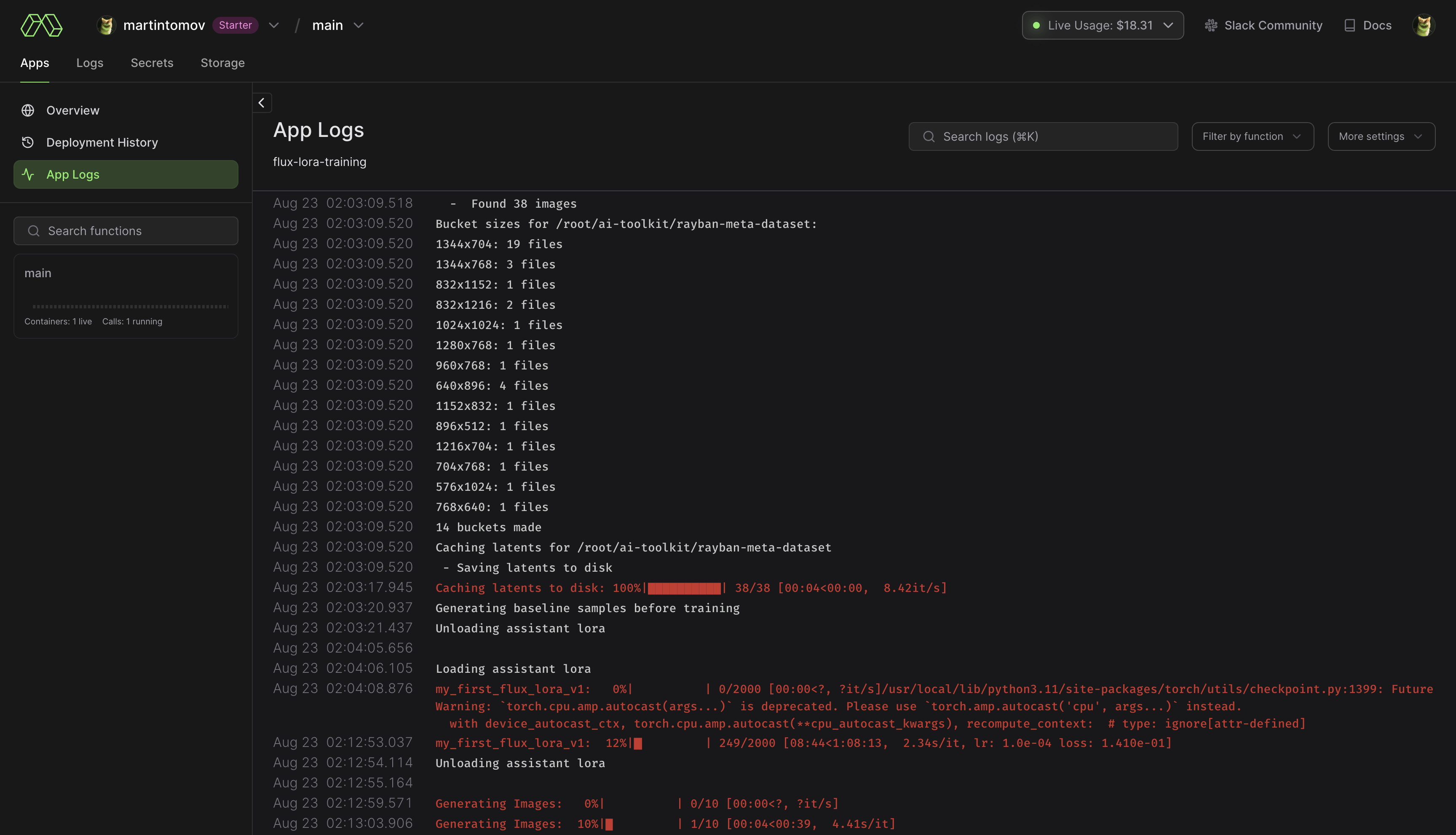
数据集通常需要是包含图像和关联文本文件的文件夹。目前,仅支持 jpg、jpeg 和 png 格式。 Webp 目前存在问题。文本文件的名称应与图像相同,但扩展名为.txt 。例如image2.jpg和image2.txt 。文本文件应仅包含标题。您可以在标题文件中添加单词[trigger] ,如果您的配置中有trigger_word ,它将被自动替换。
图像永远不会放大,但会缩小并放置在桶中进行批处理。您不需要裁剪/调整图像大小。加载器将自动调整它们的大小并可以处理不同的纵横比。
要使用 LoRA 训练特定层,您可以使用only_if_contains网络 kwargs。例如,如果您只想训练本文中提到的 The Last Ben 使用的 2 层,您可以像这样调整您的网络 kwargs:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks.7.proj_out "
- " transformer.single_transformer_blocks.20.proj_out "层的命名约定采用扩散器格式,因此检查模型的状态字典将显示要训练的层名称的后缀。您还可以使用此方法仅训练特定的重量组。例如,仅针对 FLUX.1 训练single_transformer ,您可以使用以下命令:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks. "您还可以使用ignore_if_contains网络kwarg按名称排除图层。因此,要排除所有单个变压器块,
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
ignore_if_contains :
- " transformer.single_transformer_blocks. " ignore_if_contains优先于only_if_contains 。因此,如果一个权重被两者覆盖,则 if 将被忽略。
它可能仍然可以这样工作,但我已经有一段时间没有测试它了。
一个图像生成器,可以从配置文件中获取 frompts 或形成 txt 文件并将它们生成到文件夹中。我主要需要这个用于我正在进行的 SDXL 测试,但对其进行了一些改进,以便它可以用于生成批量图像生成。这一切都运行在一个配置文件中,您可以在config/examples/generate.example.yaml中找到该配置文件的示例。仅信息位于示例的注释中
它基于 LyCORIS 工具中的提取器,但添加了一些 QOL 功能和 LoRA (lierla) 支持。它可以在一次运行中执行多种类型的提取。这一切都运行在一个配置文件中,您可以在config/examples/extract.example.yml中找到该配置文件的示例。只需将该文件复制到config文件夹中,并将其重命名为whatever_you_want.yml 。然后您可以根据自己的喜好编辑该文件。并这样称呼它:
python3 run.py config/whatever_you_want.yml如果您想将配置文件保存在其他位置,您还可以放置配置文件的完整路径。
python3 run.py " /home/user/whatever_you_want.yml "有关其工作原理的更多说明可以在示例配置文件本身中找到。 LoRA 和 LoCON 都支持提取“固定”、“阈值”、“比率”、“分位数”。稍后我将更新这些内容的作用和含义。大多数人使用fixed,这是传统的固定维度提取。
process是要运行的不同进程的数组。您可以添加一些并混合搭配。一台 LoRA、一台 LyCON 等
将<lora:my_lora:4.6>更改为<lora:my_lora:1.0>或任何您想要的具有相同效果的内容。用于重新调整 LoRA 权重的工具。 LoCON 也应该如此,但我还没有测试过。这一切都运行在一个配置文件中,您可以在config/examples/mod_lora_scale.yml中找到该配置文件的示例。只需将该文件复制到config文件夹中,并将其重命名为whatever_you_want.yml 。然后您可以根据自己的喜好编辑该文件。并这样称呼它:
