gpt3 poc tutorial with braindump
1.0.0
更新(2023 年 11 月):首选新的 GPT-3.5-Turbo 版本。我添加了支持聊天完成 API 的新版本(使用 GPT-3.5-Turbo 进行测试)。适当的子文件夹( gpt-3 、 gpt-35-turbo )现在包含原始版本和新版本。除了模型更改和相应调整之外,它们是相同的,但首选gpt-35-turbo ,因为 GPT-3 补全已弃用。
Braindump 是一个原型应用程序,用于记录笔记并将其转换为更容易查询的数据库。只需输入您的想法,应用程序就会对其进行正确分类、切片和存储以供以后使用。它是作为演示构建的,旨在展示如何利用 GPT-3 从概念验证开始构建应用程序,如我的 Data Science @ Microsoft 教程“构建 GPT-3 应用程序 - 超越提示”中所述。您可以使用它来遵循教程,也可以将其作为您自己的研究和应用的起点(例如,通过在您自己的不同问题中重用实用函数和总体程序结构)。
它是一个简单的 Python 应用程序,利用 Streamlit 提供 Web 界面。要实际调用 GPT-3 模型,您需要有一个可用的 OpenAI API 密钥。在撰写本文时,创建帐户后,您将获得一些免费积分,这些积分足以遵循教程并开始使用该应用程序。该应用程序还应该与 Azure OpenAI 服务一起使用,而不是原始的 OpenAI 产品,尽管我尚未在那里进行测试。
除了应用程序本身之外,该存储库还包括导致该应用程序的 Jupyter 笔记本形式的研究。
