T2M GPT
1.0.0
论文“T2M-GPT:通过离散表示的文本描述生成人体运动”的 Pytorch 实现
[项目页面] [论文] [笔记本演示] [HuggingFace] [太空演示] [T2M-GPT+]

如果我们的项目对您的研究有帮助,请考虑引用:
@inproceedings{zhang2023generating,
title={T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations},
author={Zhang, Jianrong and Zhang, Yangsong and Cun, Xiaodong and Huang, Shaoli and Zhang, Yong and Zhao, Hongwei and Lu, Hongtao and Shen, Xi},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023},
}
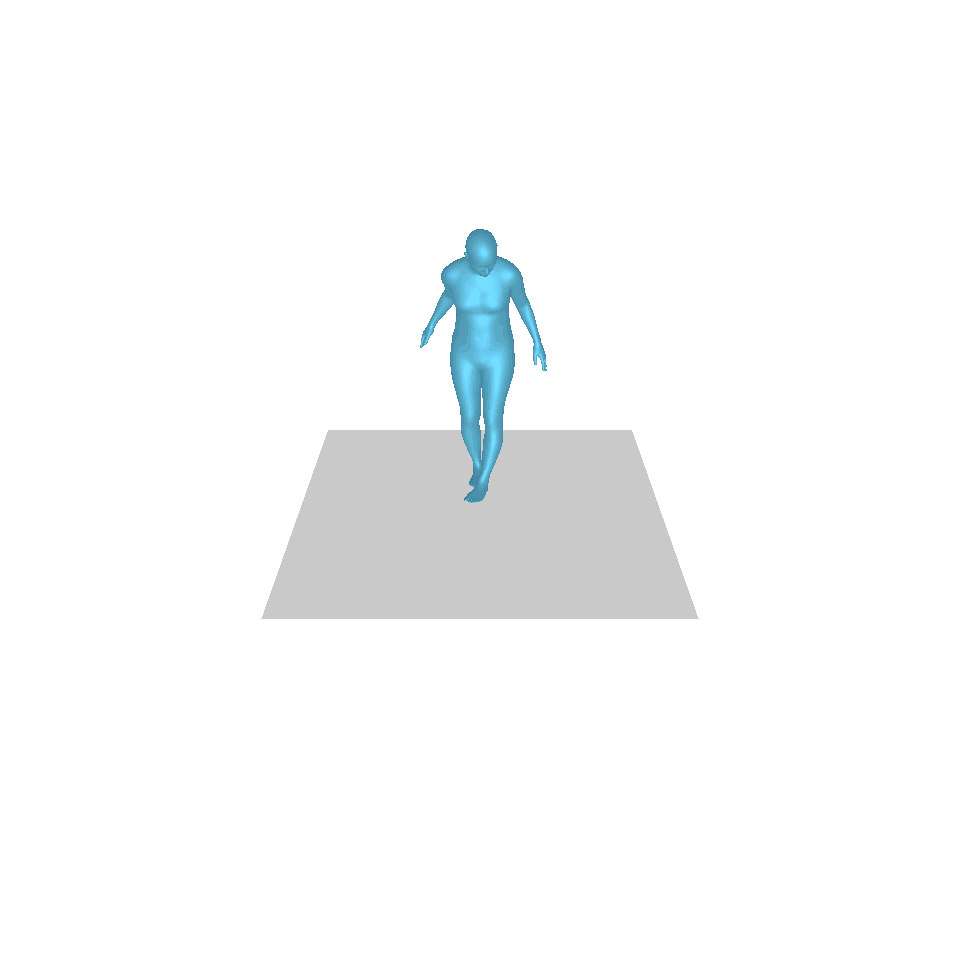