python3 run.py config/whatever_you_want.yml如果您想将配置文件保存在其他位置,您还可以放置配置文件的完整路径。
python3 run.py " /home/user/whatever_you_want.yml "有关其工作原理的更多说明可以在示例配置文件本身中找到。这在制作所有 LoRA 时很有用,因为理想权重很少是 1.0,但现在您可以解决这个问题。对于滑块,它们可以具有从 -2 到 2 甚至 -15 到 15 的奇怪比例。这将允许您将其放入其中,以便它们都具有您想要的比例
这就是我在 Civitai 上训练大多数最近的滑块的方式,您可以在我的 Civitai 个人资料中查看它们。它基于 p1atdev/LECO 和 rohitgandikota/erasing 的工作,但经过大量修改以创建滑块而不是擦除概念。我对此还有很多计划,但它本身就非常实用。它也非常容易使用。只需将config/examples/train_slider.example.yml中的示例配置文件复制到config文件夹并将其重命名为whatever_you_want.yml 。然后您可以根据自己的喜好编辑该文件。并这样称呼它:
python3 run.py config/whatever_you_want.yml该示例文件中有更多信息。您甚至可以不做任何修改地按原样运行该示例,以查看它是如何工作的。它将创建一个滑块,将所有动物变成狗(负)或猫(正)。像这样运行它:
python3 run.py config/examples/train_slider.example.yml您无需配置任何内容就可以看到它是如何工作的。此方法不需要数据集。我很快就会发布更好的教程。
您现在可以制作和共享自定义扩展。在此框架内运行并拥有可用的所有内置工具。我可能会使用它作为未来的主要开发方法,所以我不会继续向这个基础存储库添加越来越多的功能。我可能还会迁移许多现有功能以使所有内容模块化。 extensions夹中有一个示例扩展,展示了如何制作模型合并扩展。所有代码都有大量文档记录,希望足以帮助您入门。要进行扩展,只需复制该示例并替换您需要的所有内容。
它位于extensions文件夹中。它是一个功能齐全的模型合并器,可以将任意数量的模型合并在一起。这是如何进行扩展的一个很好的示例,但也是一个非常有用的功能,因为大多数合并一次只能执行一个模型,而这个模型将需要您想要提供的多个模型。那里有一个示例配置文件,只需将其复制到您的config文件夹并将其重命名为whatever_you_want.yml 。并像任何其他配置文件一样使用它。
这可行,但尚未准备好供其他人使用,因此没有示例配置。我仍在努力。准备好后我会更新它。我为图像放大工作中使用的标准添加了很多功能。批评者(鉴别器)、内容丢失、风格丢失等等。如果您不知道,用于稳定扩散的 VAE(是的,甚至是 MSE 和 SDXL)对于较小的面来说非常糟糕,并且它会阻碍 SD。我会解决这个问题。稍后我将发布更多相关内容并提供更好的示例,但这里是对各种 VAE 运行的快速测试。刚刚进进出出。在较小的脸上,情况比这里显示的要糟糕得多。
extensions夹中的示例。阅读上面的更多内容。另一项重大重构使 SD 更加模块化。
制作批量图像生成脚本
主要变更和更新。新的 LoRA 重新调整工具,请查看上面的详细信息。添加了更好的元数据,以便 Automatic1111 知道基本模型是什么。添加了一些实验和大量更新。这个东西目前仍然不稳定,所以希望不会有重大变化。
不幸的是,我懒得写一个包含所有更改的正确更改日志。
我向滑块添加了 SDXL 训练...但是...它无法正常工作。滑块训练依赖于模型理解无条件(否定提示)意味着您不希望在输出中出现该概念的能力。无论出于何种原因,SDXL 都不理解这一点,这使得分离模型中的概念变得困难。我相信随着时间的推移,社区会找到解决这个问题的方法,但目前还无法正常工作。如果你们中有人在想“我们是否可以通过在模型中添加 1 或 2 个文本编码器以及一些完全独立的扩散网络来解决这个问题?”不,上帝不。它只需要一点训练,而不需要添加每一篇实验性的新论文。 KISS 校长。
向滑块训练器添加了“锚点”。这允许您设置将用作正则化器的提示。您可以设置网络乘数以强制高权重下的传播一致性