搜索的 UI 如下所示: 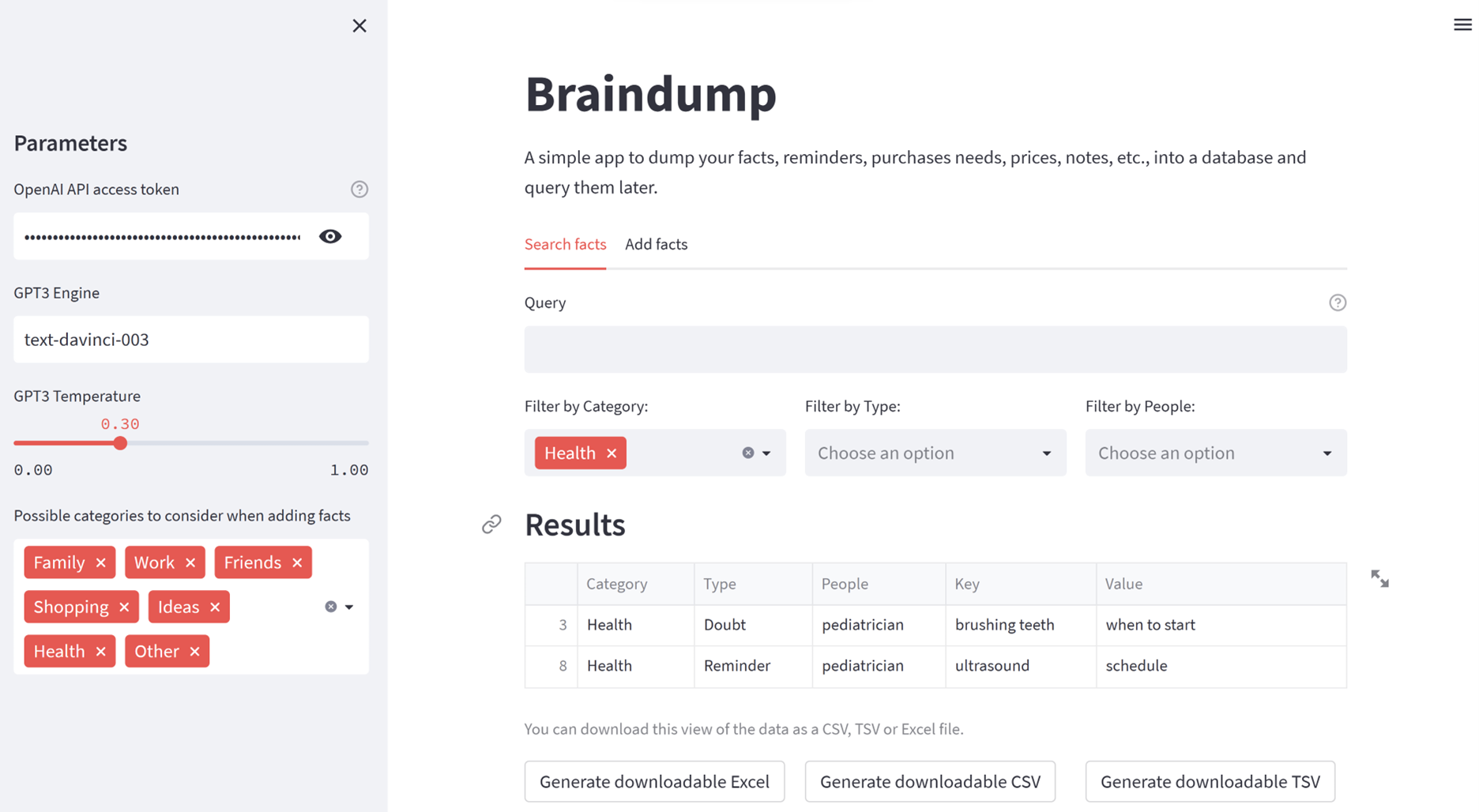
要添加事实,UI 如下,包括可选的模型解释手动检查: 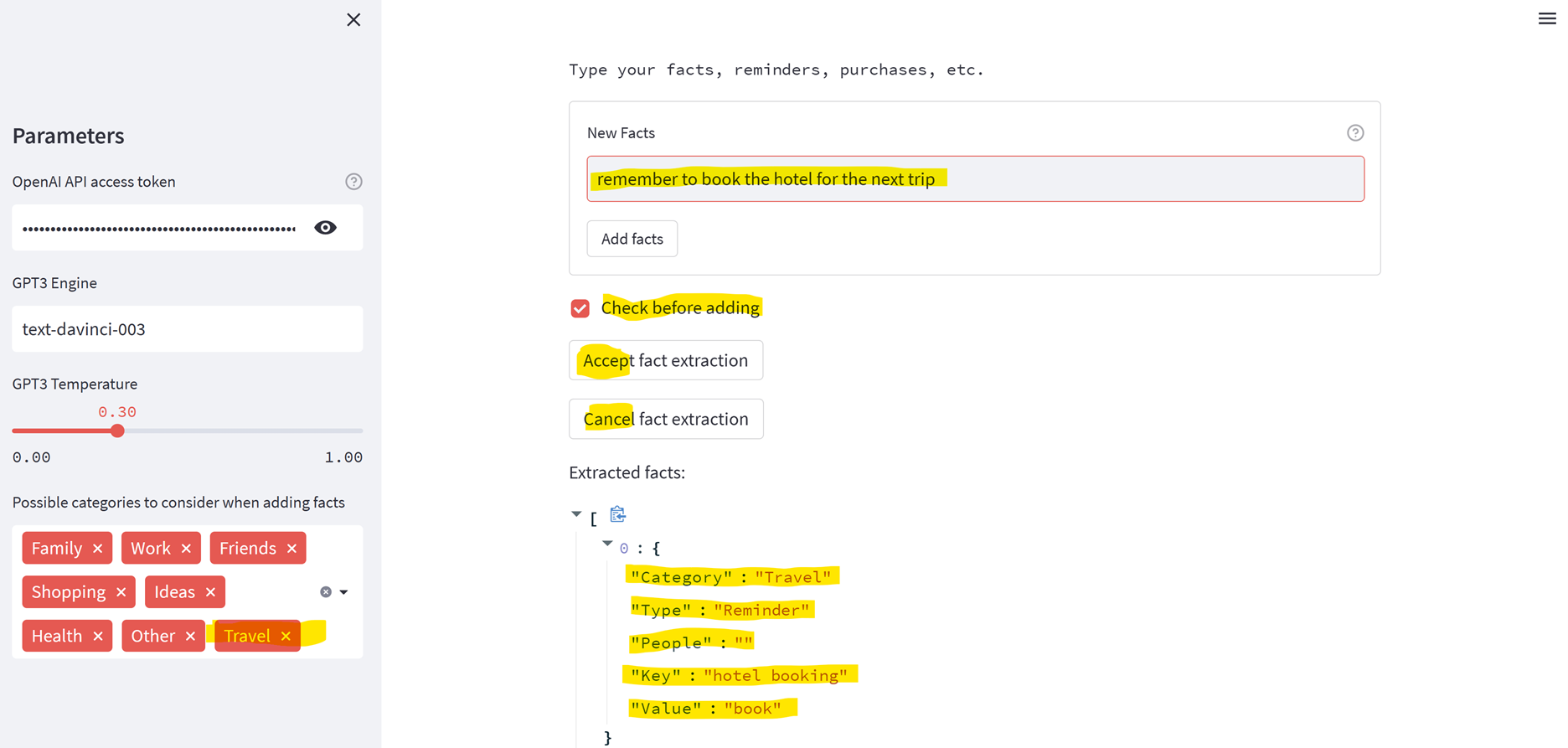
该应用程序已在 Python 3.8 (GPT-3) 和 3.10 (GPT-3.5-Turbo) 上进行了测试。您需要的主要库是: openai 、 streamlit 、 pandas 、 notebook 、 pytest 。您可以手动安装它们,也可以按照以下过程创建新环境并自动安装它们。请注意,对于较旧的代码库,您将需要旧版本的openai库。
运行应用程序:
conda create -n braindump_py310 python=3.10专门为此应用程序创建一个新环境conda activate braindump_py310激活新环境requirements.txt中列出的依赖项。您可以通过从项目根目录运行pip install -r requirements.txt来完成此操作。对于原始 GPT-3 版本(已弃用),请改用requirements.gpt3.txt ,以获取其操作所需的旧依赖项。OPENAI_API_KEY的环境变量提供。run.gpt3.bat (GPT-3 版本)或run.gpt35turbo.bat (GPT-3.5-Turbo 版本);在 Linux 上: run.gpt3.sh (GPT-3 版本)或run.gpt35turbo.sh (GPT-3.5-Turbo 版本)。进行研究:
notebooks/下打开所需的 Jupyter 笔记本(就我个人而言,我经常使用 VS Code)。 该项目的结构如下:
notebooks/ :用于即时工程的 Jupyter 笔记本。src/ :最终应用程序的源代码。src/gpt-3 :原始 GPT-3 版本的来源(已弃用)。src/gpt-3.5-turbo :GPT-3.5-Turbo 版本的来源(自 2023 年 11 月起推荐)。data/ :应用程序存储的数据。tests/ :应用程序的单元测试。tests/gpt-3/ :测试原始 GPT-3 版本(已弃用)。tests/gpt-3.5-turbo/ :GPT-3.5-Turbo 版本的测试(自 2023 年 11 月起推荐)。docs/ :文档和相关资产。 该方法在我的 Data Science @ Microsoft 教程“构建 GPT-3 应用程序 - 超越提示”中详细介绍。尽管如此,让我在这里强调一些关键点:
就具体阶段而言,建议采取以下措施
麻省理工学院许可证
版权所有 (c) 2023 保罗·萨勒姆·达席尔瓦
特此免费授予获得本软件和相关文档文件(“软件”)副本的任何人不受限制地使用本软件,包括但不限于使用、复制、修改、合并的权利、发布、分发、再许可和/或销售软件的副本,并允许向其提供软件的人员这样做,但须满足以下条件:
上述版权声明和本许可声明应包含在本软件的所有副本或主要部分中。
本软件按“原样”提供,不提供任何明示或暗示的保证,包括但不限于适销性、特定用途的适用性和不侵权的保证。在任何情况下,作者或版权持有者均不对因本软件或本软件的使用或其他交易而引起的或与之相关的任何索赔、损害或其他责任负责,无论是合同、侵权还是其他行为。软件。


