GPT_subtitles
1.0.0
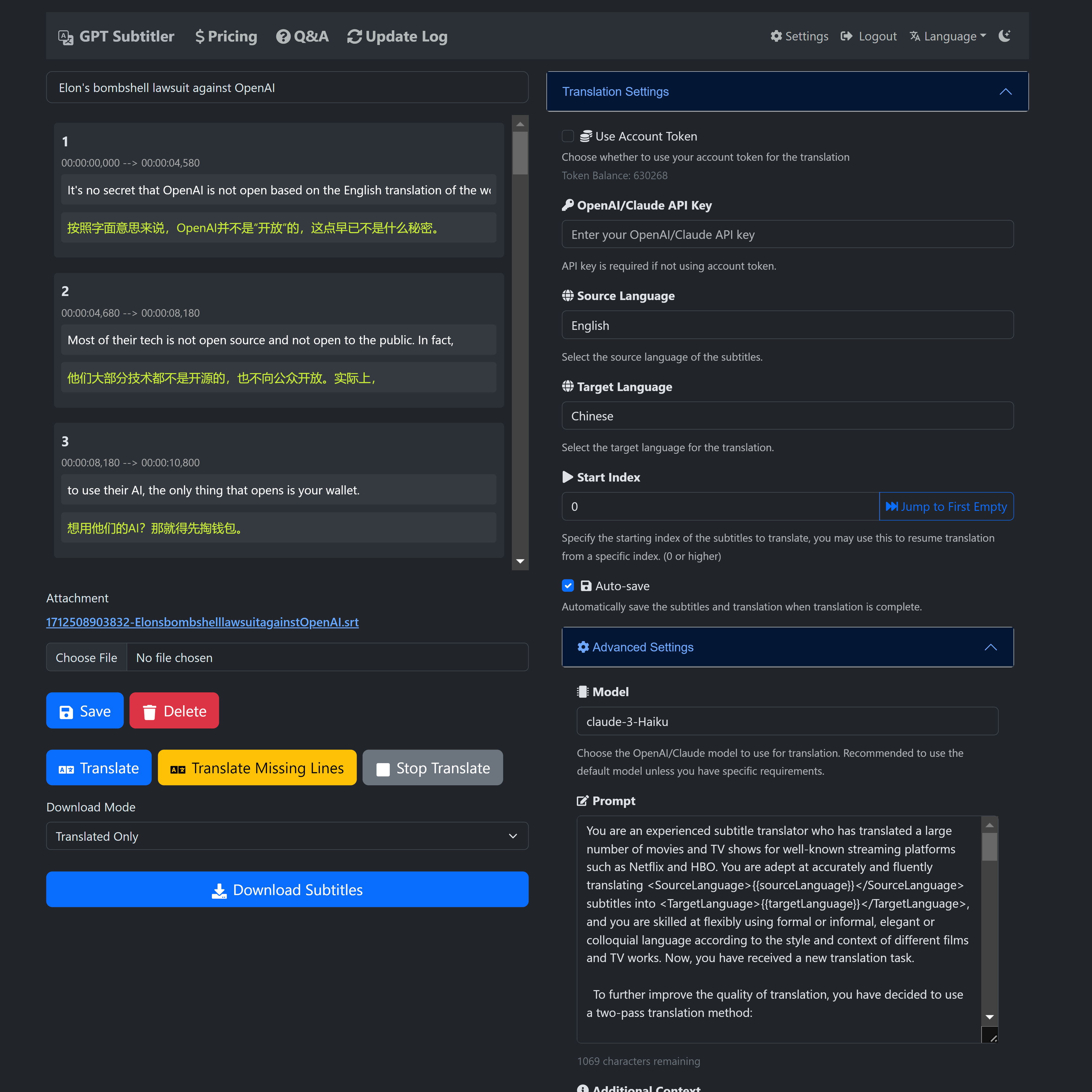
? GPT Subtitler 是一个受该项目启发的 Web 应用程序,具有许多强大的功能:
支持使用Anthropic Claude、GPT-3.5、GPT-4等多种模型进行高质量字幕翻译。目前推荐使用Claude-Haiku模型。
此外, Gemini-1.5-flash和Gemini-1.5-pro模型可供免费用户试用,尽管它们可能不如 Claude-Haiku 模型准确。
?新用户注册后即可获得100,000个免费代币,足以免费翻译20分钟的视频字幕。
?每天都可以领取免费代币,也可以低价购买代币。使用 AI 翻译不需要 API 密钥。
?实时预览翻译结果,支持编辑提示、少量示例,并能够随时停止翻译并从任何位置重新开始。翻译后可导出多种SRT字幕文件格式(译文+原版或原版+翻译双语字幕)。
网站目前处于早期开发阶段,需要您的支持和反馈!欢迎您尝试并提出宝贵建议。
如果您在使用过程中遇到任何Bug或有任何建议,请随时在GitHub项目上提出问题或通过电子邮件发送反馈。
网站链接 https://gptsubtitler.com/en
感谢您的支持和阅读本文!
