datalens
1.0.0
这是一个个人实验,使用法学硕士根据用户定义的标准对非结构化工作数据进行排名。传统的求职平台依赖于严格的过滤系统,但许多用户缺乏这样的具体标准。 Datalens 可让您以更自然的方式定义您的偏好,然后根据相关性对每个职位发布进行评级。
某些标准可能比其他标准更重要,因此“必须标准”的权重是普通标准的两倍。
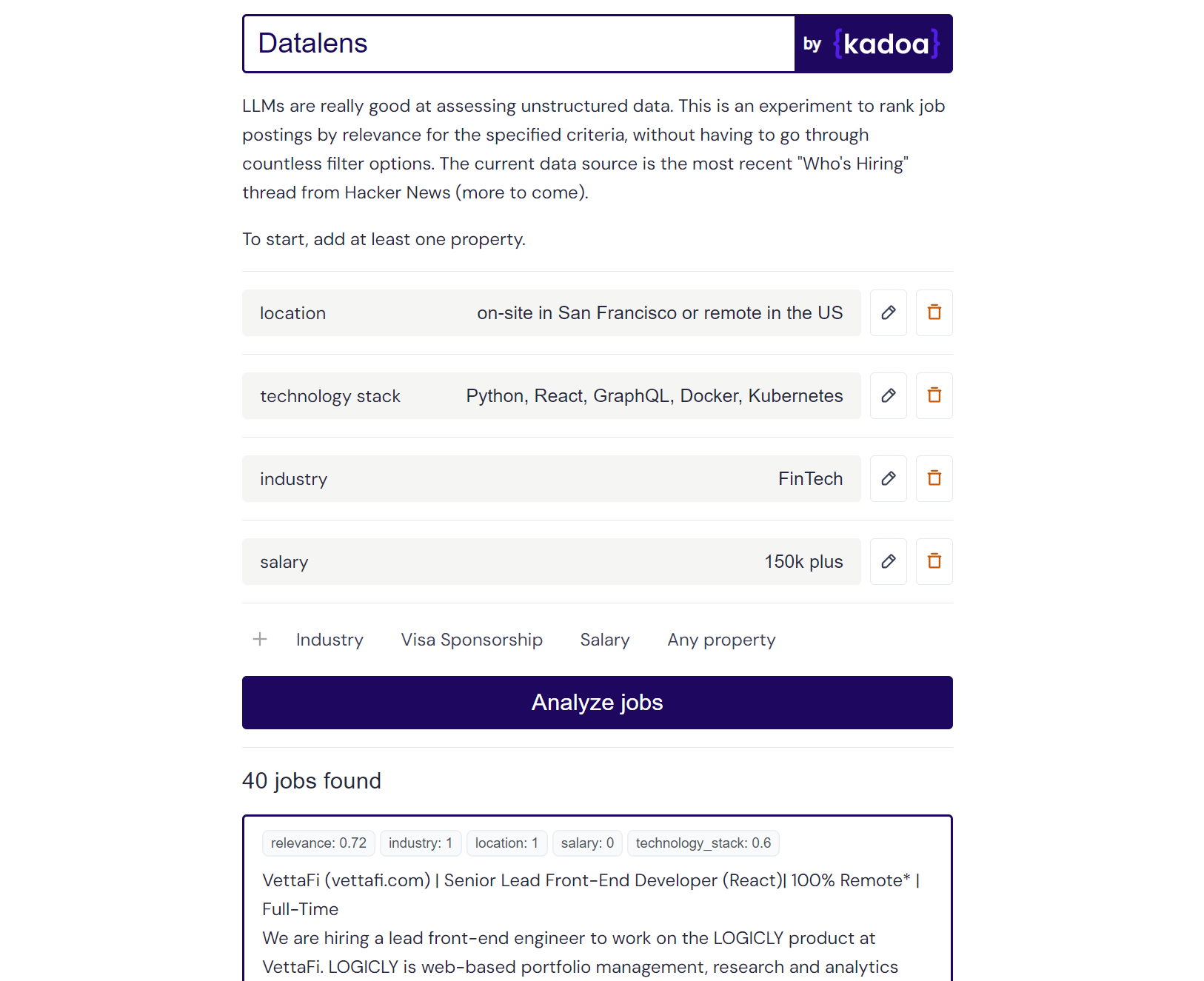
Claude-2 示例结果:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
您可以添加任何您喜欢的作业数据源。我已经使用 Hacker News 的最新“谁在招聘”主题对其进行了预先配置,但您可以添加自己的来源。
通过更新sources_config.json 添加新的作业源。例子:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
我使用自己的工具 Kadoa 从公司页面获取职位数据,但您可以使用任何其他传统的抓取方法。
以下是一些现成的公共端点,用于获取这些公司的所有职位发布(每日更新):
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
让我知道是否应该添加任何其他公司。另外,很高兴为您提供 Kadoa 的试用权限。
相关性评分与gpt-4-0613配合使用效果最佳,它返回 0-1 之间的细粒度分数。如果您有权访问claude-2它也可以很好地工作。可以使用gpt-3.5-turbo-0613 ,但它通常返回 0 或 1 的二进制分数作为标准,缺乏区分部分匹配和完全匹配的细微差别。
出于成本原因,默认型号为gpt-3.5-turbo-0613 。您可以通过将use_claude替换为use_openai来从 GPT 切换到 Claude。
连续运行此脚本可能会导致 API 使用率较高,因此请负责任地使用它。我正在记录每个 GPT 调用的成本。
要运行该应用程序,您需要:
复制 .env.example 文件并填写。
运行 Flask 服务器:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
导航到客户端目录并安装 Node 依赖项:
cd client
npm install
运行 Next.js 客户端:
cd client
npm run dev


