Darwin
1.0.0
机构:新南威尔士大学(UNSW)AI4Science & GreenDynamics AI
Darwin 是一个开源项目,致力于根据科学文献和数据集预训练和微调 LLaMA 模型。 Darwin 专为科学领域而设计,重点是材料科学、化学和物理学,它集成了结构化和非结构化科学知识,以提高科学研究中语言模型的功效。
使用和许可声明:Darwin 已获得许可并仅供研究使用。该数据集已获得 CC BY NC 4.0 许可,允许非商业用途。使用此数据集训练的模型不应用于研究目的之外。重量差异也遵循 CC BY NC 4.0 许可
[2024.11.20]
主要成就
模型性能洞察
数据策略和见解
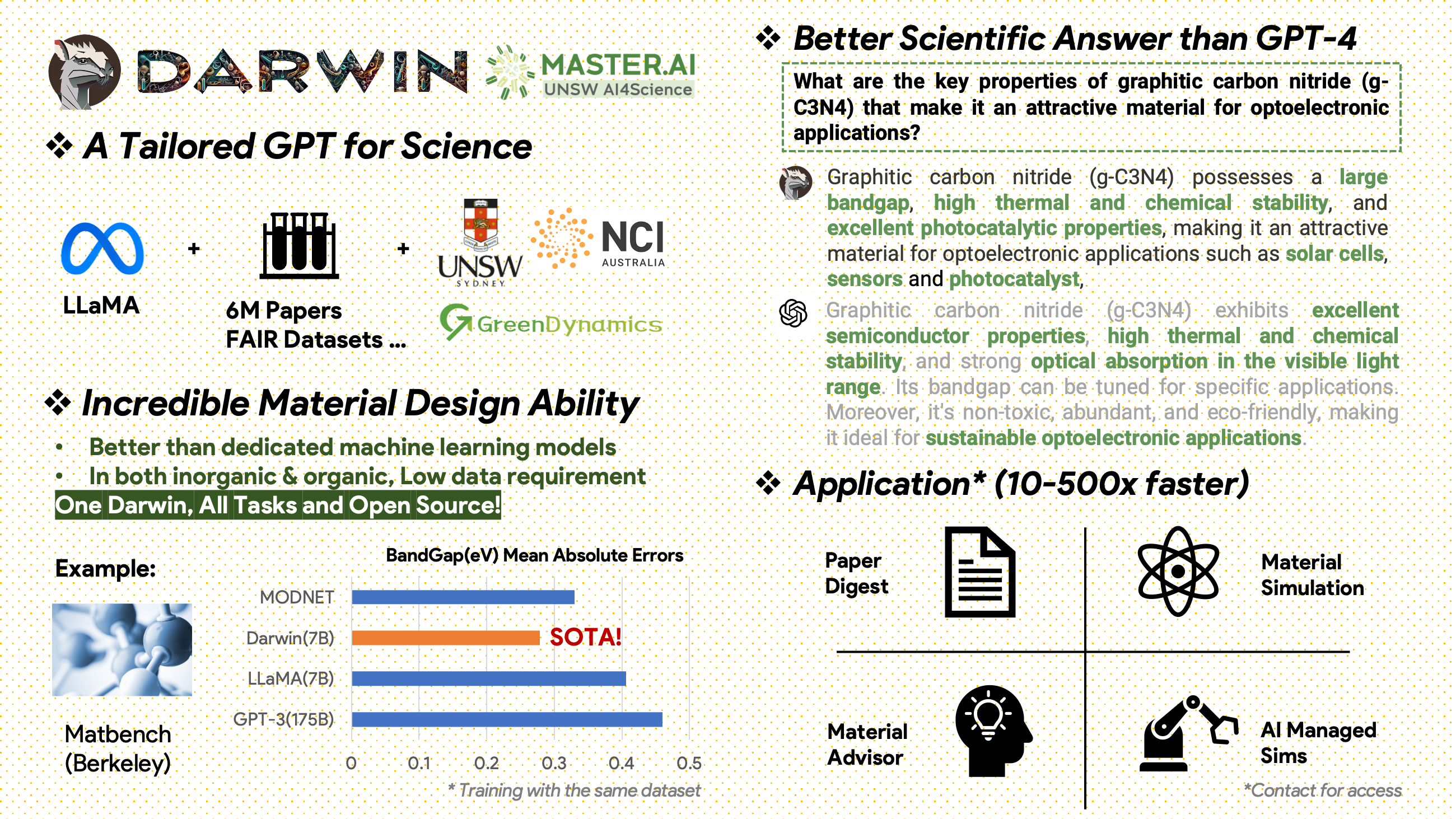
[2024.02.15] Material Projects 的 MatBench 中的 SOTA:DARWIN 是实验带隙预测任务和金属分类任务中的 SOTA 模型,优于 Fine-tuned GPT3.5 和专用 ML 模型。 https://matbench.materialsproject.org/Leaderboards%20Per-Task/matbench_v0.1_matbench_expt_gap/
☆ [2023.09.15]Google Colab 版本可用:通过 Google Colab 尝试我们的 DARWIN: inference.ipynb
Darwin 基于 7B LLaMA 模型,接受了 Darwin 科学指令生成器 (SIG) 从各种科学 FAIR 数据集和文献语料库生成的超过 100,000 个指令跟踪数据点的训练。通过关注模型响应的事实正确性,达尔文代表了利用大型语言模型 (LLM) 进行科学发现的重大进步。初步的人类评估表明,Darwin 7B 在科学问答方面优于 GPT-4,在解决化学问题(如 gptChem)方面优于 GPT-3。
我们正在积极开发 Darwin 以进行更高级的科学领域实验,并且我们还将 Darwin 与 LangChain 集成以解决更复杂的科学任务(例如个人计算机的私人研究助理)。
请注意,Darwin 仍处于开发阶段,有许多限制需要解决。最重要的是,我们尚未对达尔文进行微调以实现最大程度的安全。我们鼓励用户报告任何相关行为,以帮助提高模型的安全性和道德考虑。
演示链接
首先安装要求:
pip install -r requirements.txt从 onedrive 下载 Darwin-7B 重量的检查点。下载模型后,您可以尝试我们的演示:
python inference.py < your path to darwin-7b >请注意,Darwin 7B 的推理至少需要 10GB GPU 内存。
为了使用不同的数据集进一步微调我们的 Darwin-7b,下面是一个在具有 4 个 A100 80G GPU 的机器上运行的命令。
torchrun --nproc_per_node=8 --master_port=1212 train.py
--model_name_or_path < your path to darwin-7b >
--data_path < your path to dataset >
--bf16 True
--output_dir < your output dir >
--num_train_epochs 3