这是 100,000 个代币的兑换代码: GPTSubtitler_github_repo
您可以在“设置”中使用它
下载YouTube视频(或提供您自己的视频)并使用Whisper和翻译API生成双语字幕,中文文档请见中文
该项目是一个Python脚本,它下载YouTube视频(或使用本地视频文件),对其进行转录,将转录文本翻译成目标语言,并生成带有双字幕(原始和翻译)的视频。转录和翻译分别由 Whisper 模型和翻译 API(M2M100、google、GPT3.5)提供支持。
GPT-3.5 翻译与 Google 翻译的比较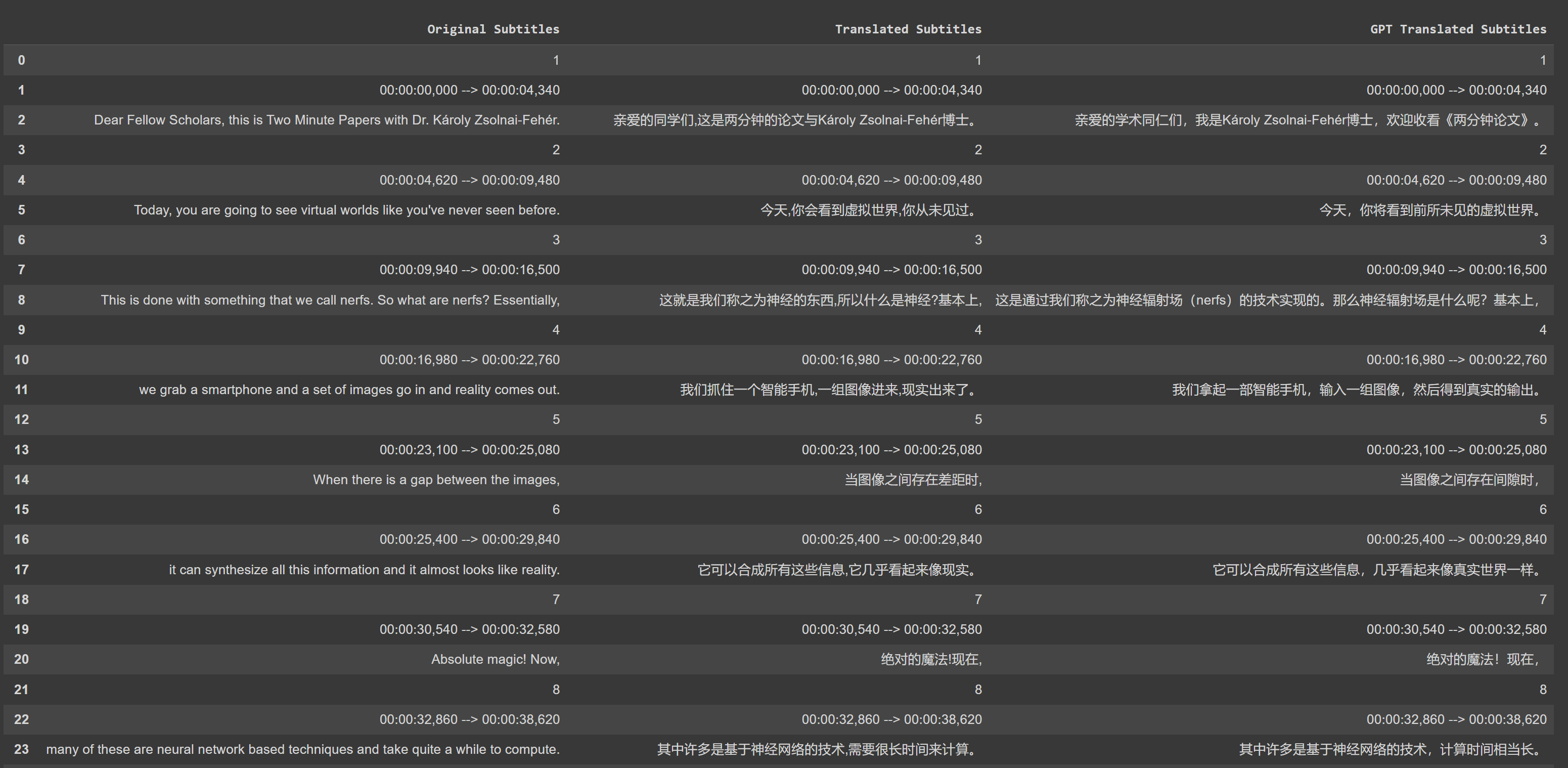
论据: 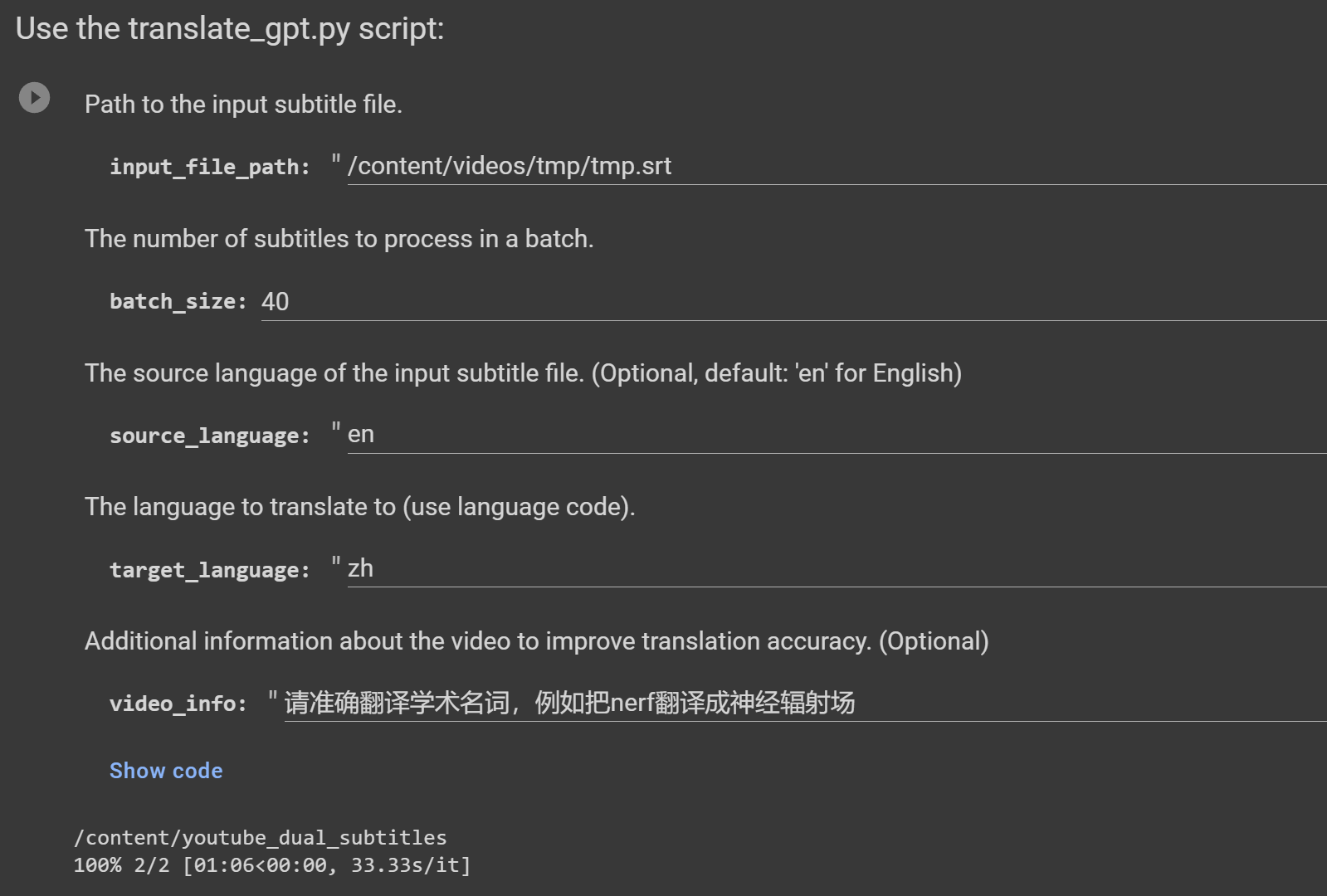
此外,首次运行脚本时,它将下载以下预训练模型:
pip install -r requirements.txt安装所需的依赖项您可以提供 YouTube URL 或本地视频文件进行处理。该脚本将转录视频、翻译转录文本并生成 SRT 文件形式的双字幕。
python main.py --youtube_url [YOUTUBE_URL] --target_language [TARGET_LANGUAGE] --model [WHISPER_MODEL] --translation_method [TRANSLATION_METHOD]
--youtube_url:YouTube 视频的 URL。
--local_video:本地视频文件的路径。
--target_language:翻译的目标语言(默认值:'zh')。
--model:选择 Whisper 模型之一(默认值:'small',选项:['tiny', 'base', 'small', 'medium', 'large'])。