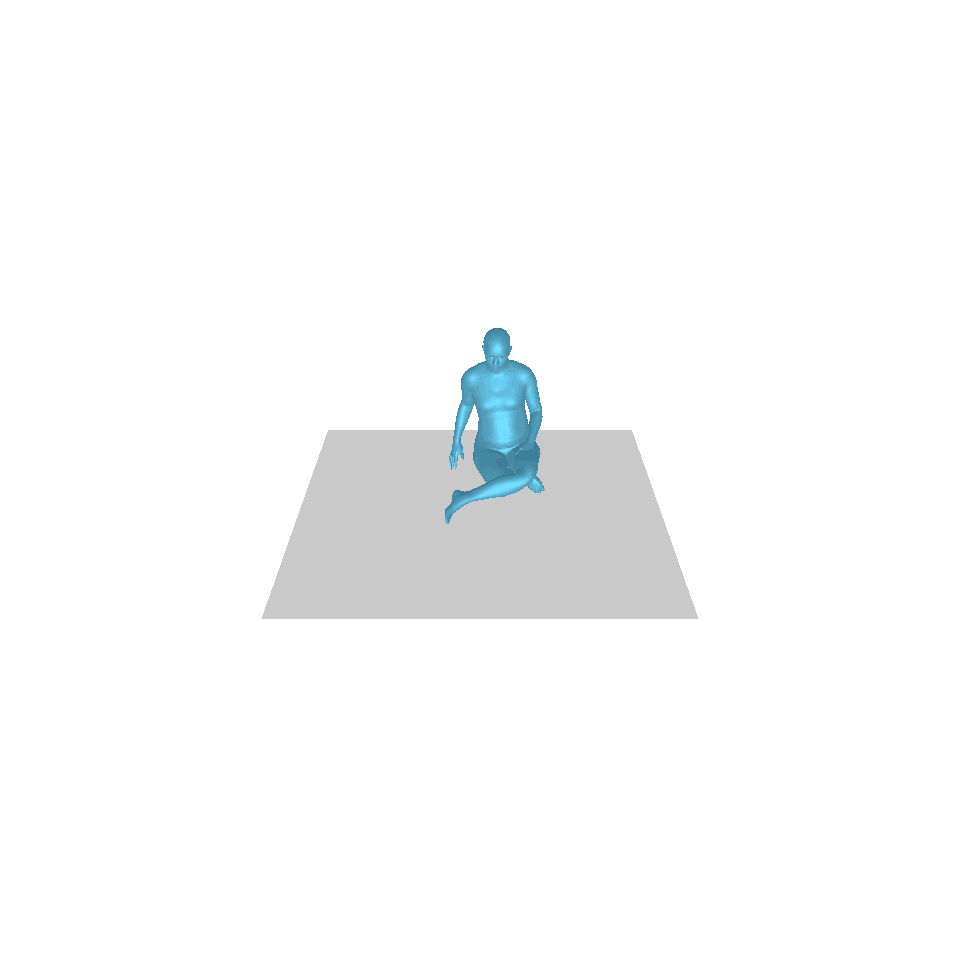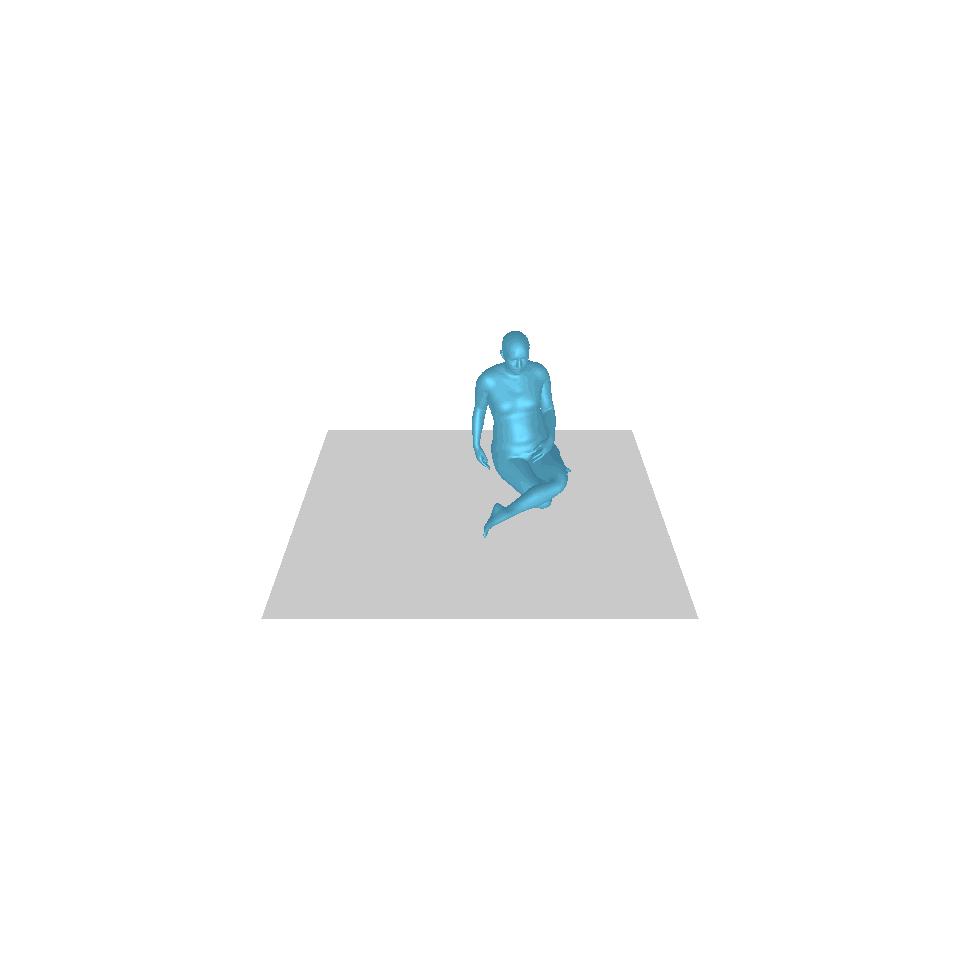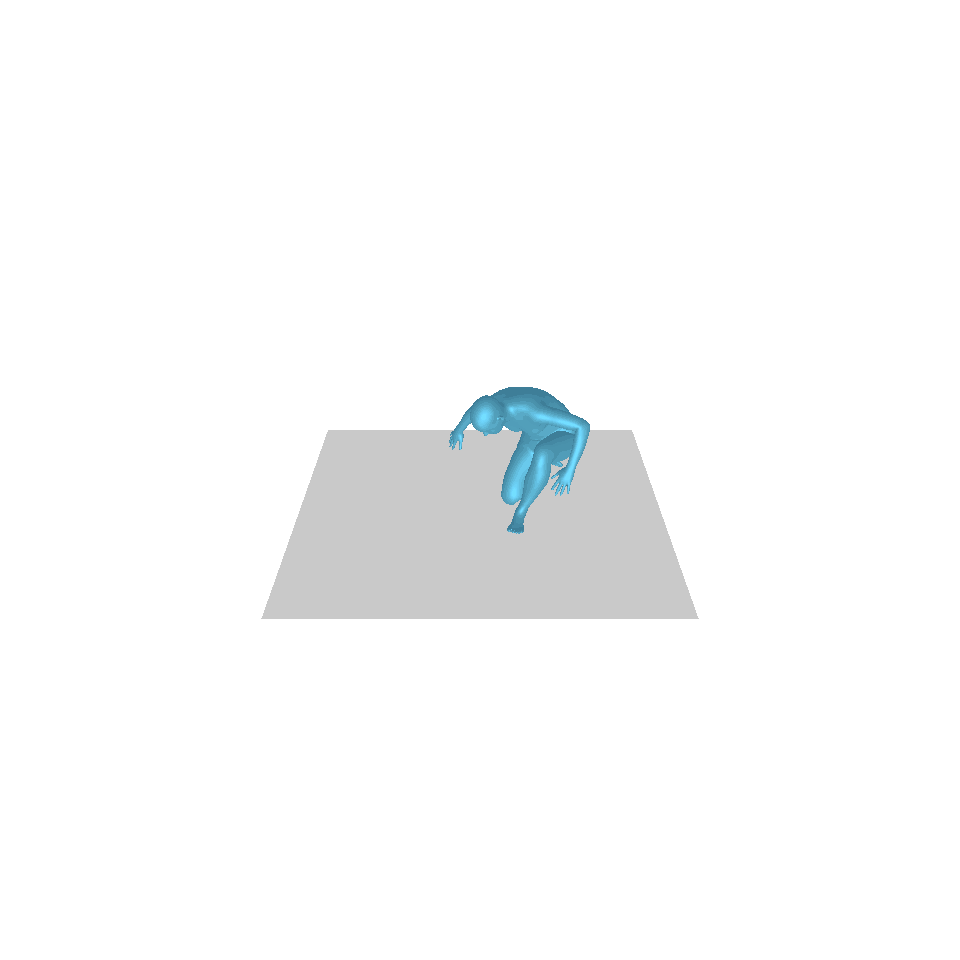
| 文字:一名男子向前迈出并倒立。 | ||||
|---|---|---|---|---|
