CQN
1.0.0
重新实现从粗到细的 Q 网络 (CQN) ,这是一种用于连续控制的基于样本高效值的 RL 算法,引入于:
通过从粗到细的强化学习进行连续控制
Younggyo Seo、贾法尔·乌鲁克、斯蒂芬·詹姆斯
我们的关键思想是学习以从粗到细的方式放大连续动作空间的强化学习智能体,使我们能够训练基于价值的强化学习智能体进行连续控制,并且在每个级别上只需要很少的离散动作。
请参阅我们的项目网页 https://younggyo.me/cqn/ 了解更多信息。
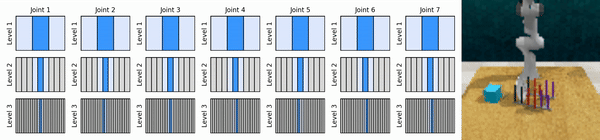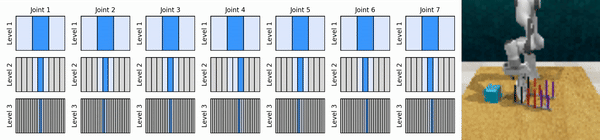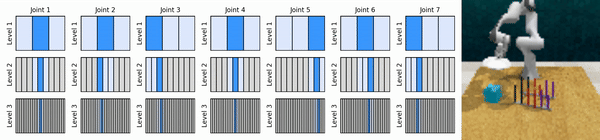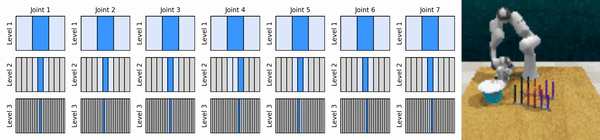
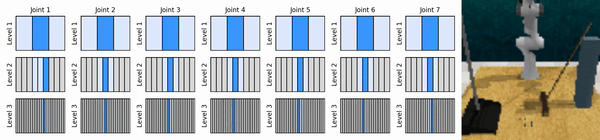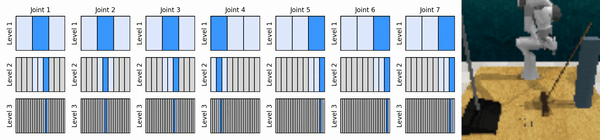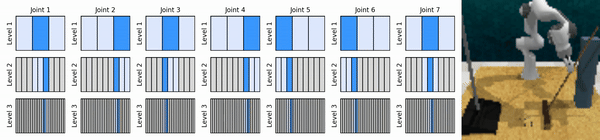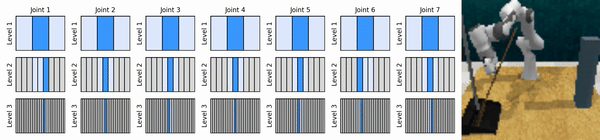
安装conda环境:
conda env create -f conda_env.yml
conda activate cqn
安装 RLBench 和 PyRep(应使用 2024 年 7 月 10 日的最新版本)。按照原始存储库中的指南进行 (1) 安装 RLBench 和 PyRep 以及 (2) 启用无头模式。 (有关安装 RLBench 的信息,请参阅 RLBench 和 Robobase 中的自述文件。)
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
预收集演示
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
运行实验 (CQN):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
运行基线实验 (DrQv2+):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
运行实验:
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
警告:CQN 未在 DMC 中进行广泛测试
该存储库基于 DrQ-v2 的公共实现
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


