TEMPO
1.0.0

[“TEMPO:用于时间序列预测的基于提示的生成预训练变压器(ICLR 2024)”]的官方代码。
TEMPO 是最早用于预测任务 v1.0 版本的开源时间序列基础模型之一。
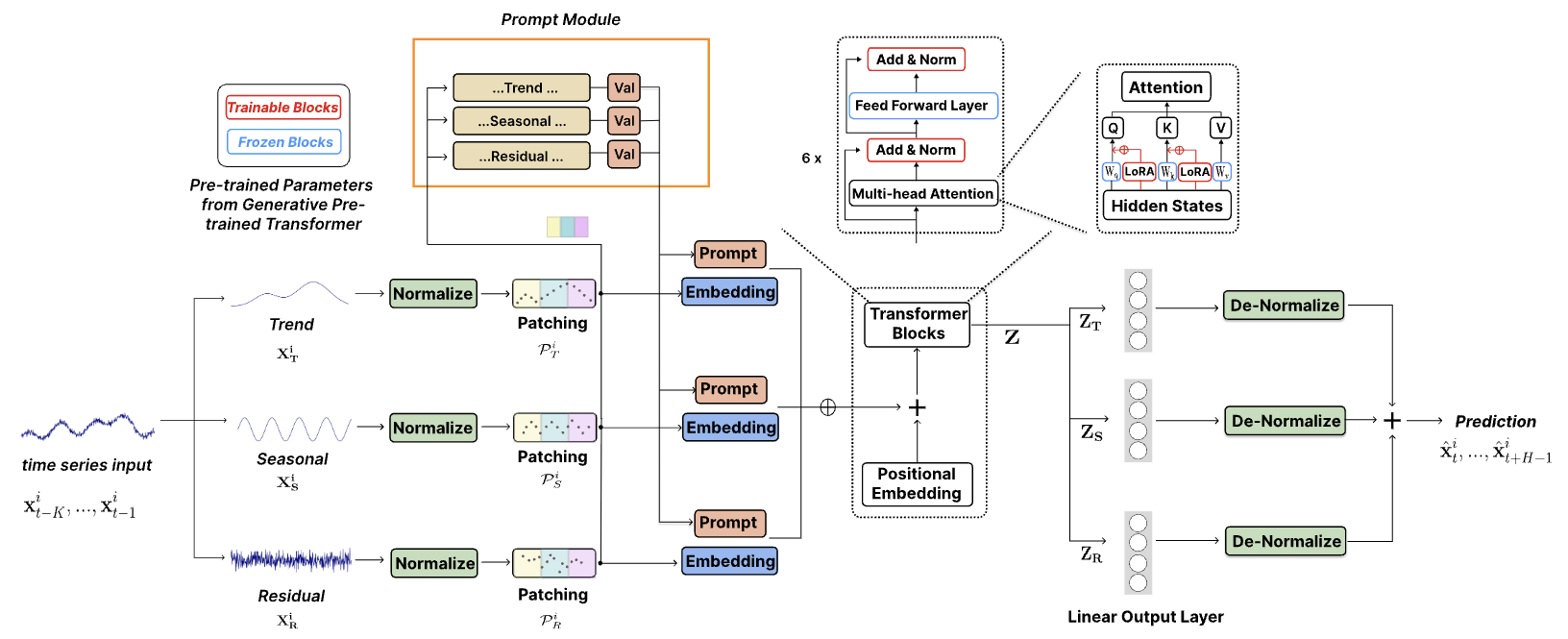
2024 年 10 月:我们简化了代码结构,使用户能够下载预训练的模型并用一行代码执行零样本推理!查看我们的演示以了解更多详细信息。我们的模型在 HuggingFace 上的下载计数现在可以追踪!
2024 年 6 月:我们添加了用于在 Colab 中重现零样本实验的演示。我们还添加了构建客户数据集的演示,并通过我们预先训练的基础模型直接进行推理:Colab
2024年5月:TEMPO推出了基于GUI的在线演示,允许用户直接与我们的基础模型进行交互!
