microGPT
1.0.0
microGPT 是用于自然语言处理任务的生成式预训练 Transformer (GPT) 模型的轻量级实现。它的设计简单且易于使用,使其成为小型应用程序或学习和实验生成模型的绝佳选择。
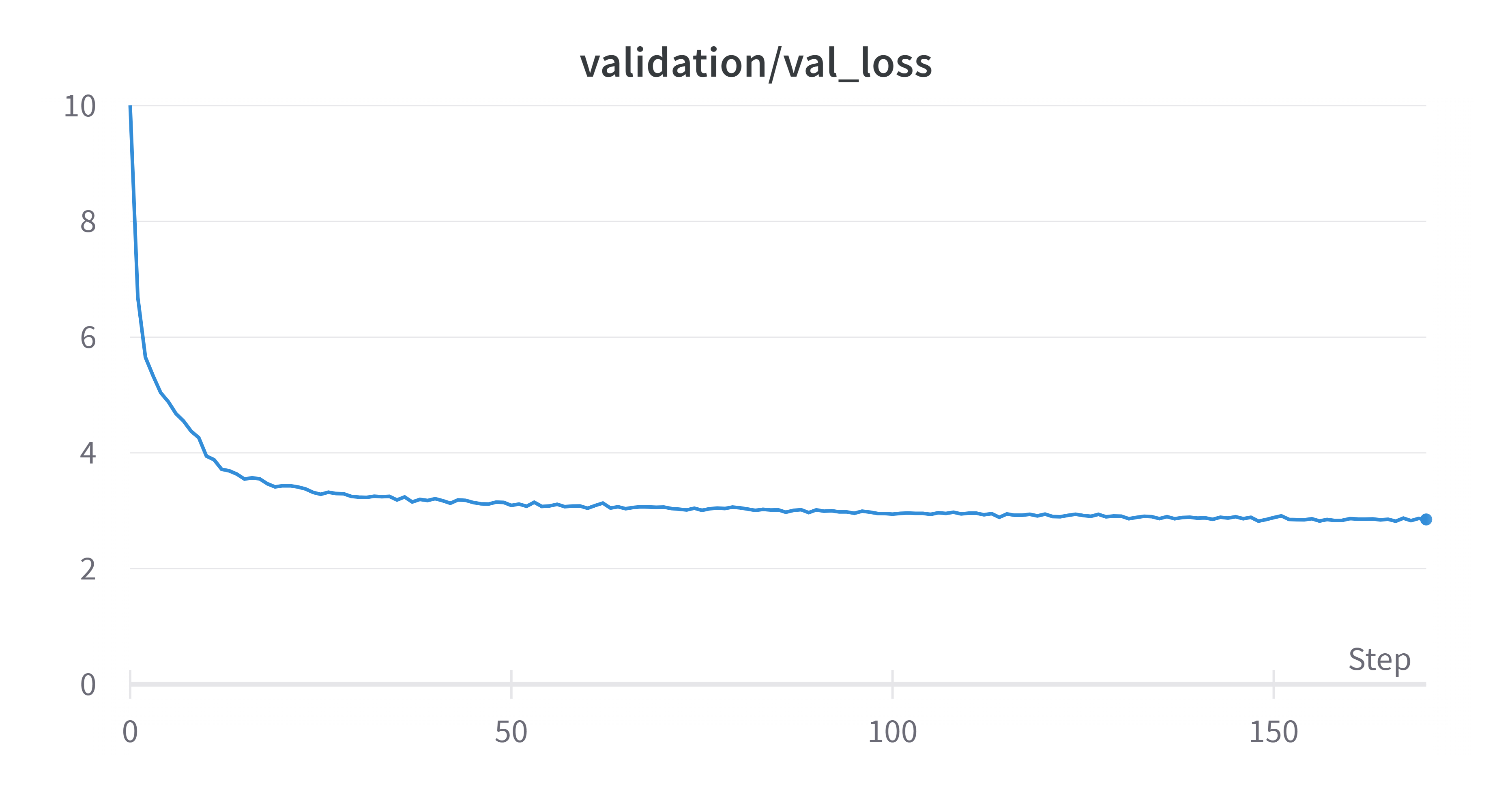 300k 次训练迭代
300k 次训练迭代
pip install -r requirements.txt tokenizer/train_tokenizer.py以生成 tokenizer 文件。该模型将基于它对文本进行标记。datasets/prepare_dataset.py生成数据集文件。train.py开始训练~如果您想更改其参数,请修改上述文件。
要编辑模型生成参数,请从inference.py转到此部分:
# Parameters (Edit here):
n_tokens = 1000
temperature = 0.8
top_k = 0
top_p = 0.9
model_path = 'models/microGPT.pth'
# Edit input here
context = "The magical wonderland of"有兴趣部署为网络应用程序吗?查看 microGPT 部署!
从头开始的效率:从头开始开发的 microGPT 代表了受人尊敬的 GPT 模型的简化方法。它展示了卓越的效率,同时在质量上保持了轻微的权衡。
学习游乐场: microGPT 的架构专为渴望深入人工智能世界的个人而设计,提供了掌握生成模型内部运作的独特机会。它是磨练您的技能和加深您的理解的启动板。
小型动力室:除了学习和实验之外,microGPT 也是小型应用程序的合适选择。它使您能够将人工智能驱动的语言生成集成到效率和性能至关重要的项目中。
定制能力: microGPT 的适应性使您能够修改和微调模型以满足您的特定目标,为创建适合您的要求的 AI 解决方案提供了画布。
学习之旅:使用 microGPT 作为理解生成模型基础的垫脚石。其易于访问的设计和文档为人工智能新手提供了理想的环境。
实验实验室:通过调整和测试 microGPT 的参数来参与实验。该模型的简单性和多功能性为创新提供了肥沃的土壤。
如果您想做出贡献,请遵循以下准则:
通过向此存储库做出贡献,您同意遵守我们的行为准则,并且您的贡献将在与存储库相同的许可证下发布。
该模型的灵感来自 Andrej Karpathy 让我们从头开始构建 GPT 视频和 Andrej Kaparthy nanoGPT 并对此项目进行了修改。


