BabyGPT Build_GPT_From_Scratch
1.0.0
Baby GPT 是一个探索性项目,旨在逐步构建类似 GPT 的语言模型。该项目从简单的 Biggram 模型开始,逐渐融入 Transformer 模型架构中的先进概念。
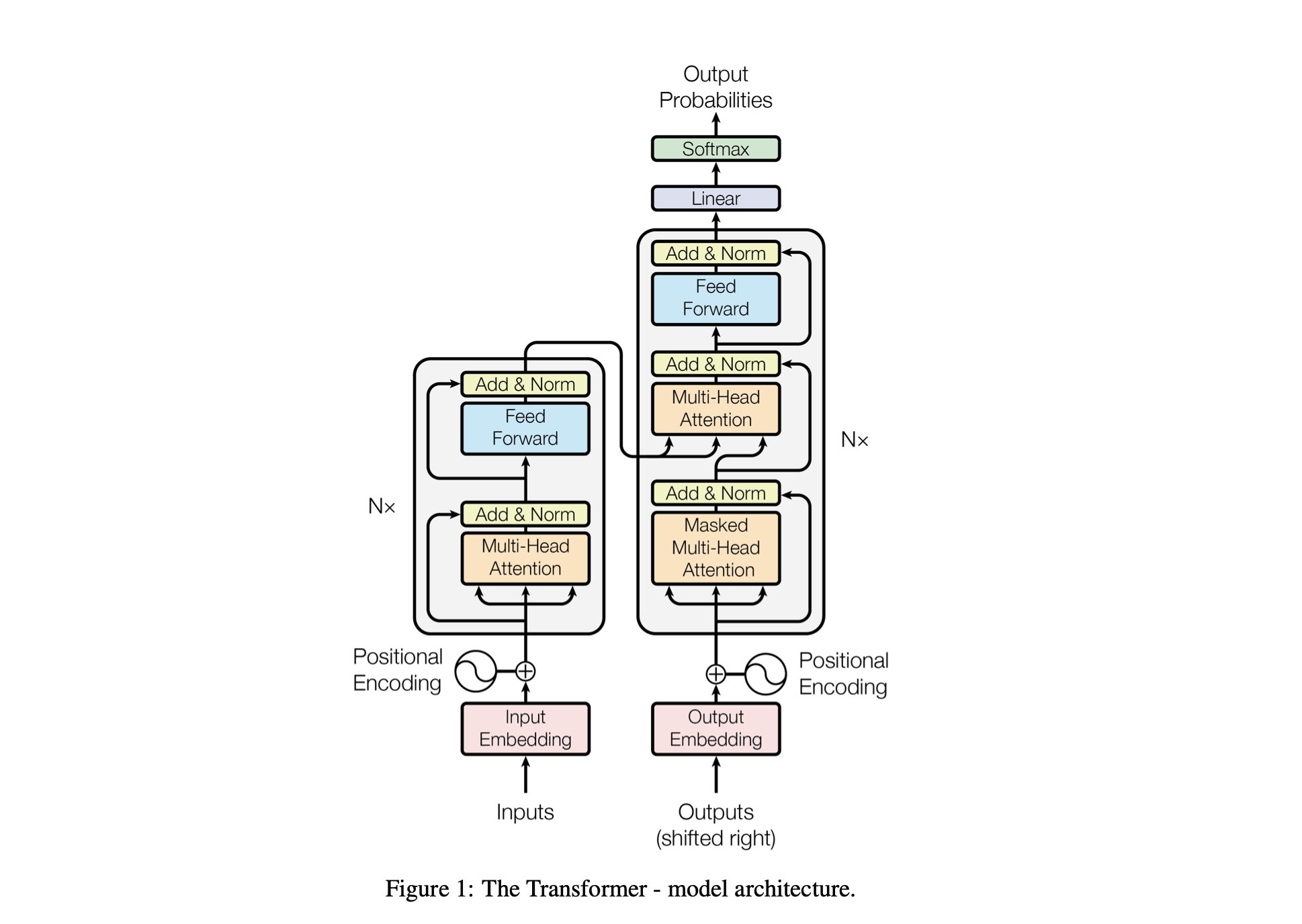
使用以下超参数调整模型的性能:
batch_size :训练期间并行处理的序列数block_size :模型正在处理的序列的长度d_model :模型中的特征数量(嵌入的大小)d_k :每个注意力头的特征数量。num_iter :模型将运行的训练迭代总数Nx :模型中变压器块或层的数量。eval_interval :计算和评估模型损失的时间间隔lr_rate :Adam 优化器的学习率device :如果兼容的 GPU 可用,则自动设置为'cuda' ,否则默认为'cpu' 。eval_iters :平均评估损失的迭代次数h :多头注意力机制中注意力头的数量dropout_rate :训练期间用于防止过度拟合的 dropout 率这些超参数经过精心选择,以平衡模型从数据中学习而不会过度拟合的能力以及有效管理计算资源的能力。
| 超参数 | CPU型号 | GPU模型 |
|---|---|---|
device | '中央处理器' | 'cuda'(如果可用),否则为 'cpu' |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10000 | 10000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 第512章 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0.2 | 0.2 |
