AMRICA
1.0.0
AMRICA(跨语言对齐的 AMR 检查器)是一个简单的工具,用于对齐和直观地表示 AMR(Banarescu,2013),既适用于双语环境,也适用于单语注释者间协议。它基于并扩展了用于识别 AMR 互注释器协议的 Smatch 系统(Cai,2012)。
还可以使用 AMRICA 来可视化您自己编辑或编译的手动对齐(请参阅通用标志)。
从 github 下载 python 源代码。
我们假设您有pip 。要安装依赖项(假设您已经有下面提到的 graphviz 依赖项),只需运行:
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz需要 graphviz 才能工作。在 Linux 上,您可能必须安装graphviz libgraphviz-dev pkg-config 。此外,要准备双语对齐数据,您将需要 GIZA++,可能还需要 JAMR。
./disagree.py -i sample.amr -o sample_out_dir/
此命令将读取sample.amr中的AMR(用空行分隔)并将其graphviz可视化放入位于sample_out_dir/ .png文件中。
为了生成 Smatch 比对的可视化,我们需要一个 AMR 输入文件,其中每个::tok或::snt字段包含标记化句子, ::id字段具有句子 ID,以及::annotator或::anno字段具有注释器 ID。特定句子的注释按顺序列出,第一个注释被认为是可视化目的的黄金标准。
如果您只想可视化每个句子的单个注释而无需注释器间达成一致,则可以使用仅具有单个注释器的 AMR 文件。在这种情况下,注释者和句子 ID 字段是可选的。生成的图形将是全黑的。
对于双语对齐,我们从两个 AMR 文件开始,一个包含目标注释,另一个包含相同顺序的源注释,每个注释都有::tok和::id字段。如果我们想要任一侧的 JAMR 对齐,我们将其包含在::alignments字段中。