--translation_method:用于翻译的方法。 (默认值:“google”,选择:[“m2m100”、“google”、“whisper”、“gpt”、“no_translate”])。
--no_transcribe:跳过转录步骤。假设有一个与视频文件同名的SRT文件
注意:您必须提供 --youtube_url 或 --local_video,但不能同时提供两者。
要下载 YouTube 视频、对其进行转录,并使用 google api 进行翻译,生成目标语言的字幕:
python main.py --youtube_url [YOUTUBE_URL] --target_language 'zh' --model 'small' --translation_method 'google'
要处理本地视频文件、对其进行转录并使用 gpt3.5-16k 生成目标语言的字幕(您需要提供 OpenAI API 密钥):
python main.py --local_video [VIDEO_FILE_PATH] --target_language 'zh' --model 'medium' --translation_method 'gpt'
该脚本将在与输入视频相同的目录中生成以下输出文件:
该脚本使用 OpenAI 的 GPT-3.5 语言模型翻译字幕。它需要OpenAI API 密钥才能运行。在大多数情况下,与 Google 翻译相比,基于 GPT 的翻译会产生更好的结果,特别是在处理特定于上下文的翻译或惯用表达时。该脚本旨在当谷歌翻译等传统翻译服务无法产生令人满意的结果时,提供另一种翻译字幕的方法。
OPENAI_API_KEY=your_api_key_here
将 your_api_key_here 替换为您从 OpenAI 获取的 API 密钥。