lr_rate | 0.005(5e-3) | 0.001 (1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int和int_to_chars创建词汇词典。encode函数将字符串转换为整数,然后使用decode函数将字符串转换回来。train_data )和验证集( valid_data )。get_batch函数以小批量方式准备数据以进行训练。BigramLM类中的模型架构。小批量是机器学习中的一种技术,其中训练数据被分成小批量。每个小批量在模型训练期间单独处理。这种方法有助于:
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | 因素 | 小批量 | 大批量 |
|---|---|---|
| 梯度噪声 | 更高(更新差异更大) | 更低(更一致的更新) |
| 收敛 | 倾向于探索更多解决方案,包括更平坦的最小值 | 通常会收敛到更尖锐的最小值 |
| 概括 | 可能更好(由于最小值更平坦) | 可能更糟(由于最小值更尖锐) |
| 偏见 | 较低(不太可能过度拟合训练数据模式) | 更高(可能与训练数据模式过度拟合) |
| 方差 | 更高(由于对解决方案空间的更多探索) | 较低(由于解决方案空间探索较少) |
| 计算成本 | 每个时期更高(更多更新) | 每个纪元较低(更新较少) |
| 内存使用情况 | 降低 | 更高 |
estimate_loss函数计算模型在指定迭代次数 (eval_iters) 上的平均损失。它用于评估模型的性能而不影响其参数。该模型设置为评估模式以禁用某些层(例如 dropout)以实现一致的损失计算。计算训练数据和验证数据的平均损失后,模型将恢复到训练模式。此功能对于监控培训过程并在必要时进行调整至关重要。
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses位置编码:使用BigramLM类中的positional_encodings_table将位置信息添加到模型中。我们将位置编码添加到字符的嵌入中,就像在变压器架构中一样。