句子对齐应采用两个 GIZA++ 对齐 .NBEST 文件的形式,一个源-目标文件,一个目标-源文件。要生成这些,请使用 GIZA++ 配置文件中的 --nbestalignments 标志设置为您首选的 nbest 计数。
可以在命令行或配置文件中设置标志。配置文件的位置可以在命令行中使用-c CONF_FILE设置。
除了--conf_file之外,还有其他几个标志适用于单语和双语文本。 --outdir DIR是唯一必需的,它指定我们将写入图像文件的目录。
可选的共享标志是:
--verbose在对齐句子时打印它们。--no-verbose覆盖详细的默认设置。--json FILE.json将对齐图写入 .json 文件。--num_restarts N指定 Smatch 应执行的随机重新启动次数。--align_out FILE.csv将对齐写入文件。--align_in FILE.csv从磁盘读取比对而不是运行 Smatch。--layout将布局参数修改为graphviz。对齐 .csv 文件采用以下格式:每个图形匹配集均由空行分隔,并且集合内的每一行包含注释或指示对齐的行。例如:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
制表符分隔的字段是测试节点索引(由 Smatch 处理)、测试节点标签、黄金节点索引和黄金节点标签。
单语言对齐需要一个附加标志--infile FILE.amr ,其中FILE.amr设置为 AMR 文件的位置。
以下是一个示例配置文件:
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
在双语对齐中,需要更多的标志。
