llmjudge
1.0.0
在开放式场景中评估法学硕士很困难,越来越多的人认为缺乏现有基准,经验丰富的从业者更喜欢亲自检查模型。我参考了我信任的开发人员和研究人员的轶事评估,而 Chatbot Arena 是一个很好的补充。这个 repo 背后的动机是使用强大的 LLM 作为模型判断的越来越流行的方法。这种方法已经存在了几个月,包括 JudgeLM 和最近的 MT-Bench 等模型。
您可能看过也可能没有看过这个帖子。根据 Arize AI 推文的作者,使用法学硕士作为法官需要谨慎对待服务器,特别是在使用数字分数评估方面。法学硕士似乎在处理连续范围方面非常糟糕,当提示他们评估从 1 到 10 的X时,这一点变得非常明显。这个 repo 是试图理解和捕捉这个问题的锯齿状边界的实验的活生生的文档。最近的工作在 MT-Bench 和人类判断 (Arena Elo) 之间建立了很强的相关性,这意味着法学硕士有能力担任法官,那么这是怎么回事呢?
以下是完整的详细信息和结果。
由于成本限制,我最初将重点关注推文中描述的拼写/拼写错误任务。我有点担心这个任务的定量 X 会影响这个实验的见解,但我们会看到的。我欢迎对这一现象进行更全面的分析,鉴于实验有限,我的结果应该持保留态度
我从 Paul Graham 的文章中生成了一个拼写或拼写错误的数据集,不确定哪个名称更合适。这种选择主要是出于方便,因为我之前在压力测试上下文窗口时使用过该数据集。