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 False我们的数据来自两个主要来源:
2000年后出版了包含材料科学、化学和物理领域600万篇论文的原始文献语料库。出版商包括ACS、RSC、Springer Nature、Wiley和Elsevier。我们感谢他们的支持。
FAIR 数据集 - 我们从 16 个 FAIR 数据集中收集了数据。
我们开发了 Darwin-SIG 来生成科学指令。它可以记忆完整文献文本中的长文本(平均~5000字),并根据科学文献关键词生成问答(Q&A)数据(来自web of science API)
注意:您还可以使用 GPT3.5 或 GPT-4 进行生成,但这些选项可能会很昂贵。
请注意,由于与发布者达成协议,我们无法共享训练数据集。
该项目是以下各方的共同努力:
新南威尔士大学和 GreenDynamics:谢童、王绍洲
新南威尔士大学:伊姆兰·拉扎克、科迪·黄
USYD 和 DARE 中心:Clara Grazian
绿色动力:万宇伟、刘逸轩
新南威尔士大学工程学院的 Bram Hoex 和 Wenjie Zhang 为所有人提供了建议。
如果您在工作中使用此存储库中的数据或代码,请相应地引用它。
DAWRIN 基础大语言模型和半自指导微调
@misc{xie2023darwin,
title={DARWIN Series: Domain Specific Large Language Models for Natural Science},
author={Tong Xie and Yuwei Wan and Wei Huang and Zhenyu Yin and Yixuan Liu and Shaozhou Wang and Qingyuan Linghu and Chunyu Kit and Clara Grazian and Wenjie Zhang and Imran Razzak and Bram Hoex},
year={2023},
eprint={2308.13565},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
用于材料发现的微调 GPT-3 和 LLaMA(单任务训练)
@article{xie2023large,
title={Large Language Models as Master Key: Unlocking the Secrets of Materials Science},
author={Xie, Tong and Wan, Yuwei and Zhou, Yufei and Huang, Wei and Liu, Yixuan and Linghu, Qingyuan and Wang, Shaozhou and Kit, Chunyu and Grazian, Clara and Zhang, Wenjie and others},
journal={Available at SSRN 4534137},
year={2023}
}
本项目参考了以下开源项目:
特别感谢 NCI 澳大利亚的 HPC 支持。
我们不断扩大达尔文的开发团队。加入我们,踏上利用人工智能推进科学研究的激动人心的旅程!
对于博士或博士后职位,请联系 [email protected] 或 [email protected] 了解详细信息。
对于其他职位,请访问 www.greendynamics.com.au


