Agent FLAN
1.0.0
[?拥抱脸] [? OpenXLab] [?论文] [ 项目页]
开源的大型语言模型(LLM)在各种 NLP 任务中取得了巨大的成功,但在充当代理时,它们仍然远远不如基于 API 的模型。如何将代理能力融入到普通法学硕士课程中成为一个至关重要而紧迫的问题。本文首先提出了三个关键观察结果:(1)当前的智能体训练语料库与格式遵循和智能体推理纠缠在一起,这与预训练数据的分布发生了显着的变化; (2) LLM 对代理任务所需的能力表现出不同的学习速度; (3)当前的方法在通过引入幻觉来提高代理能力时存在副作用。基于上述发现,我们提出 Agent-FLAN 来有效地微调 Agent 的语言模型。通过对训练语料库的仔细分解和重新设计,Agent-FLAN 使 Llama2-7B 在各种代理评估数据集上的表现比之前的最佳作品高出 3.5%。通过全面构建负样本,Agent-FLAN 根据我们建立的评估基准极大地缓解了幻觉问题。此外,它在扩展模型大小时持续提高了 LLM 的代理能力,同时略微增强了 LLM 的一般能力。
Agent-FLAN系列应用Agent-FLAN论文中提出的数据生成管道在AgentInstruct和Toolbench上进行了微调,对各种Agent任务和工具利用具有很强的能力~
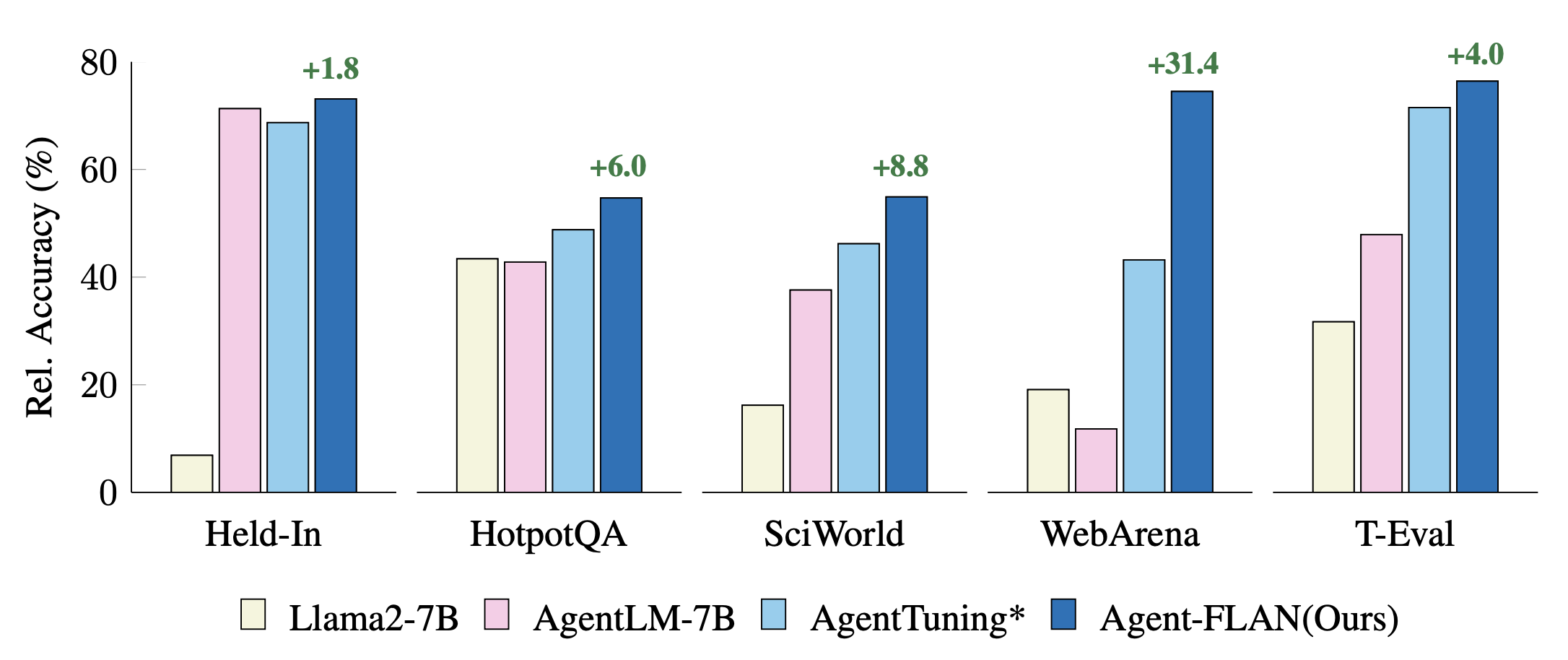
最近的代理调整方法在保留、保留任务上的比较。性能使用 GPT-4 结果进行标准化,以获得更好的可视化效果。 * 表示我们为了公平比较而重新实现。
Agent-FLAN 是通过对 Llama2-chat 系列的 AgentInstruct、ToolBench 和 ShareGPT 数据集进行混合训练而生成的。
模型遵循Llama-2-chat的对话格式,模板协议为:
dict ( role = 'user' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'system' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'assistant' , begin = '<|Assistant|>െ' , end = 'ി n ' ),7B 模型可在 Huggingface 和 OpenXLab 模型中心获取。
| 模型 | 拥抱脸回购 | OpenXLab 存储库 |
|---|---|---|
| 代理-FLAN-7B | 型号链接 | 型号链接 |
Agent-FLAN 数据集也可在 Huggingface 数据集中心获取。
| 数据集 | 拥抱脸回购 |
|---|---|
| 代理FLAN | 数据集链接 |
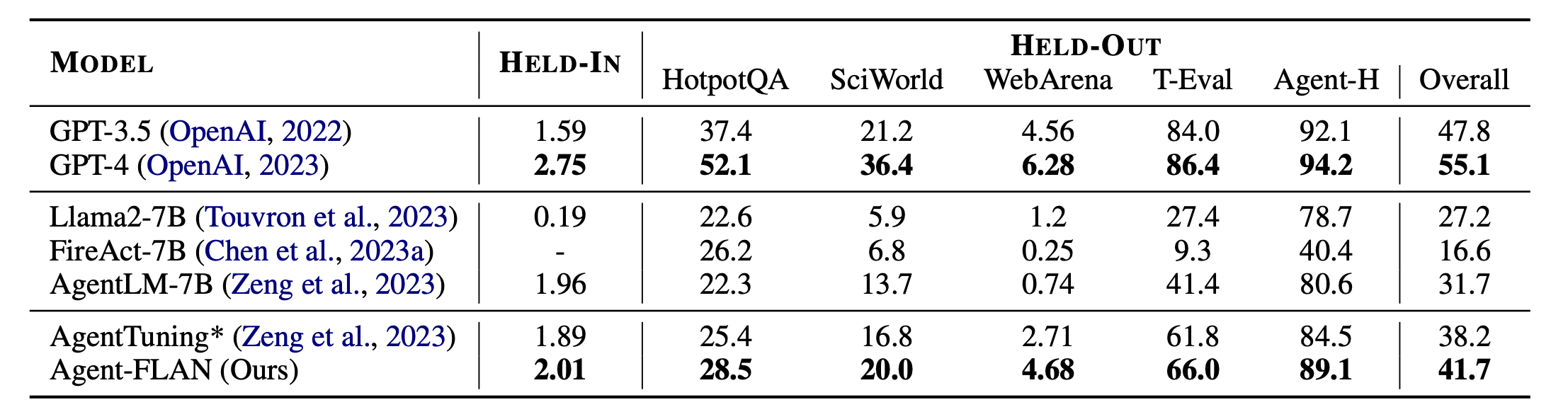
Agent-FLAN的主要结果。 Agent-FLAN 在保留任务和保留任务上都大大优于以前的代理调整方法。 * 表示我们使用相同数量的训练数据重新实现,以便进行公平比较。由于 FireAct 不在 AgentInstruct 数据集上进行训练,因此我们忽略了它在 HELD-IN 集上的性能。 Bold:基于 API 的最佳开源模型。
Agent-FLAN是用Lagent和T-Eval构建的。感谢他们出色的工作!
如果您发现该项目对您的研究有用,请考虑引用:
@article{chen2024agent,
title={Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models},
author={Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng},
journal={arXiv preprint arXiv:2403.12881},
year={2024}
}
该项目是在 Apache 2.0 许可证下发布的。


