TaskMatrix
1.0.0
TaskMatrix连接 ChatGPT 和一系列 Visual Foundation 模型,以实现在聊天期间发送和接收图像。
请参阅我们的论文:Visual ChatGPT:使用 Visual Foundation 模型进行对话、绘图和编辑
现在TaskMatrix 支持GroundingDINO 和segment-anything!感谢@jordddan的努力。对于图像编辑情况,首先使用GroundingDINO定位给定文本引导的边界框,然后使用segment-anything生成相关掩模,最后使用稳定扩散修复基于掩模编辑图像。
python visual_chatgpt.py --load "Text2Box_cuda:0,Segmenting_cuda:0,Inpainting_cuda:0,ImageCaptioning_cuda:0"find xxx in the image或segment xxx in the image 。 xxx是一个对象。 TaskMatrix将返回检测或分割结果!现在TaskMatrix可以支持中文了!感谢@Wang-Xiaodong1899的努力。
我们在TaskMatrix中提出了模板的想法!
template_model = True类感谢@ShengmingYin和@thebestannie在InfinityOutPainting类中提供了模板示例(参见下面的 gif)
python visual_chatgpt.py --load "Inpainting_cuda:0,ImageCaptioning_cuda:0,VisualQuestionAnswering_cuda:0"extend the image to 2048x1024 !InfinityOutPainting模板,TaskMatrix 就可以通过与现有ImageCaptioning 、 Inpainting和VisualQuestionAnswering基础模型协作将图像无缝扩展至任何尺寸,而无需额外培训。TaskMatrix需要社区的努力!我们渴望您的贡献来添加新的有趣的功能!

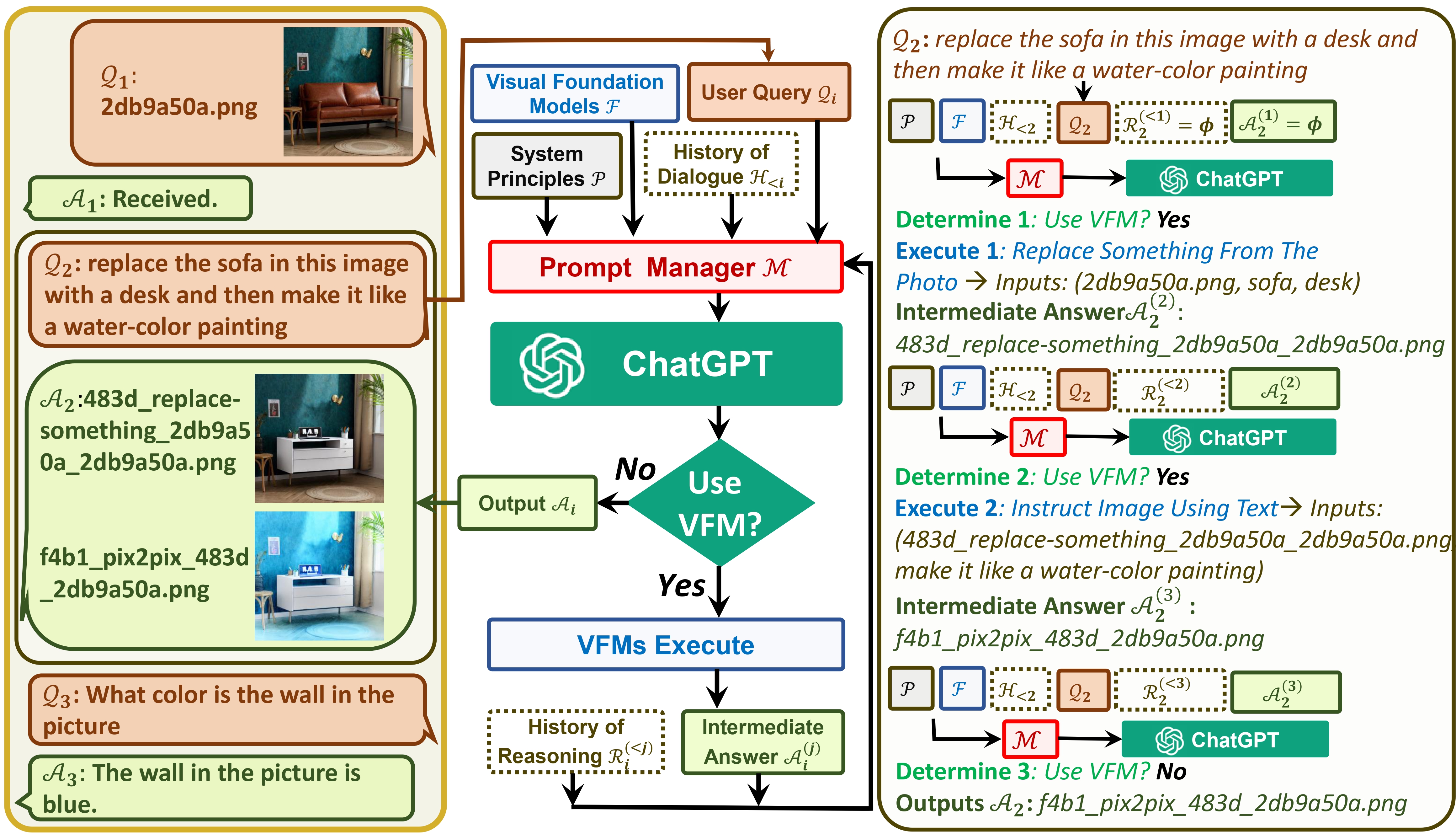