2024年5月:TEMPO在HuggingFace上发布了80M预训练基础模型!
2024 年 5 月:?我们添加了预训练和推理 TEMPO 模型的代码。您可以在此文件夹中找到预训练脚本演示。我们还添加了一个用于推理演示的脚本。
2024 年 3 月:?发布了 S&P 500 的 TETS 数据集,用于 TEMPO 的多模态实验。
2024 年 3 月:? TEMPO 在线发布了项目代码和预训练检查点!
2024年1月:TEMPO论文被ICLR接收!
2023 年 10 月:TEMPO 论文在 Arxiv 上发布!
conda create -n tempo python=3.8
conda activate tempo
pip install -r requirements.txt
展示如何使用 TEMPO 执行预测的简化示例:
# Third-party library imports
import numpy as np
import torch
from numpy . random import choice
# Local imports
from models . TEMPO import TEMPO
model = TEMPO . load_pretrained_model (
device = torch . device ( 'cuda:0' if torch . cuda . is_available () else 'cpu' ),
repo_id = "Melady/TEMPO" ,
filename = "TEMPO-80M_v1.pth" ,
cache_dir = "./checkpoints/TEMPO_checkpoints"
)
input_data = np . random . rand ( 336 ) # Random input data
with torch . no_grad ():
predicted_values = model . predict ( input_data , pred_length = 96 )
print ( "Predicted values:" )
print ( predicted_values )请尝试在 ETTh2 上重现零样本实验 [在 Colab 上]。
我们使用以下 Colab 页面来展示构建客户数据集的演示,并通过我们预先训练的基础模型直接进行推理:[Colab]
请尝试我们的基础模型演示[此处]。
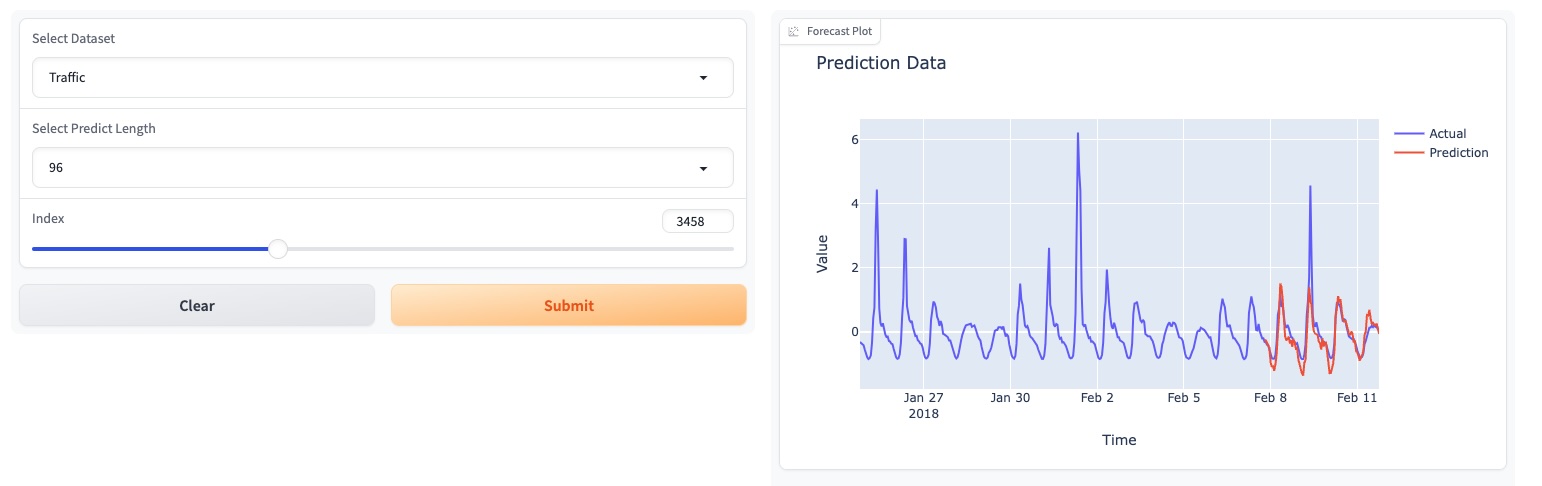
我们还在 HuggingFace 上更新了我们的模型:[Melady/TEMPO]。
从[Google Drive]或[Baidu Drive]下载数据,并将下载的数据放在文件夹./dataset中。您还可以从[Google Drive]下载STL结果,并将下载的数据放在文件夹./stl中。
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather].sh
训练完成后,我们可以在零样本设置下测试 TEMPO 模型:
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather]_test.sh
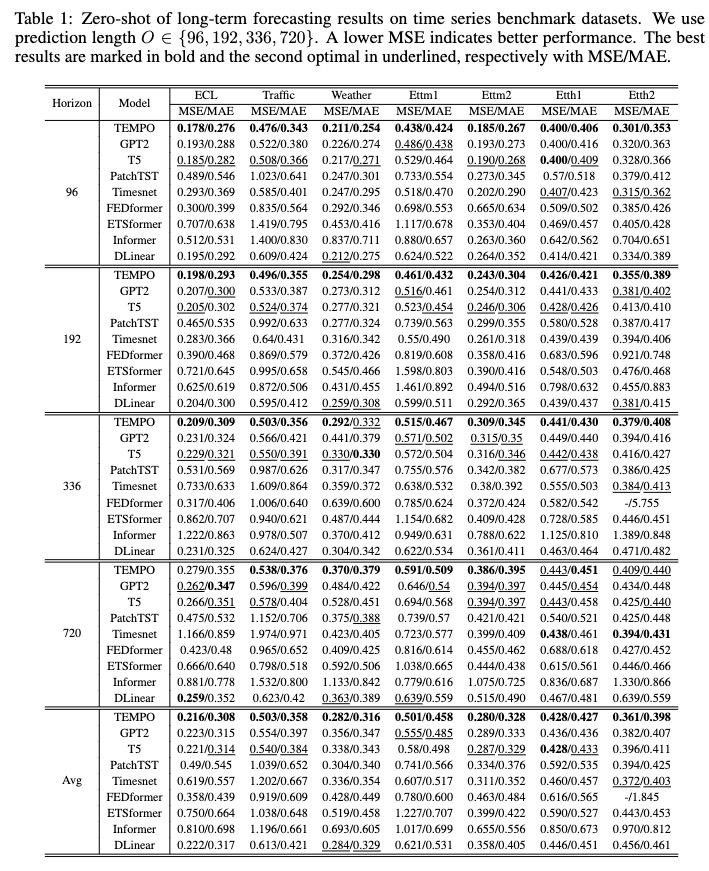
您可以从[Google Drive]下载预训练的模型,然后运行测试脚本以获取乐趣。
这里是通过【OPENAI ChatGPT-3.5 API】生成对应的时间序列文本信息的提示

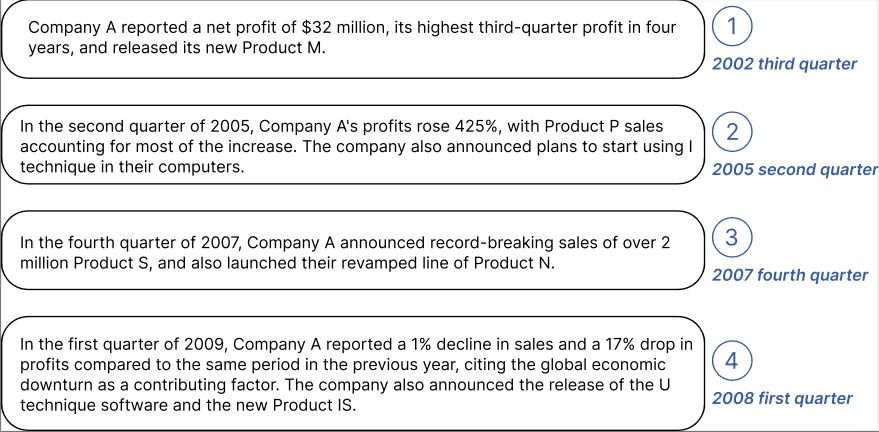
时间序列数据来自[S&P 500]。以下是数据集中一家公司的 EBITDA 案例:
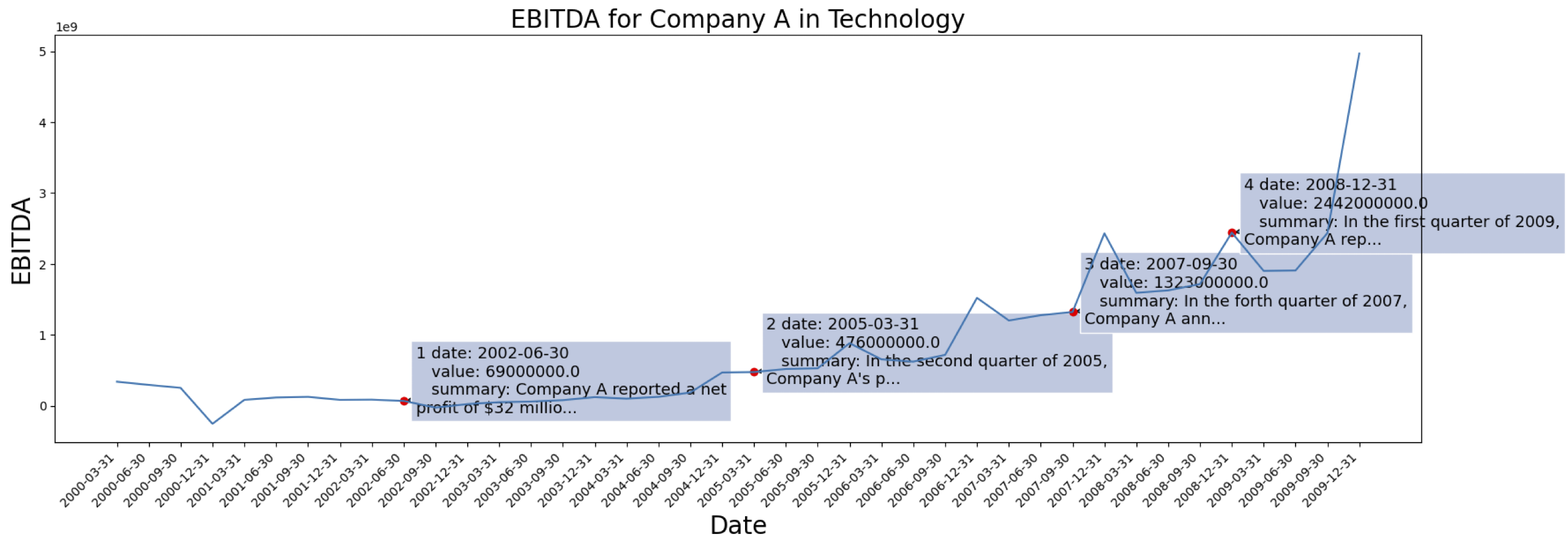
为上面标记的公司生成的上下文信息示例:
您可以从 GPT2 下载带有文本嵌入的已处理数据:[TETS]。
如果您有兴趣将 TEMPO 应用到实际应用中,请随时联系 [email protected] / [email protected]。
@inproceedings{
cao2024tempo,
title={{TEMPO}: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting},
author={Defu Cao and Furong Jia and Sercan O Arik and Tomas Pfister and Yixiang Zheng and Wen Ye and Yan Liu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=YH5w12OUuU}
}
@article{
Jia_Wang_Zheng_Cao_Liu_2024,
title={GPT4MTS: Prompt-based Large Language Model for Multimodal Time-series Forecasting},
volume={38},
url={https://ojs.aaai.org/index.php/AAAI/article/view/30383},
DOI={10.1609/aaai.v38i21.30383},
number={21},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Jia, Furong and Wang, Kevin and Zheng, Yixiang and Cao, Defu and Liu, Yan},
year={2024}, month={Mar.}, pages={23343-23351}
}