| GT | T2M | 主数据管理 | 运动漫反射 | 我们的 |
 | 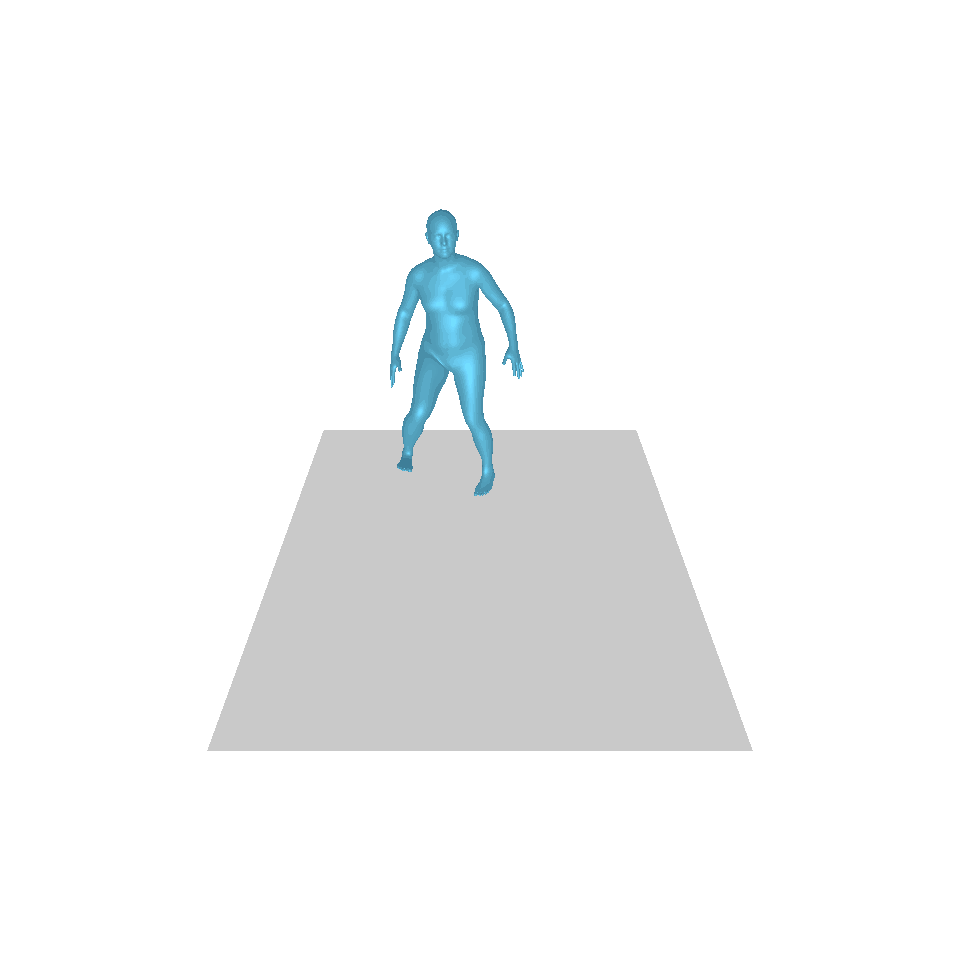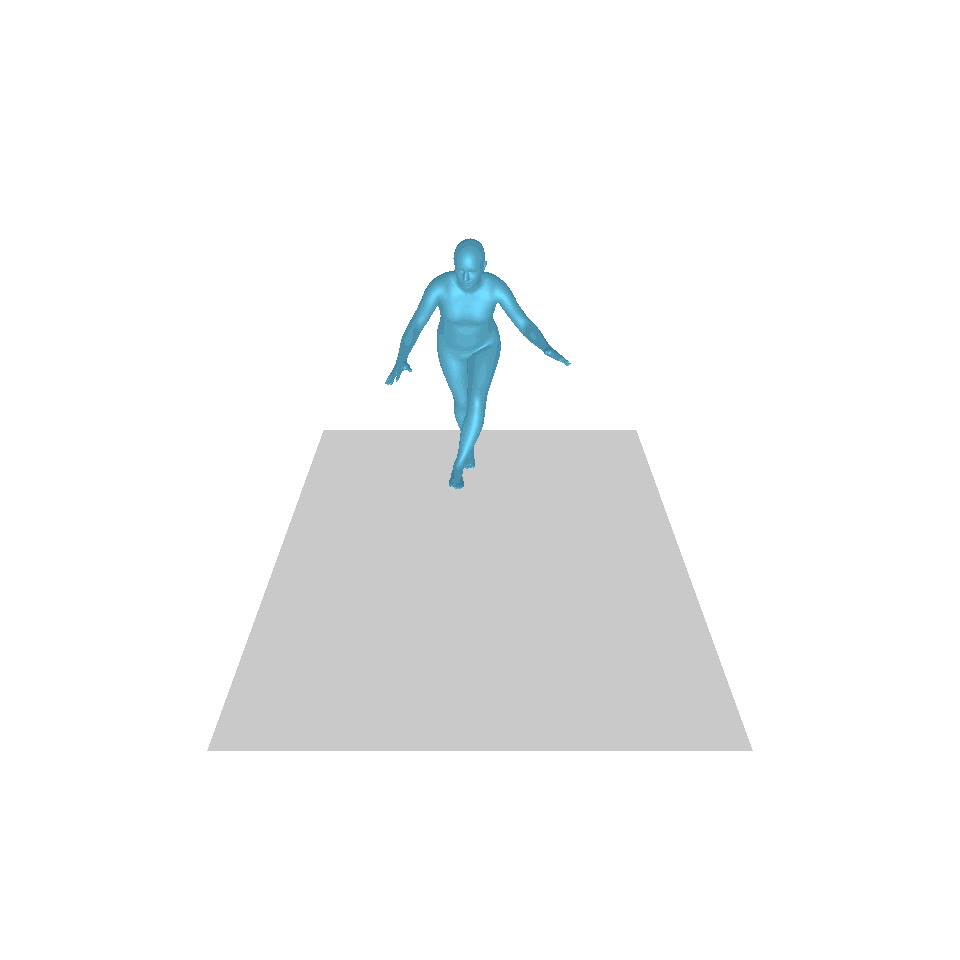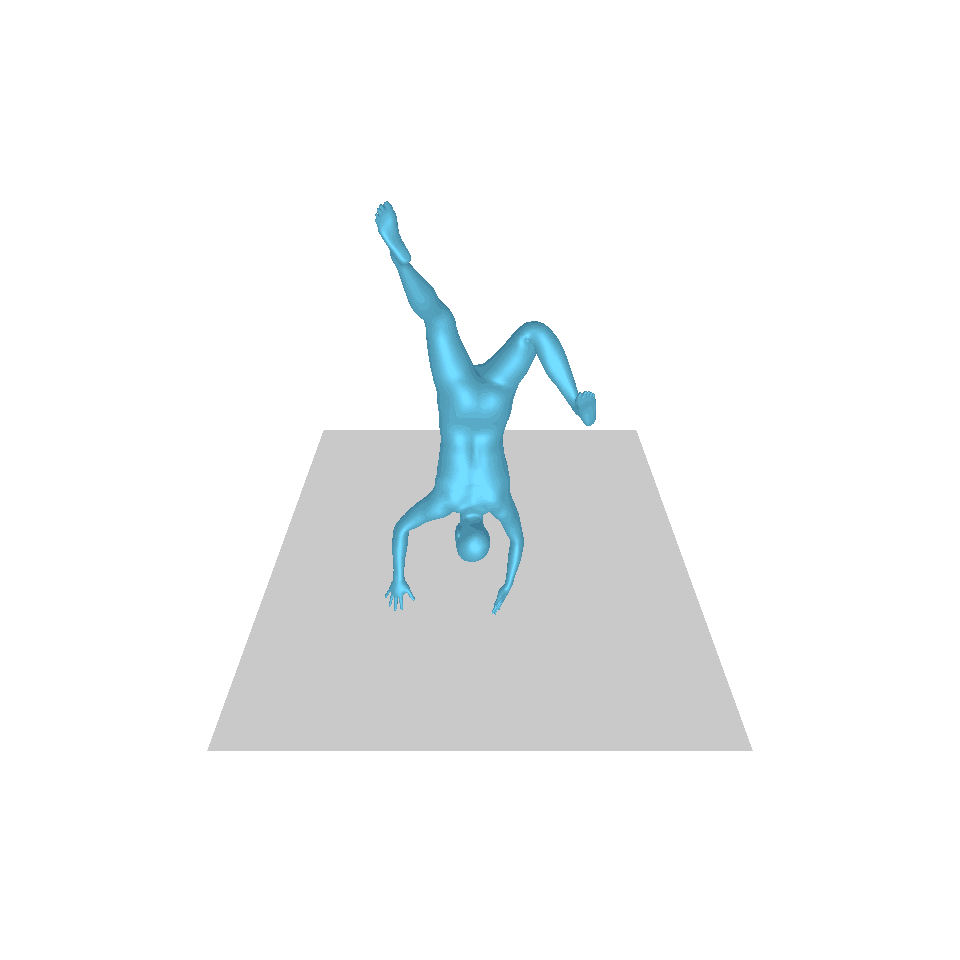