我从论文中提取了 3,000 个单词的上下文,并根据所需的拼写错误率在随机单词上插入拼写错误。在伪代码中:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
完整的代码可以作为笔记本轻松获得。
给定生成的数据集,我们提示法学硕士使用不同的评分模板评估上下文中拼写错误的单词数量。我们使用以下 API
GPT-4: gpt-4-0125-preview
GPT-3.5: gpt-3.5-turbo-1106
在温度 = 0 时。
测试 1.让我们确认法学硕士很难在零样本设置中处理数字范围。我们使用数字评分模板提示 GPT-3.5 和 GPT-4,范围从 0 分到 10 分。
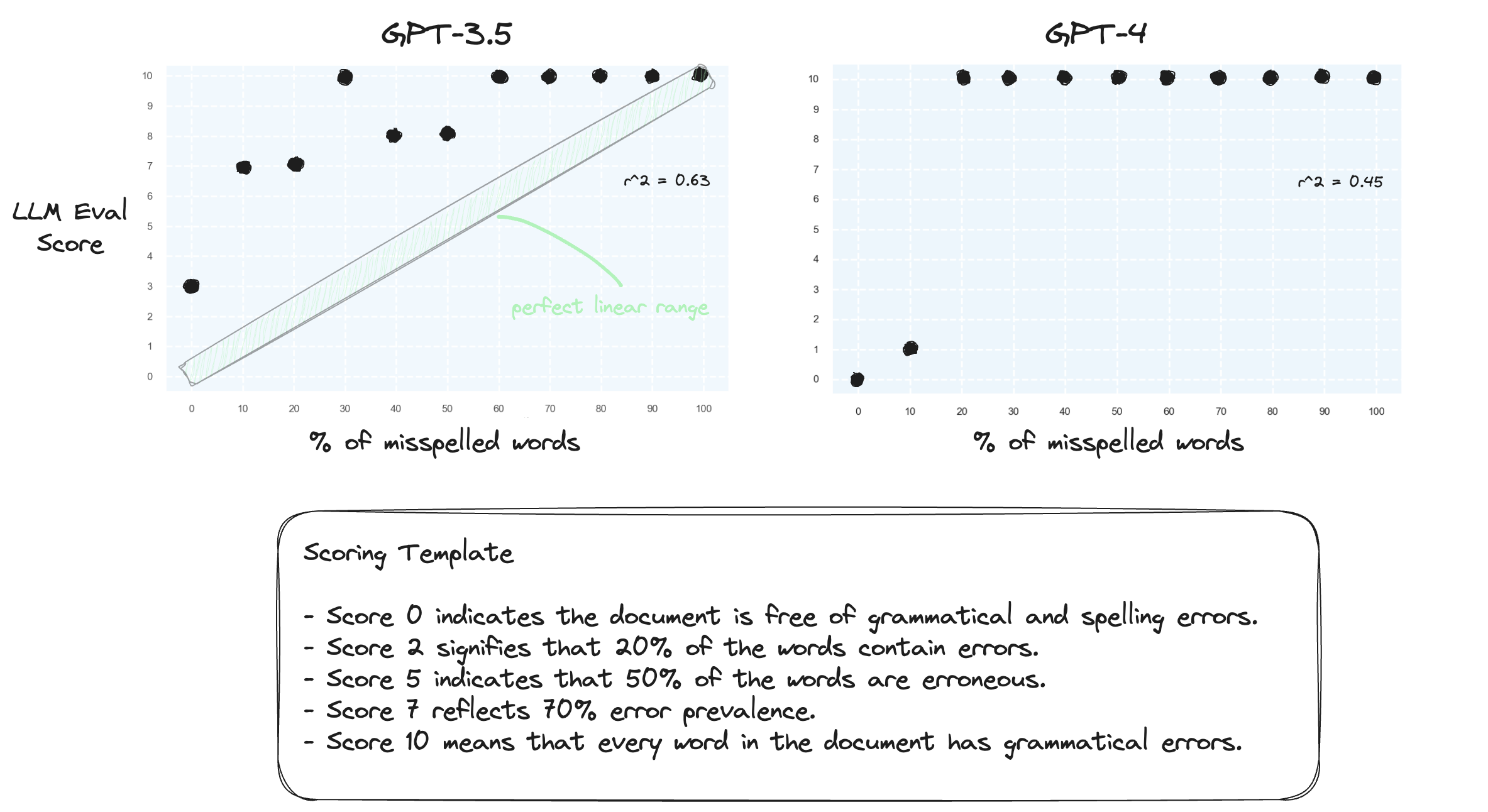
正如所料,两人都严重误判。
测试 2.如果我们颠倒评分范围会发生什么?现在,10 分代表文档拼写完美。
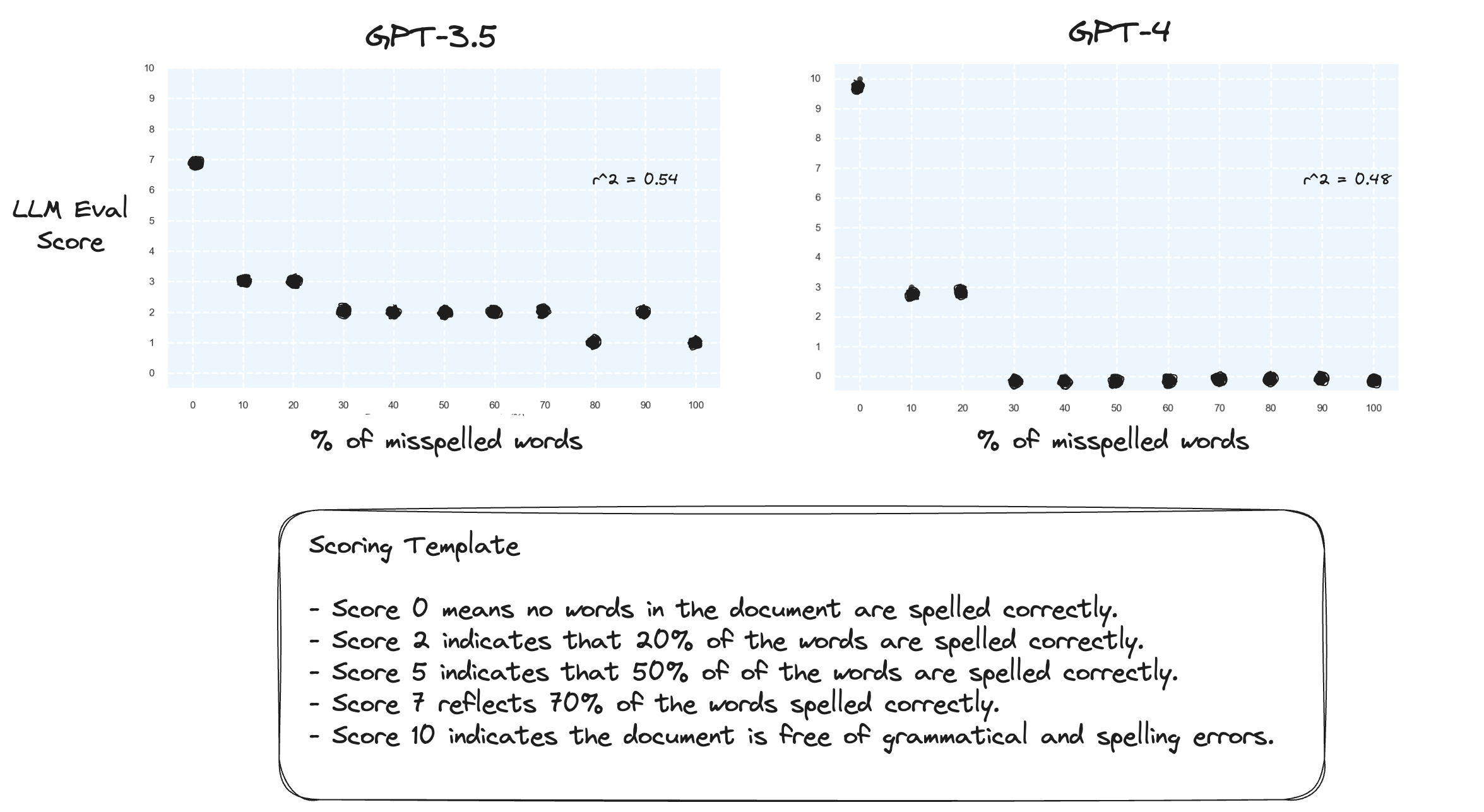
这似乎没有多大区别。
测试 3:如果我们相信 Arize 的假设,那么如果我们避免评分标准并使用“标记等级”,我们可能会看到改进。在这种情况下,我决定将评分标准下调至 5 分。
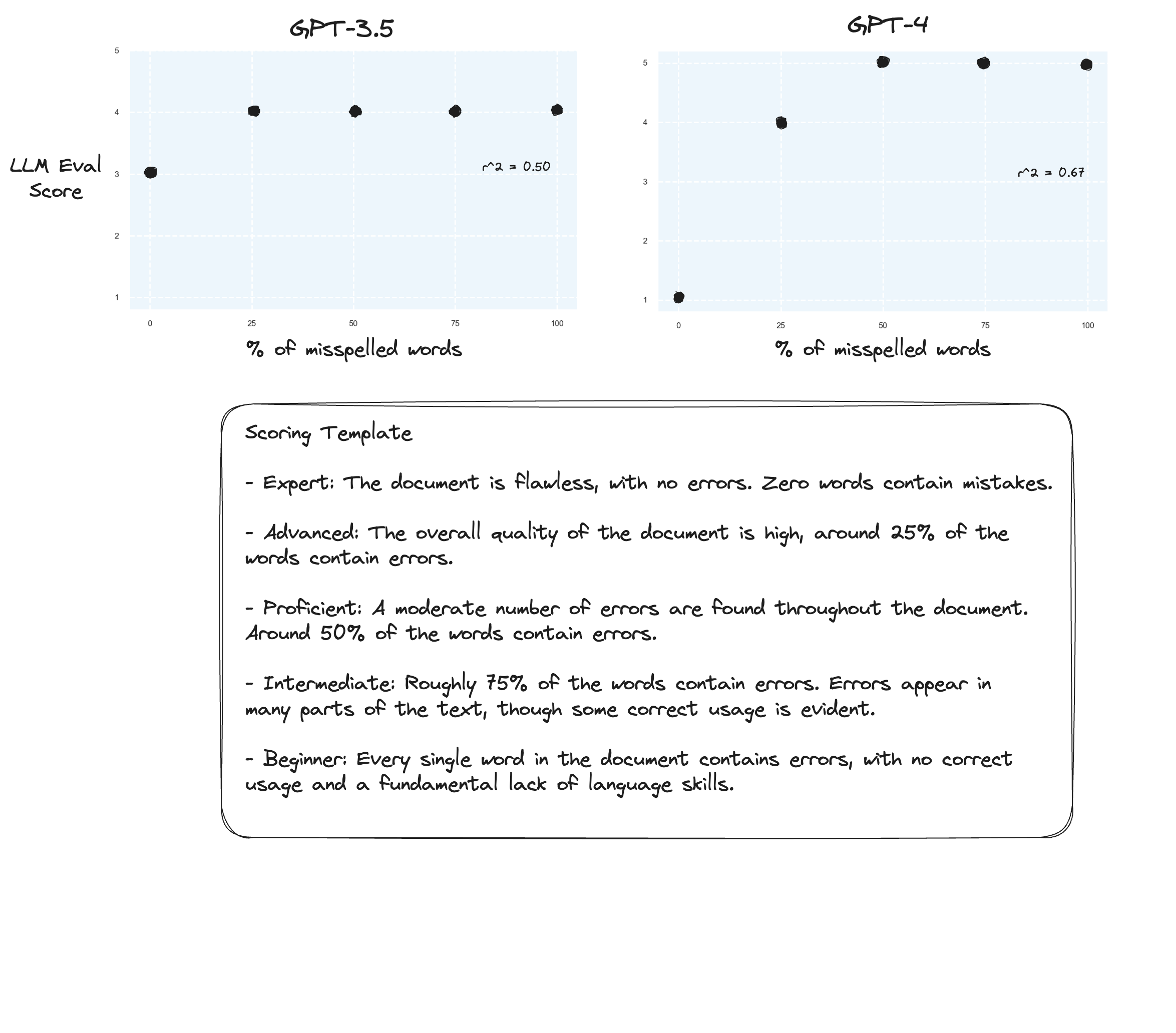
也许略有改进?很难说实话。我没有留下深刻的印象。
测试 4.零样本思维链怎么样?