在这里,我们设置并使用 AdamW 优化器在 PyTorch 中训练神经网络模型。 Adam 优化器在许多深度学习场景中受到青睐,因为它结合了随机梯度下降的其他两个扩展的优点:AdaGrad 和 RMSProp。 Adam 计算每个参数的自适应学习率。除了像 RMSProp 一样存储过去梯度平方的指数衰减平均值之外,Adam 还保留过去梯度的指数衰减平均值,类似于动量。这使得优化器能够调整神经网络每个权重的学习率,从而可以对复杂的数据集和架构进行更有效的训练。
AdamW修改了权重衰减纳入优化过程的方式,解决了原始 Adam 优化器的问题,即权重衰减与梯度更新没有很好地分离,导致正则化的应用不理想。使用 AdamW 有时可以带来更好的训练性能和对未见数据的泛化能力。我们选择 AdamW 是因为它能够比标准 Adam 优化器更有效地处理权重衰减,从而有可能改进模型训练和泛化。
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()自注意力是一种机制,允许模型以不同的方式权衡输入数据不同部分的重要性。它是 Transformer 架构的关键组件,使模型能够专注于输入序列的相关部分以进行预测。
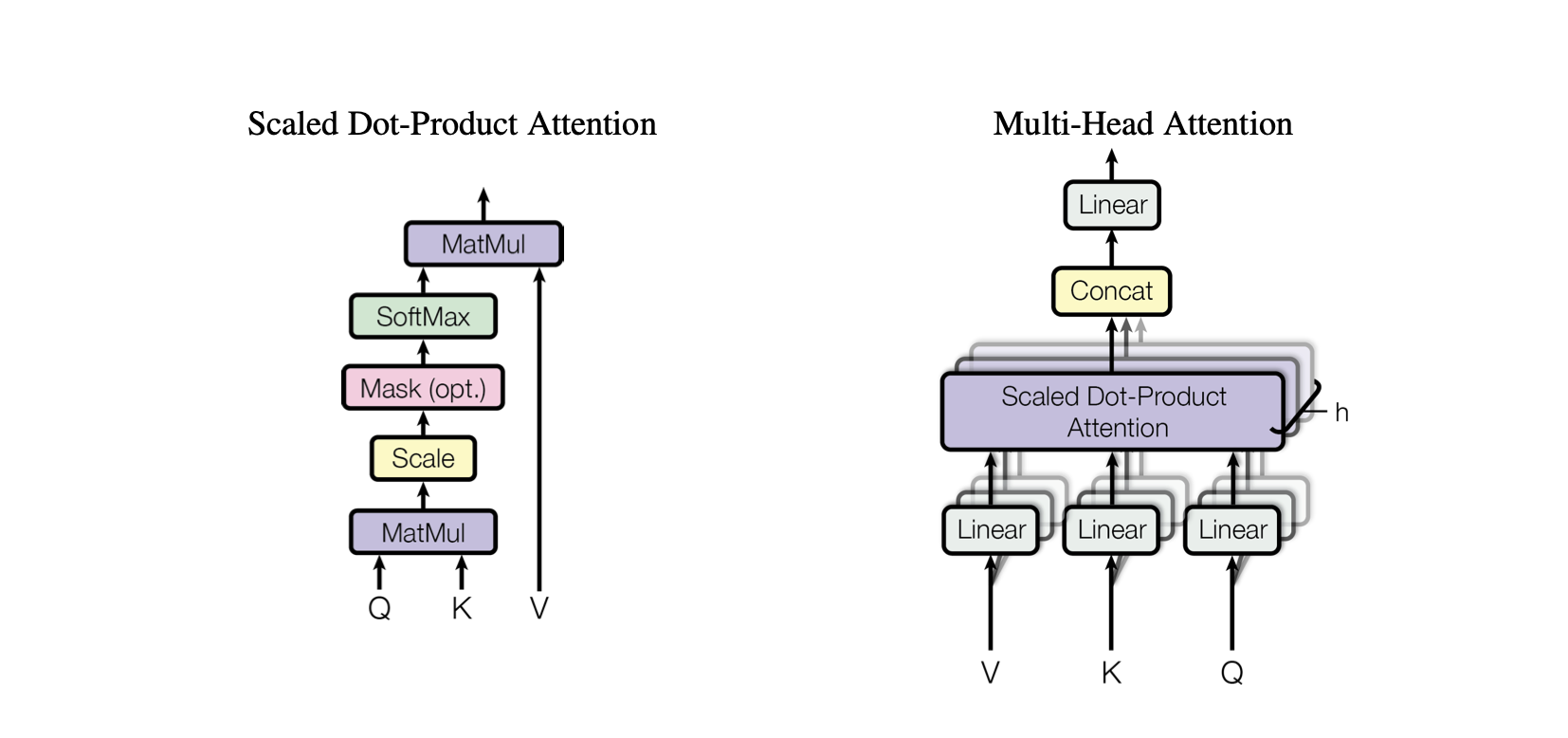
点积注意力:一种简单的注意力机制,根据查询和键之间的点积计算值的加权和。
缩放点积注意力:对点积注意力的改进,通过键的维数缩小点积,防止训练期间梯度变得太小。
OneHeadSelfAttention :单头自注意力机制的实现,允许模型关注输入序列的不同位置。 SelfAttention类展示了注意力机制及其缩放版本背后的直觉。
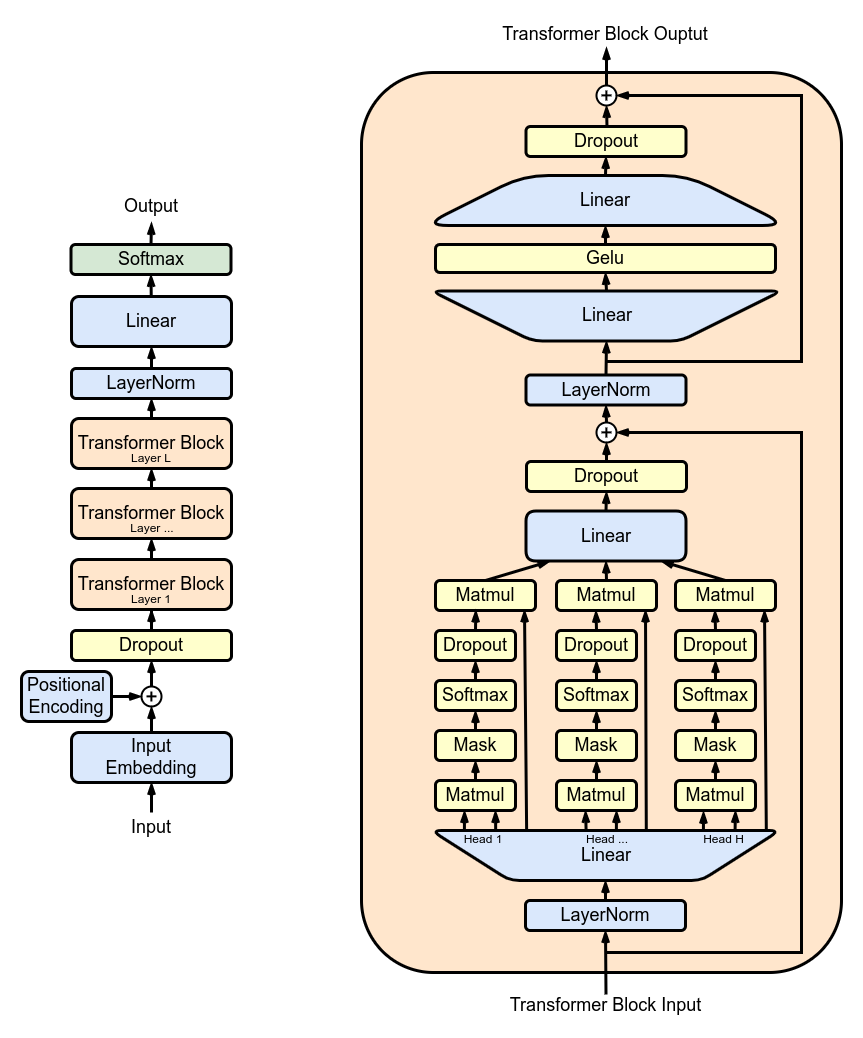
Baby GPT 项目中的每个相应模型都逐步建立在前一个模型的基础上,从自我注意力机制背后的直觉开始,然后是点积和缩放点积注意力的实际实现,最终集成一个-头部自注意力模块。