一方面, ChatGPT(或 LLM)充当通用接口,提供对广泛主题的广泛且多样化的理解。另一方面,基础模型通过提供特定领域的深入知识来充当领域专家。通过利用一般知识和深层知识,我们的目标是构建一个能够处理各种任务的人工智能。
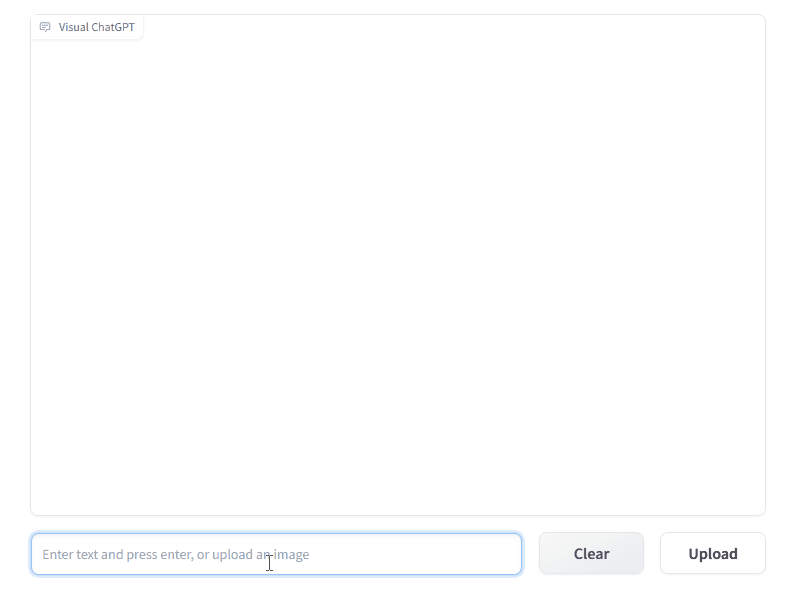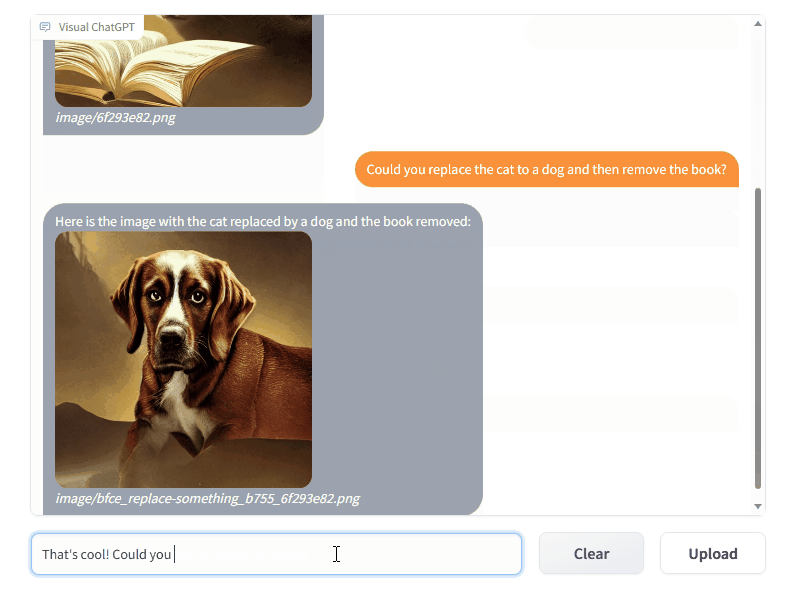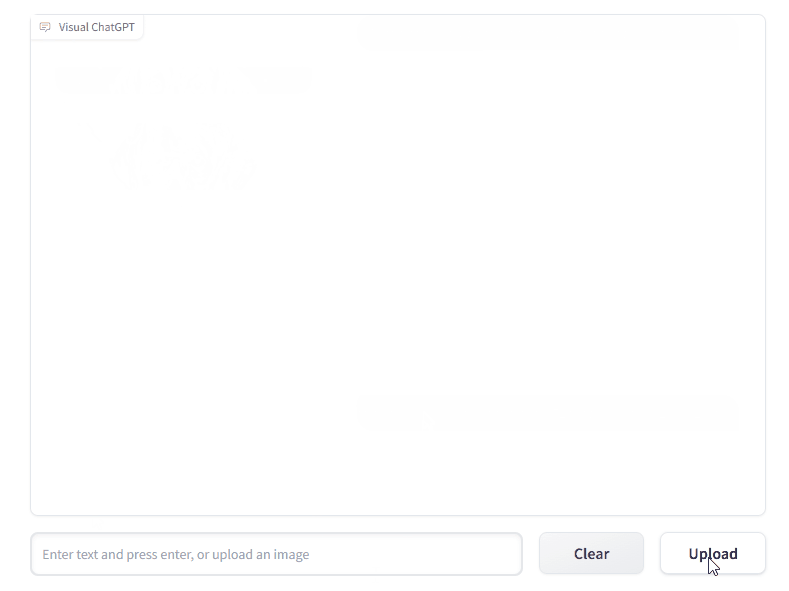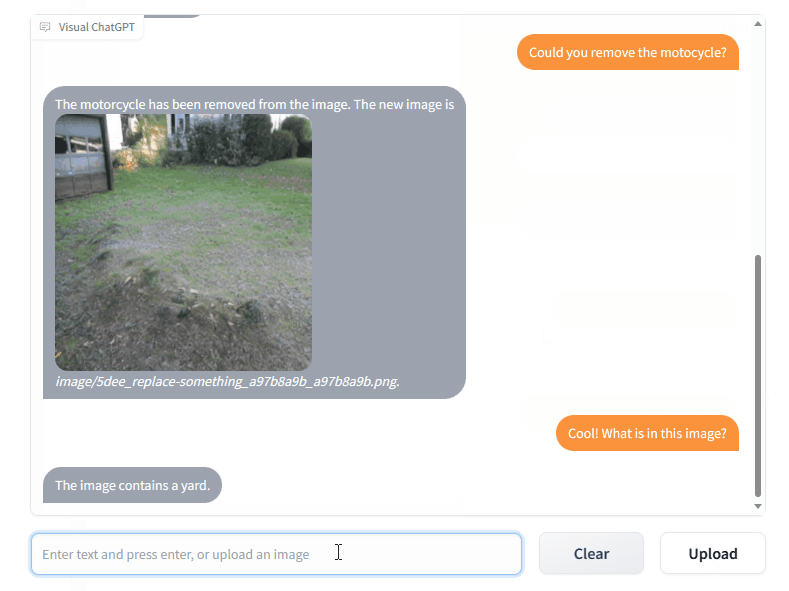
# clone the repo
git clone https://github.com/microsoft/TaskMatrix.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
pip install git+https://github.com/IDEA-Research/GroundingDINO.git
pip install git+https://github.com/facebookresearch/segment-anything.git
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start TaskMatrix !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are separated by underline '_', the different models are separated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "Text2Box_cuda:0,Segmenting_cuda:0,
Inpainting_cuda:0,ImageCaptioning_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
这里我们列出了每个 Visual Foundation 模型的 GPU 内存使用情况,您可以指定您喜欢哪一个:
| 基础模型 | GPU 内存 (MB) |
|---|---|
| 图像编辑 | 3981 |