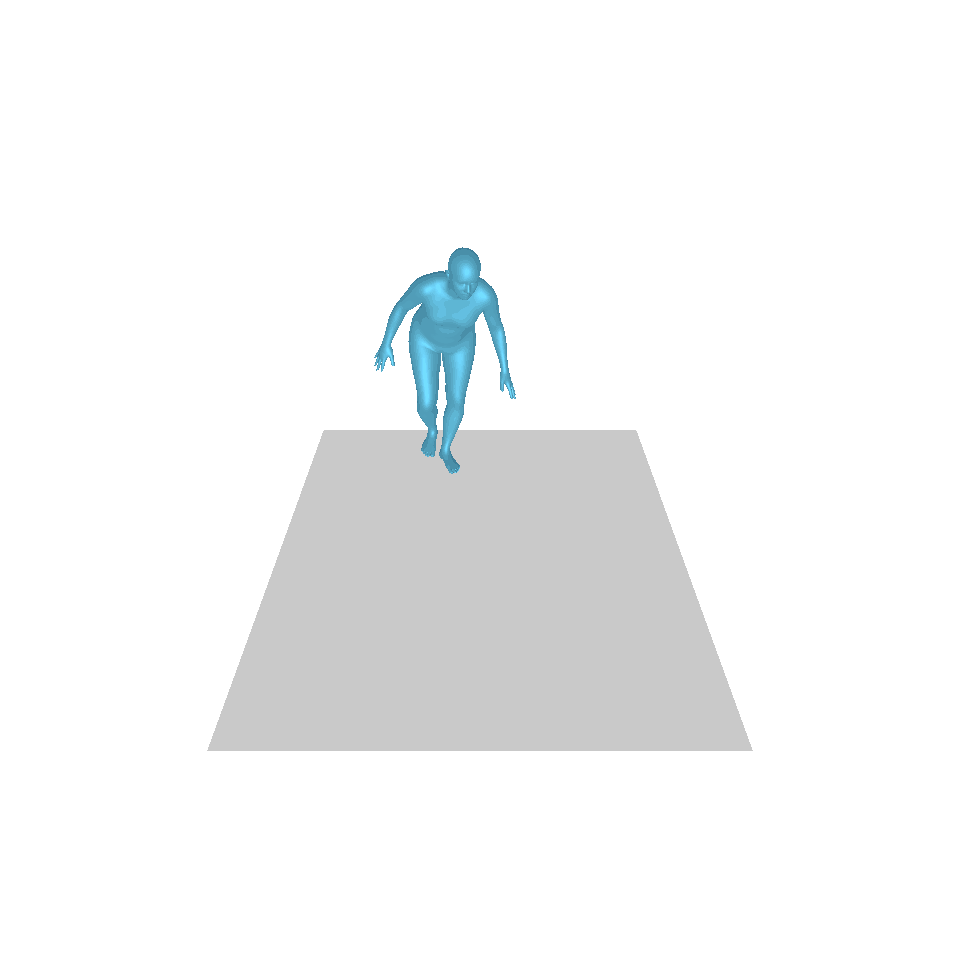 |  | 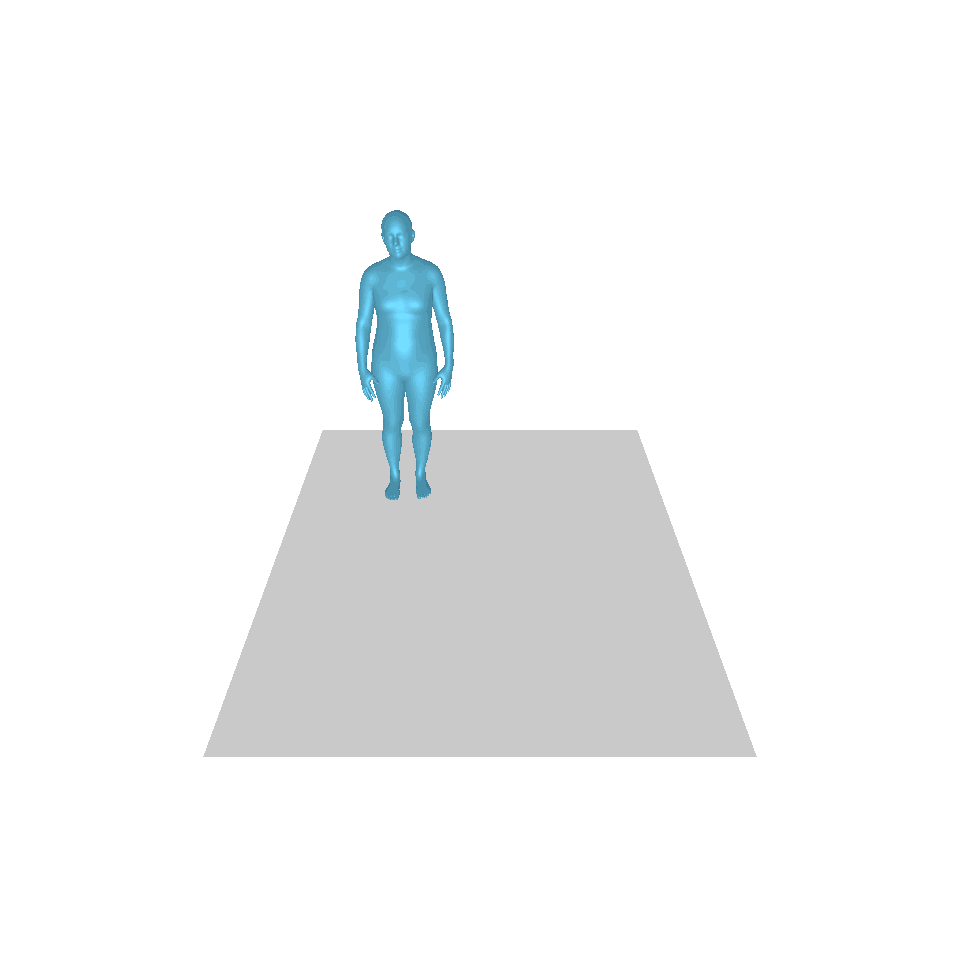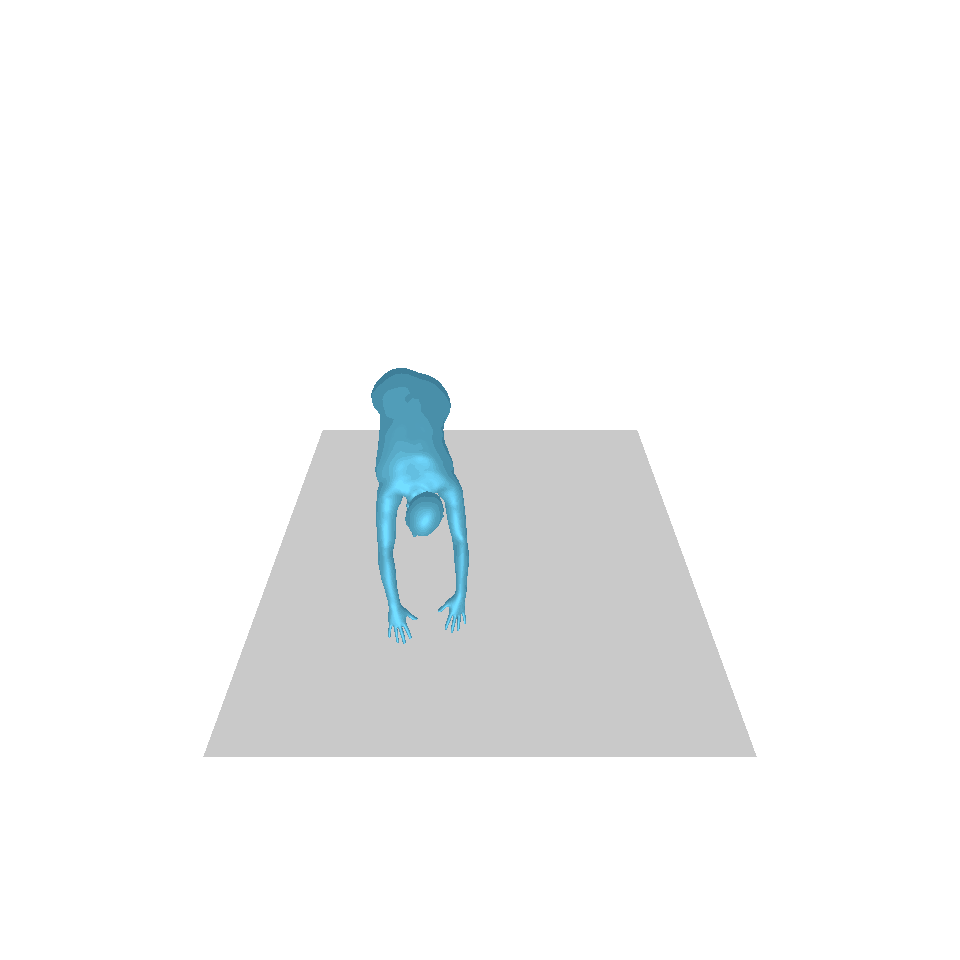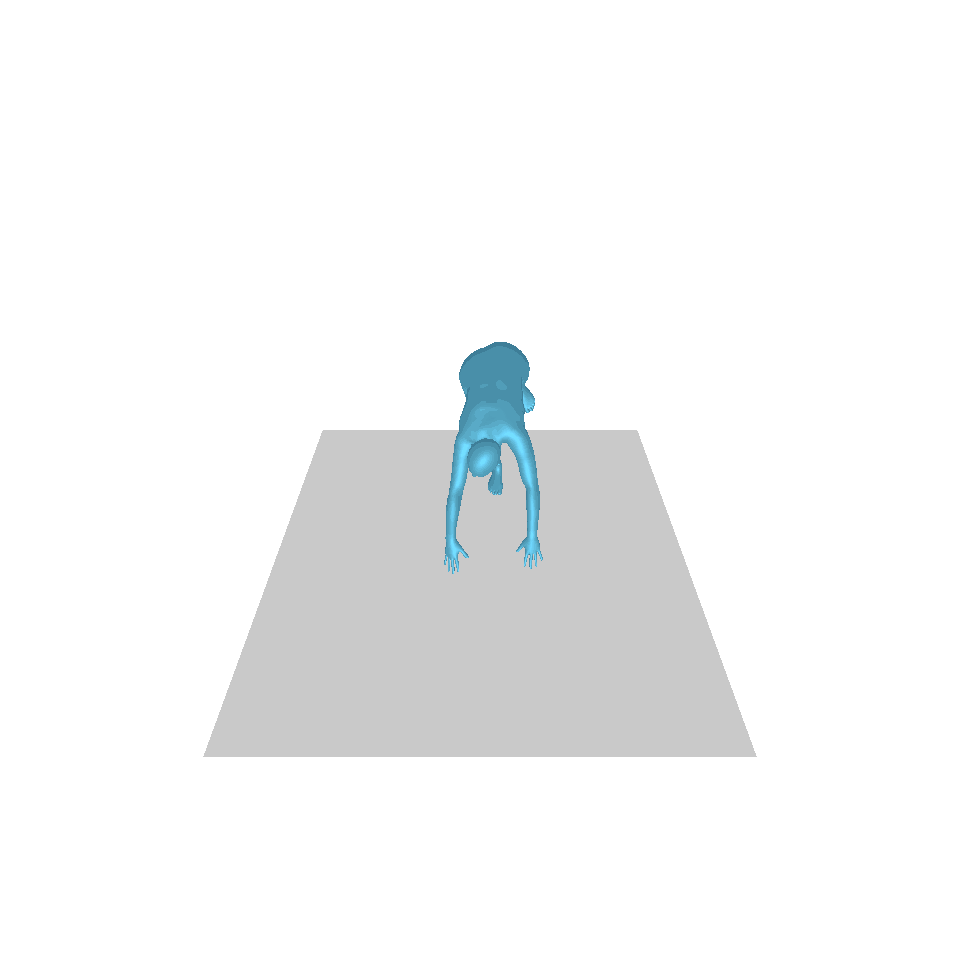