multimedia gpt
1.0.0
多媒体 GPT 将 OpenAI GPT 与视觉和音频连接。您现在可以使用 OpenAI API 密钥发送图像、录音和 pdf 文档,并获得文本和图像格式的响应。我们目前正在添加对视频的支持。这一切都是由受 Microsoft Visual ChatGPT 启发并构建的提示管理器实现的。
除了 Microsoft Visual ChatGPT 中提到的所有视觉基础模型之外,多媒体 GPT 还支持 OpenAI Whisper 和 OpenAI DALLE!这意味着您不再需要自己的 GPU 来进行语音识别和图像生成(尽管您仍然可以!)
基本聊天模型可以配置为任何 OpenAI LLM ,包括 ChatGPT 和 GPT-4。我们默认为text-davinci-003 。
欢迎您分叉此项目并添加适合您自己的用例的模型。一个简单的方法是通过 llama_index。您必须在model.py中为模型创建一个新类,并在multimedia_gpt.py中添加运行程序方法run_<model_name> 。有关示例,请参阅run_pdf 。
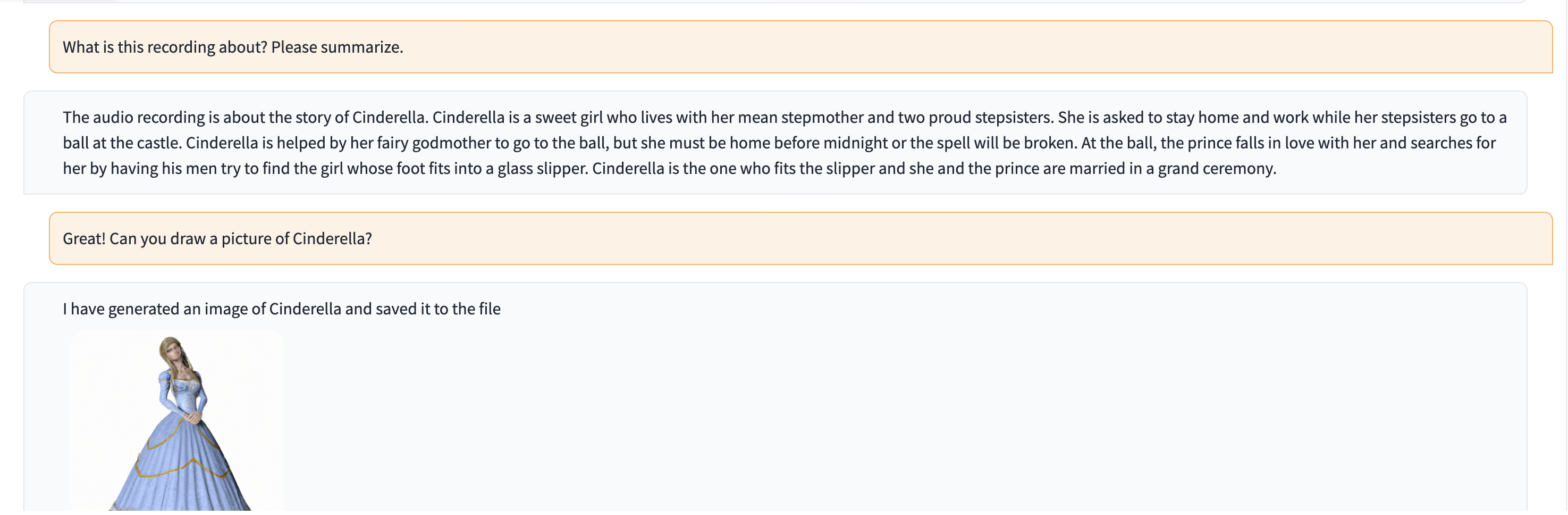
在此演示中,ChatGPT 接收到一个人讲述灰姑娘故事的录音。
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). 该项目是一个实验性工作,不会部署到生产环境。我们的目标是探索提示的力量。