gpt-3.5 的两个提示变成了乱码。正如预期的那样,当提示大声思考时,gpt-4 会得到改进。请注意,它对于是否给出 10 分非常犹豫。
测试5.按照Prometheus作者的建议;将每个分数与其自己的解释进行映射可能会提高法学硕士在整个数字范围内评分的能力。这与 CoT 相结合,导致:

对 gpt-4 的持续改进。分配边界分数 0 和 10 仍然非常不情愿。
测试 6.在详细了解 MT Bench 后,我决定测试另一种方法,使用成对比较而不是单独评分。现在,通常这需要 O(n * log N) 次比较,但因为我们已经知道我认为的顺序,所以我们只测试最难的情况:比较 0% 拼写错误与 10% 拼写错误、10% 与 20% 等等总共 10 次比较。请注意,我也使用了零样本 CoT。
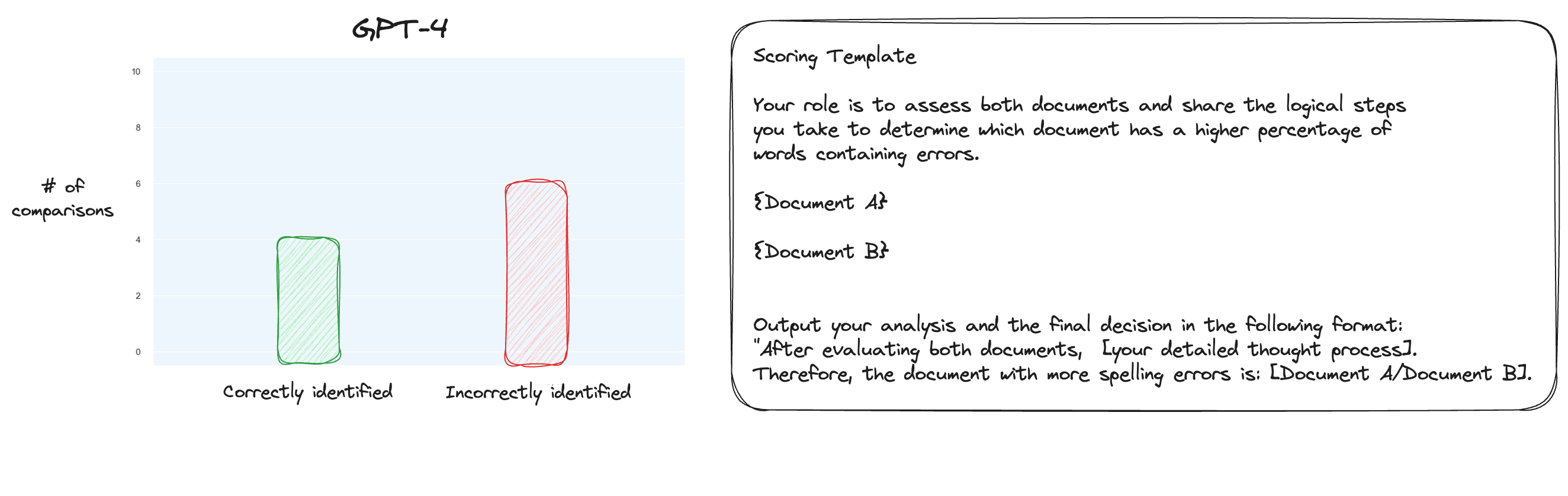
我的假设是,GPT-4 在需要比较上下文窗口内的两个文本的情况下会表现出色,但我错了。令我惊讶的是,这根本没有改善事情。当然,这是所有可能的比较中最难的,但总而言之,这仍然是一项简单的任务。也许这项任务的定量方面对于法学硕士来说本质上是非常困难的。嗯,也许我需要找到一个更好的代理任务......
(31/1)我一直在研究 MT-Bench 的内部结构,非常惊讶地发现他们只是要求 GPT-4 以 1-10 的范围对输出进行评分。他们确实提供了替代的评分选项,例如与基线进行成对比较,但推荐的选项是数字选项。判断提示也出奇的简单:
请充当公正的法官,评估人工智能助手对下面显示的用户问题的回答质量。您的评估应考虑回复的有用性、相关性、准确性、深度、创造力和详细程度等因素。通过提供简短的解释来开始您的评估。尽可能客观。提供解释后,您必须严格遵循以下格式对响应进行评分:[评分],例如:“评分:5”,范围为 1 到 10。 [问题] {问题} [助理回答的开始] {答案} [助理回答的结束]
如果有人相信这就是 MT-Bench 中判断的全部内容,那么我开始质疑使用拼写错误任务作为代理任务......
(2/2)我热衷于让 GPT-4 通过成对比较来判断拼写错误的文本,而不是单独评分。这是 MT Bench 的替代判断方法之一(尽管他们确实推荐孤立评分),我怀疑它更适合这个任务。 CoT + 完整映射结果绝对是一个改进,但我仍然认为还有工作要做。成对评分的缺点当然是您将需要更多的 API 调用来建立完整的排名(在实践中)。