| 指导Pix2Pix | 2827 |
| 文字转图像 | 3385 |
| 图像字幕 | 1209 |
| 图像2Canny | 0 |
| CannyText2Image | 3531 |
| 图像2线 | 0 |
| 行文字转图像 | 3529 |
| 图像2Hed | 0 |
| HedText2Image | 3529 |
| 图像2涂鸦 | 0 |
| 涂鸦文字转图像 | 3531 |
| 图像2姿势 | 0 |
| 姿势文本2图像 | 3529 |
| 图像2段 | 919 |
| 分段文本2图像 | 3529 |
| 图像2深度 | 0 |
| 深度文本2图像 | 3531 |
| 图像2法线 | 0 |
| 普通文本转图像 | 3529 |
| 视觉问答 | 1495 |
我们赞赏以下项目的开源:
拥抱脸 LangChain 稳定扩散 ControlNet InstructPix2Pix CLIPSeg BLIP
如需使用 TaskMatrix 的帮助或问题,请提交 GitHub 问题。
如需其他沟通,请联系 Chenfei WU ([email protected]) 或 Nan DUAN ([email protected])。
商标 该项目可能包含项目、产品或服务的商标或徽标。 Microsoft 商标或徽标的授权使用须遵守且必须遵循 Microsoft 的商标和品牌指南。在此项目的修改版本中使用 Microsoft 商标或徽标不得引起混淆或暗示 Microsoft 赞助。对第三方商标或徽标的任何使用均须遵守这些第三方的政策。
本 Repo 中推荐的模型只是示例,用于探索任务自动化概念的科学研究以及与 Visual ChatGPT 上发表的论文进行基准测试:使用 Visual Foundation 模型进行对话、绘图和编辑。用户可以根据自己的研究需要更换本Repo中的模型。使用本Repo推荐的模型时,需要分别遵守这些模型的License。对于因您使用此存储库而导致的任何第三方权利侵权,Microsoft 不承担任何责任。用户同意对与本存储库引起的任何索赔相关的所有损害、费用和律师费进行辩护、赔偿并使 Microsoft 免受损害。如果有人认为此 Repo 侵犯了您的权利,请通知项目所有者电子邮件。