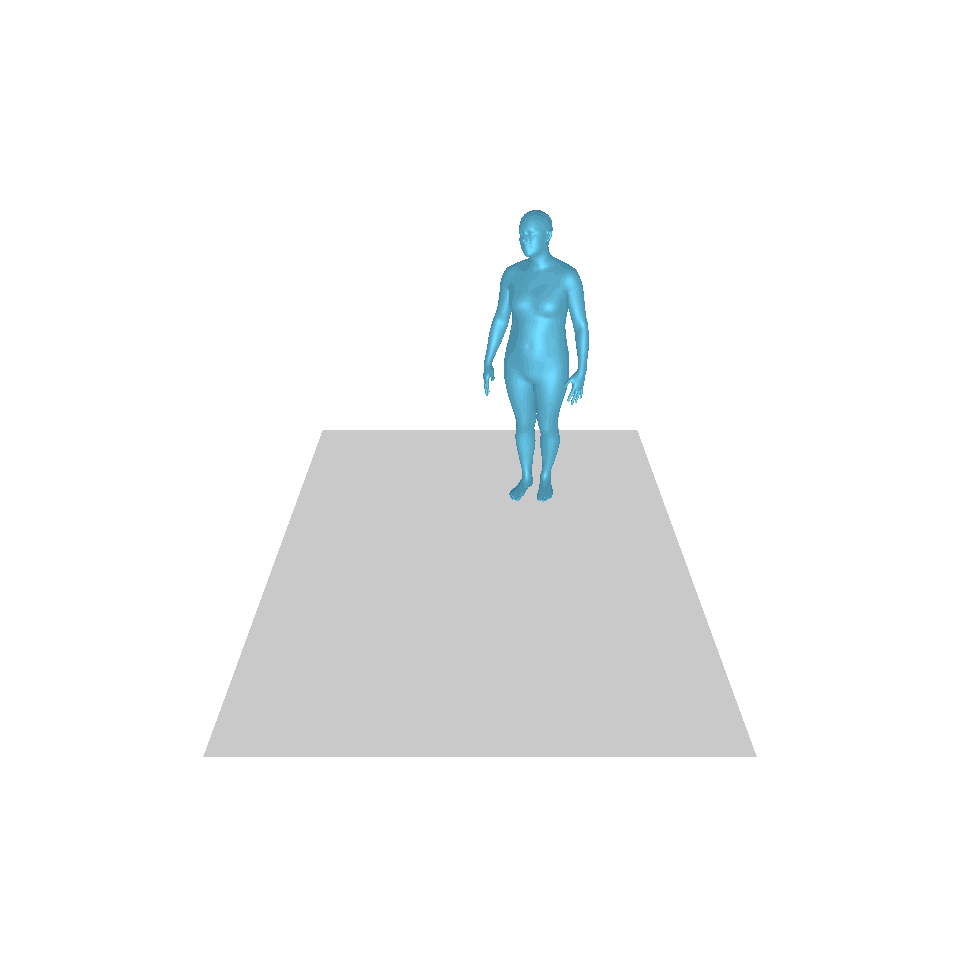 | 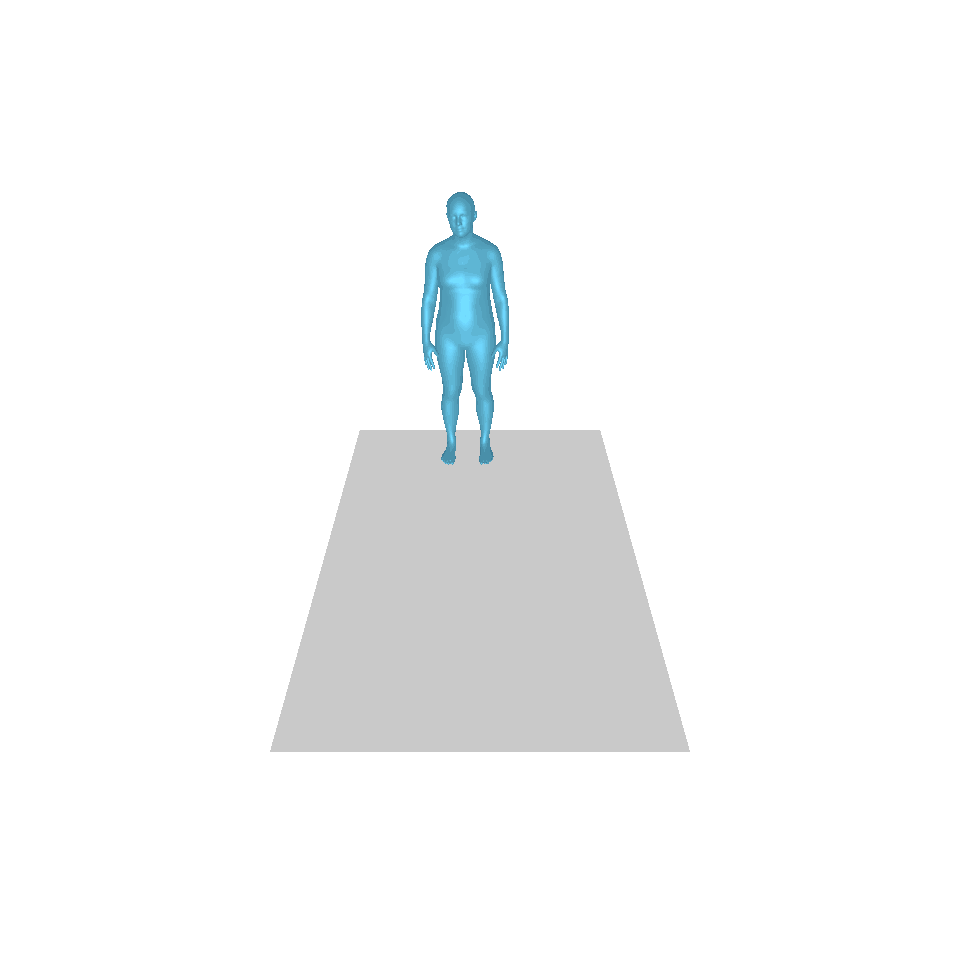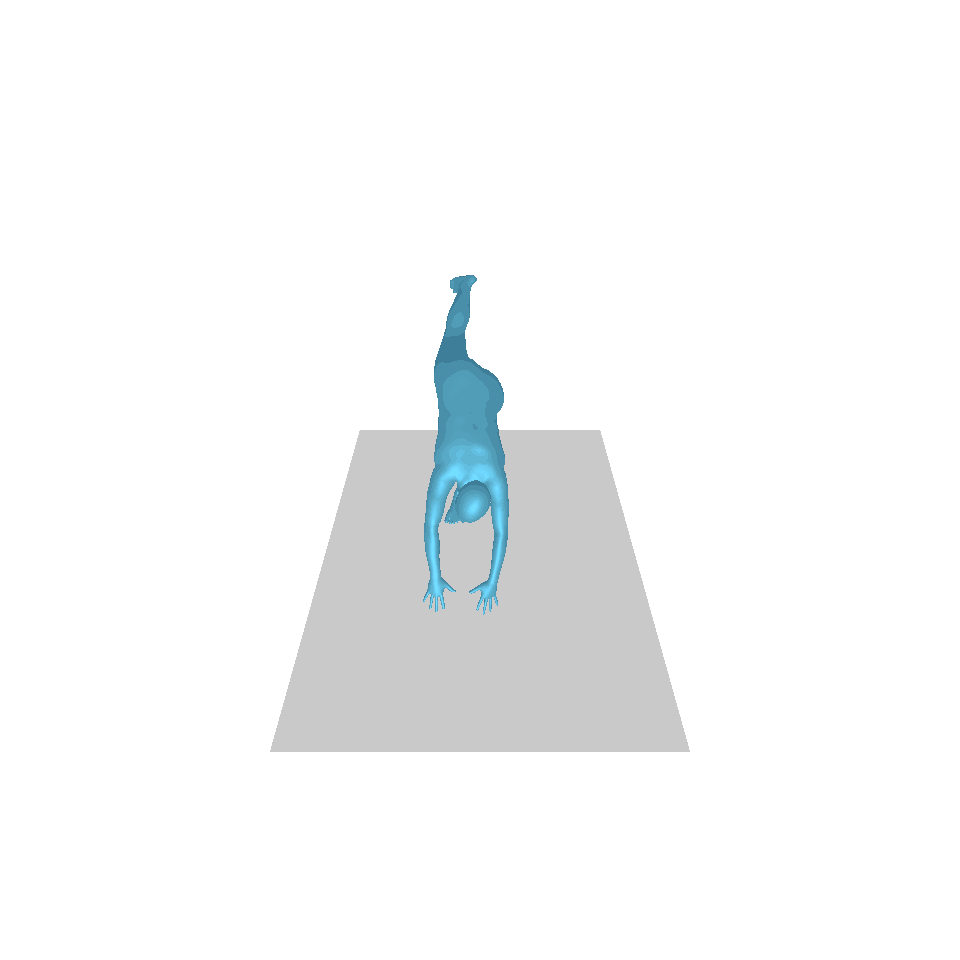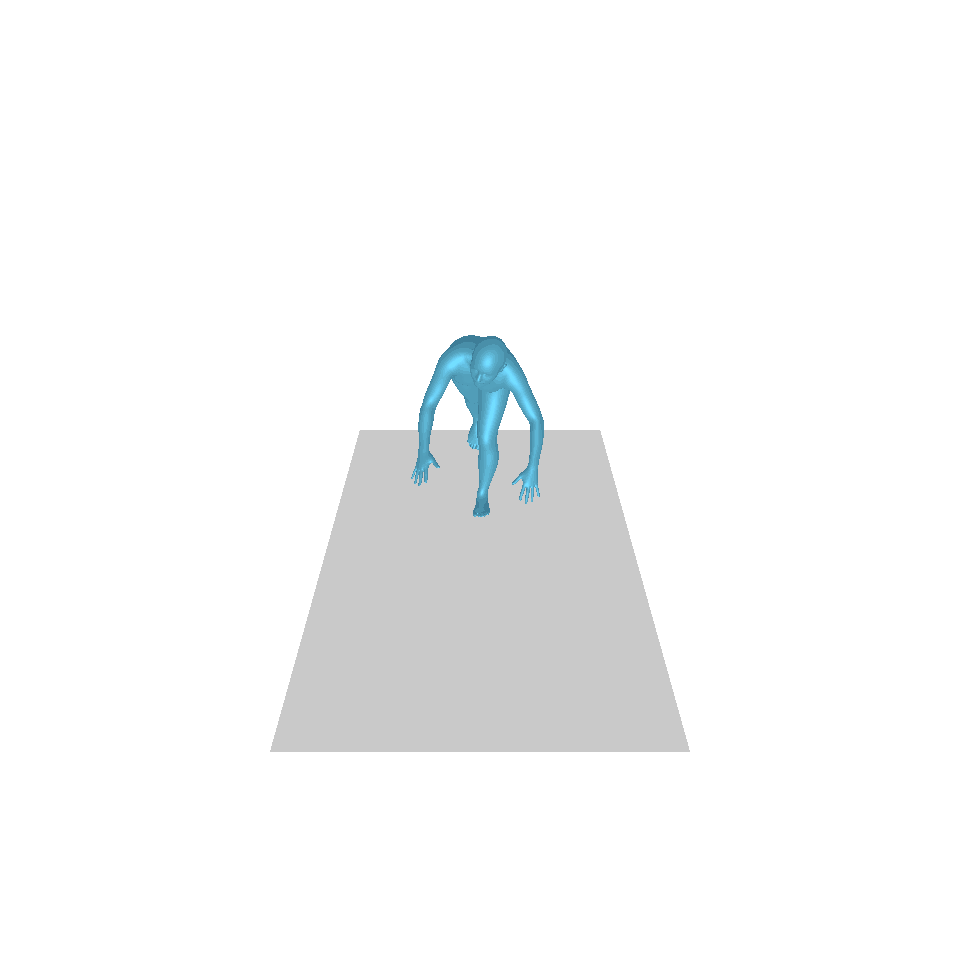