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur SelfAttention类代表 Transformer 模型的基本构建块,用单个头封装自注意力机制。以下是对其组件和流程的深入了解:
初始化:构造函数__init__(self, d_k)初始化键、查询和值的线性层,所有这些都具有维度d_k 。这些线性变换将输入投影到不同的子空间中以进行后续的注意力计算。
Buffers : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))将下三角矩阵注册为持久缓冲区,不被视为模型参数。该矩阵用于注意力机制中的屏蔽,以防止在每个计算步骤中考虑未来位置(在解码器自注意力中有用)。
Forward Pass : forward(self, X)方法定义了每次调用 self-attention 模块时执行的计算
MultiHeadAttention :组合MultiHeadAttention类中多个SelfAttention头的输出。 MultiHeadAttention 类是上一步中的一个头的自注意力机制的扩展实现,但现在多个注意力头并行操作,每个注意力头关注输入的不同部分。
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward :在FeedForward类中使用 ReLU 激活实现前馈神经网络。像原始 Transformer 模型一样,将这个完全连接的前馈添加到我们的模型中。
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
return self . net ( X ) TransformerBlocks :使用Block类堆叠变压器块以创建更深的网络架构。深度和复杂性:在神经网络中,深度是指处理数据的层数。每个附加层(或块,对于 Transformer 而言)都允许网络捕获输入数据的更复杂和抽象的特征。