--src_amr FILE 。--tgt_amr FILE 。--align_tgt2src FILE.A3.NBEST用于将目标到源对齐的 GIZA++ .NBEST 文件(目标为 vcb1),使用--nbestalignments N生成--align_src2tgt FILE.A3.NBEST用于将源到目标对齐的 GIZA++ .NBEST 文件(源为 vcb1),使用--nbestalignments N生成现在,如果--nbestalignments N设置为 >1,我们应该使用--num_aligned_in_file指定它。如果我们只想计算顶部--num_align_read 。
--nbestalignments是一个使用起来很棘手的标志,因为它只会在最终的对齐运行中生成。我只能自己让它使用默认的 GIZA++ 设置。
由于 AMRICA 是 Smatch 的一种变体,因此应该首先了解 Smatch。 Smatch 尝试识别同一句子的两个 AMR 表示的变量节点之间的匹配,以衡量注释者间的一致性。应选择匹配以最大化 Smatch 分数,该分数为两个图中出现的每条边分配一个点,分为三类。每个类别都在下面的“没多久”注释中进行了说明。
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10)(ARG0, t, i)(polarity, l2, -)由于寻找使 Smatch 得分最大化的匹配问题是 NP 完全问题,因此 Smatch 使用爬山算法来逼近最佳解。它通过将每个节点与共享其标签的节点(如果可能)匹配并随机匹配较小图中的其余节点(以下称为目标)来进行播种。然后,Smatch 执行一个步骤,通过切换两个目标节点的匹配或将匹配从其源节点移动到不匹配的源节点来查找最能增加分数的操作。它重复此步骤,直到没有任何步骤可以立即增加 Smatch 分数。
为了避免局部最优,Smatch一般会重启5次。
有关 AMRICA 内部运作的技术细节,阅读我们的 NAACL 演示论文可能更有用。
AMRICA 首先将所有常量节点替换为变量节点,这些变量节点是常量标签的实例。这是必要的,以便我们可以对齐常量节点和变量。因此,添加到 AMRICA 分数中的唯一点将来自匹配变量-变量边缘和实例标签。