python translate_gpt.py --input_file INPUT_FILE_PATH [--batch_size BATCH_SIZE] [--target_language TARGET_LANGUAGE] [--source_language SOURCE_LANGUAGE] [--video_info VIDEO_INFO] [--model MODEL_NAME] [--no_mapping] [--load_tmp_file]
您可以检查包含输入视频文件的文件夹中的response.log文件以进行实时更新,类似于ChatGPT 的体验。
笔记:
视频信息: --video_info参数接受任何语言的详细信息。它可用于告知 GPT 模型有关视频内容的信息,从而改进上下文特定术语(例如游戏中的专有名词)的翻译。例如,如果翻译与游戏相关的视频,您可以指示 GPT 对游戏中的术语使用精确的翻译。
翻译映射:此功能通过存储源-目标翻译对来保持常用术语的一致性。启用后,它可以防止视频中专有名词和技术术语等术语的翻译发生变化。如果愿意,可以使用--no_mapping标志禁用此功能。
恢复翻译:使用--load_tmp_file标志从先前中断的位置继续翻译任务。该脚本将进度保存在tmp_subtitles.json中,允许无缝恢复而无需重做之前的工作。
语言支持:虽然该脚本在英语到简体中文翻译方面表现出色,但它也可以容纳其他语言对。通过向few_shot_examples.json添加定制的少数示例来提高其他语言的准确性。请注意,GPT 模型的性能可能会因多语言输入而异,并且可能需要在translate_gpt.py中进行提示调整。
非常欢迎您的贡献!
您还可以使用 Google Colab 笔记本尝试此脚本。单击下面的链接访问示例:
按照笔记本中的说明下载必要的包和模型,并在所需的 YouTube 视频或本地视频文件上运行脚本。