顺序处理:每个 Transformer 块都会处理其前一个块的输出,逐渐建立对输入的更复杂的理解。这种顺序处理允许网络开发数据的深层、分层表示。变压器组的组件
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return XResidualConnections :增强Block类以包含剩余连接,提高学习效率。残差连接,也称为跳跃连接,是深度神经网络设计中的一项关键创新,特别是在 Transformer 模型中。他们解决了训练深度网络的主要挑战之一:梯度消失问题。
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return XLayerNorm :使用Block类中的nn.LayerNorm(d_model)将层归一化添加到 Transformer.Normalizing 层输出。
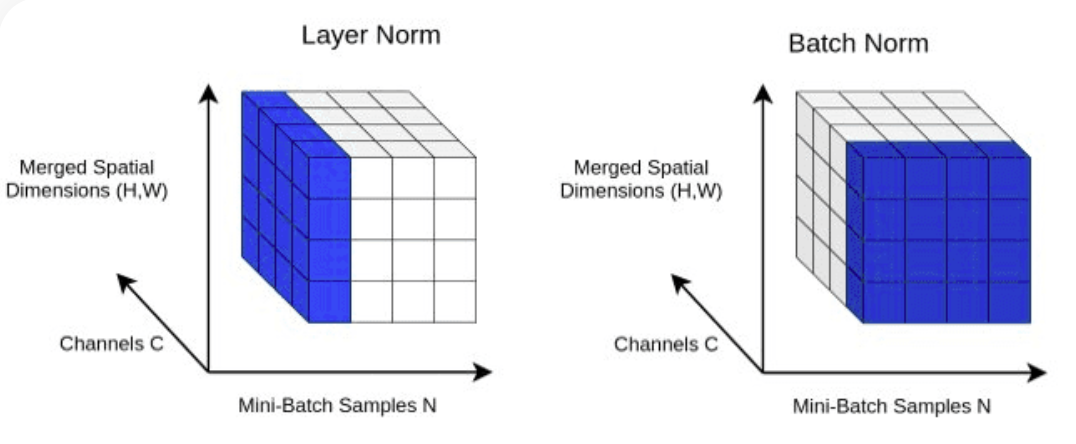
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] Dropout :作为正则化方法添加到SelfAttention和FeedForward层中,以防止过度拟合。我们将 drop-out 添加到:
ScaleUp :通过扩展batch_size 、 block_size 、 d_model 、 d_k和Nx来增加模型的复杂性。您将需要 CUDA 工具包以及配备 NVIDIA GPU 的机器来训练和测试这个更大的模型。
如果您想尝试使用 CUDA 进行 GPU 加速,请确保您安装了支持 CUDA 的适当版本的 PyTorch。
import torch
torch . cuda . is_available ()您可以通过在 PyTorch 安装命令中指定 CUDA 版本来完成此操作,例如在命令行中:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