虽然 Smatch 尝试将较小图中的每个节点与较大图中的某个节点进行匹配,但 AMRICA 会删除不会增加修改后的 Smatch 分数或 AMRICA 分数的匹配。
然后 AMRICA 从比对的 graphviz 图中生成图像文件。如果节点或边仅出现在黄金数据中,则它是红色的。如果该节点或边仅出现在测试数据中,则它是蓝色的。如果节点或边在我们的最终对齐中匹配,则它是黑色的。
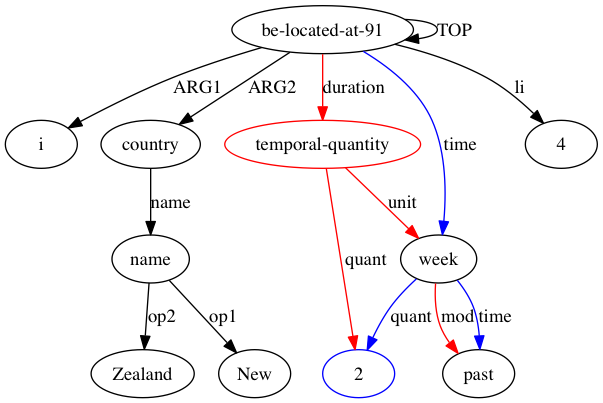
在 AMRICA 中,我们不是为每个完美匹配的实例标签添加一个点,而是根据这些标签对齐的似然得分添加一个点。似然得分 ℓ(aLt,Ls[i]|Lt,Wt,Ls,Ws) 与目标标签集 Lt、源标签集 Ls、目标句子 Wt、源句子 Ws 和对齐 aLt,Ls[i] 映射 Lt[ i] 到某个标签 Ls[aLt,Ls[i]] 上,是根据以下规则定义的可能性计算的:
一般来说,双语 AMRICA 似乎比单语 AMRICA 需要更多的随机重启才能表现良好。可以使用标志--num_restarts修改此重新启动计数。
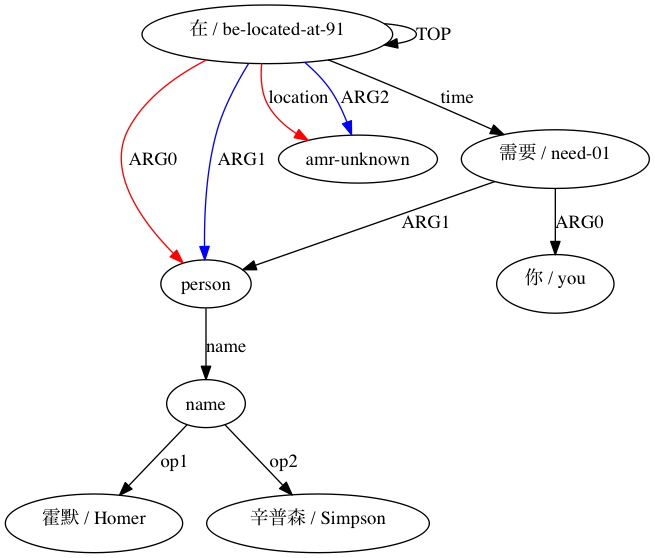
我们可以观察到使用类似 Smatch 的近似(此处使用 20 个随机初始化)比从原始对齐数据中选择可能的匹配(智能初始化)提高了准确性。对于(Xue 2014)声明结构兼容的配对。
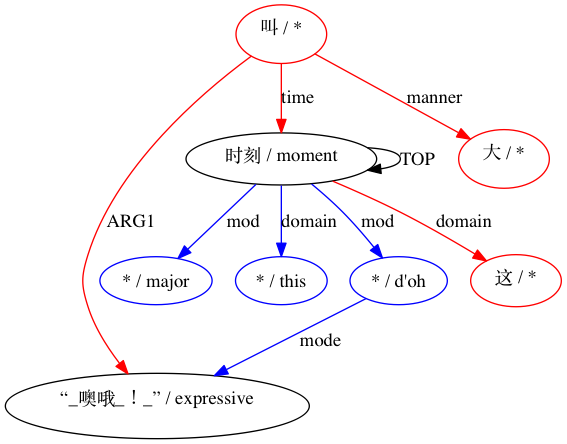
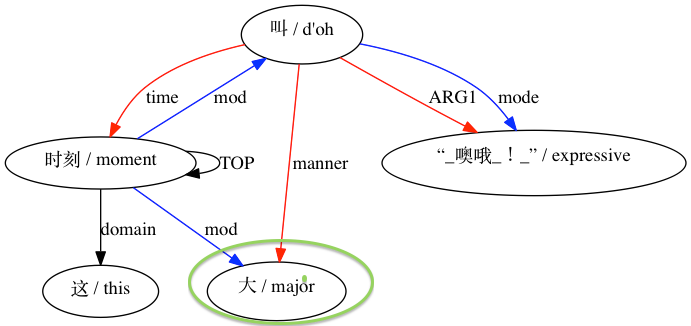
对于被认为不兼容的配对:
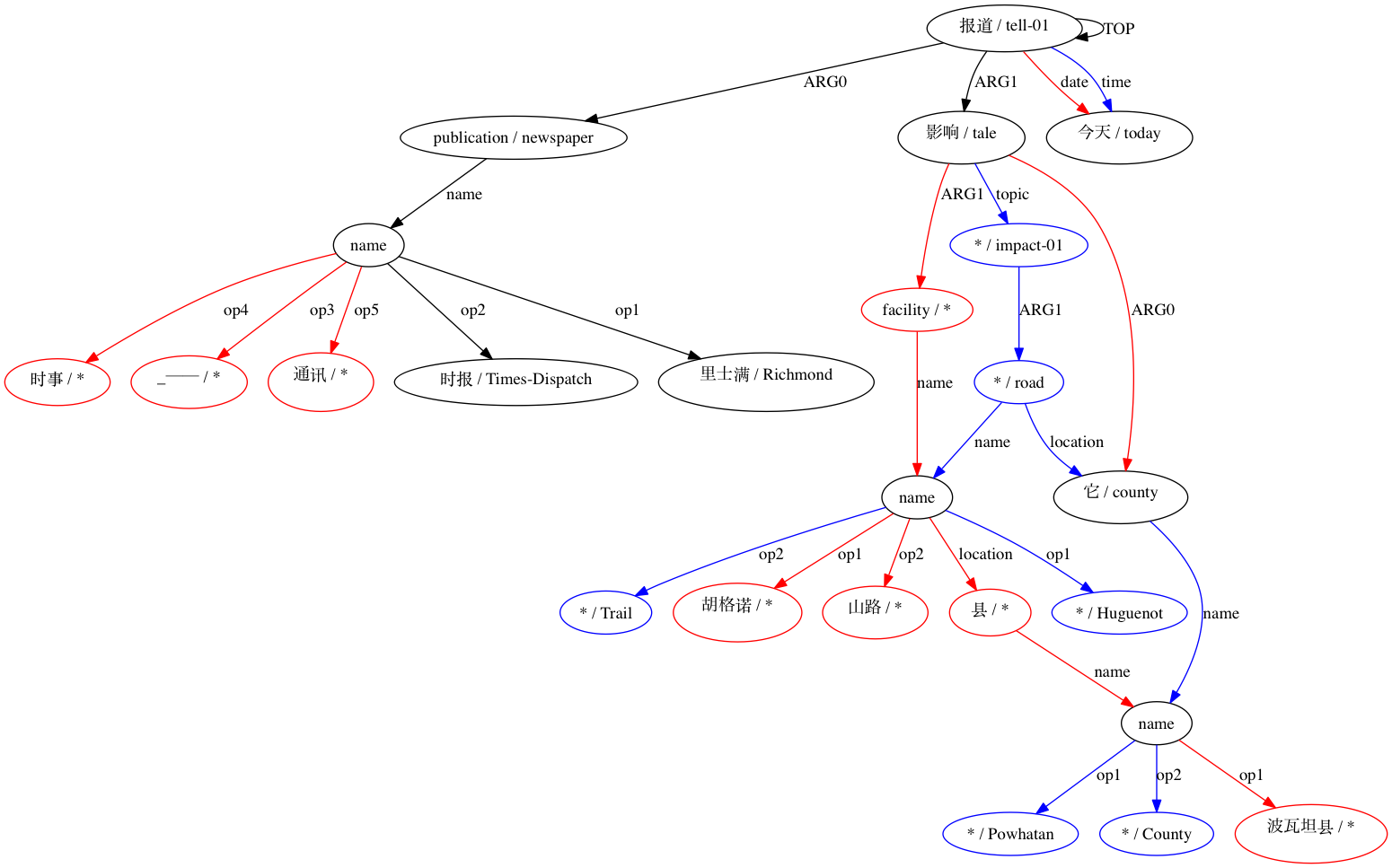
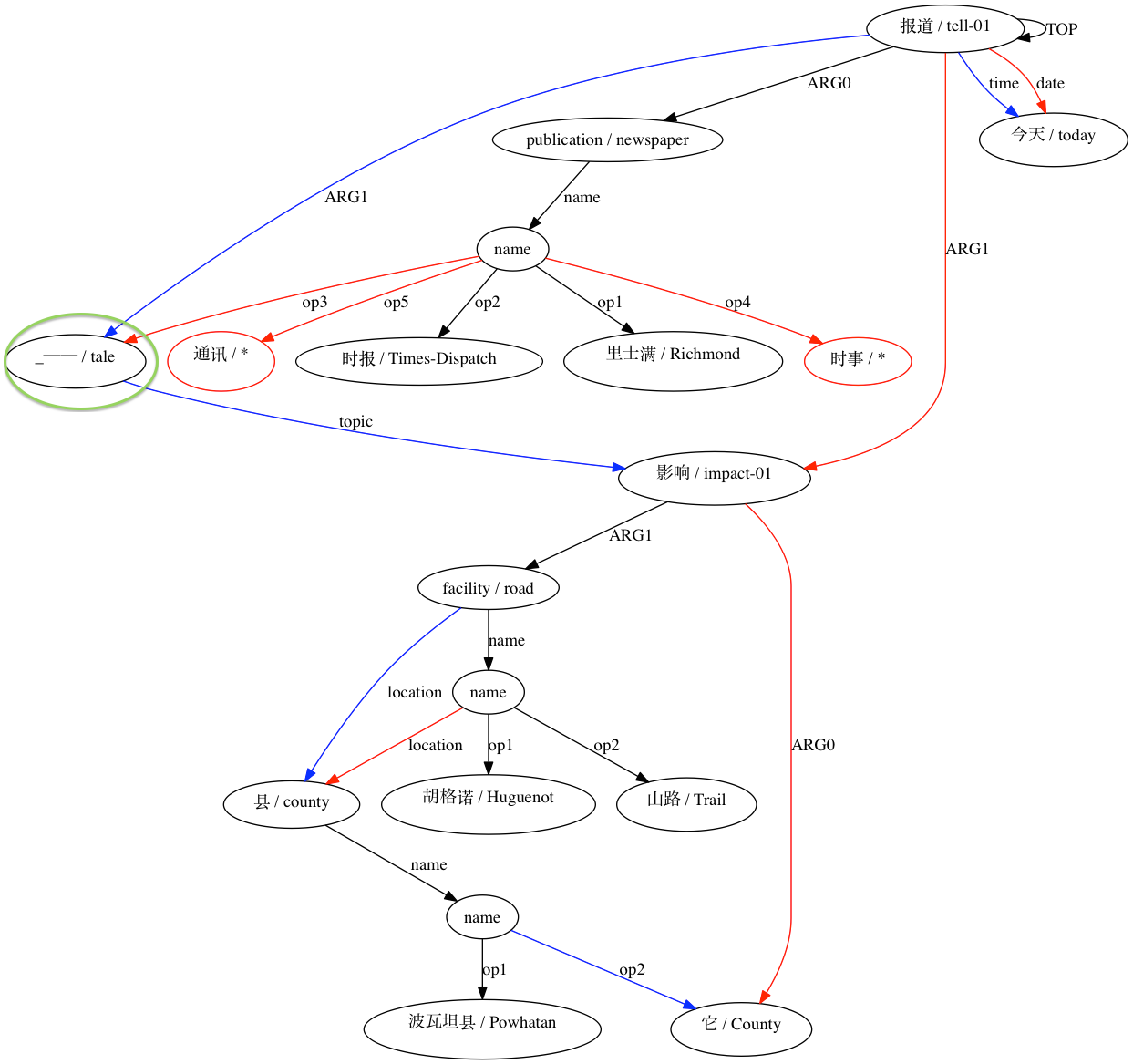
该软件的开发部分得到了国家科学基金会(美国)的支持,奖项为 1349902 和 0530118。爱丁堡大学是一家慈善机构,在苏格兰注册,注册号为 SC005336。