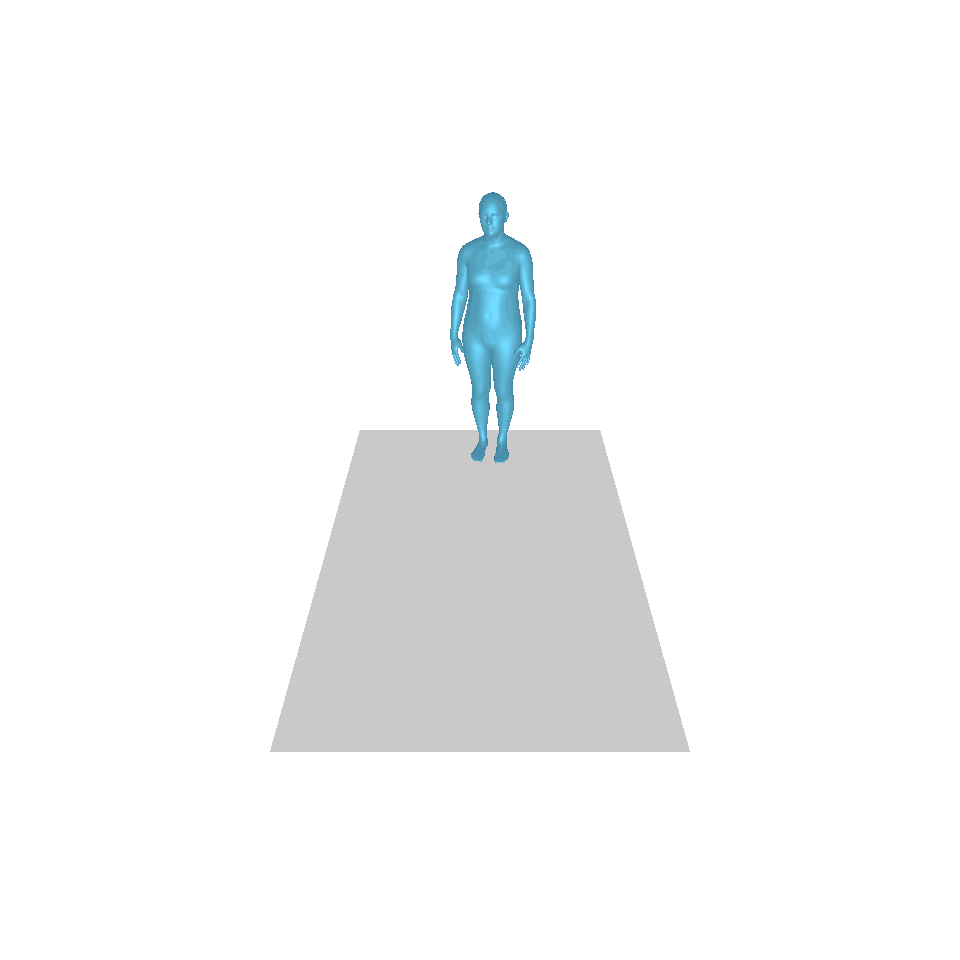 |
| 文本:一个人从地上站起来,绕了一圈,然后坐回到地上。 | ||||
| GT | T2M | 主数据管理 | 运动漫反射 | 我们的 |
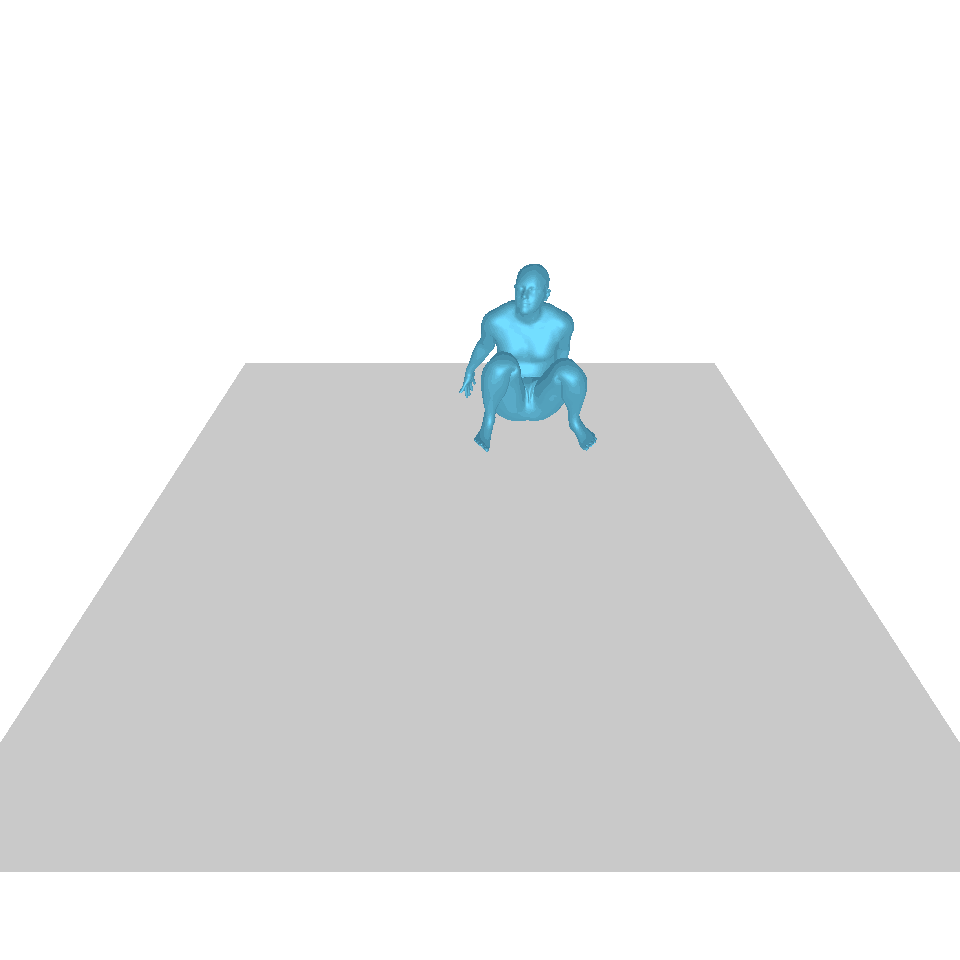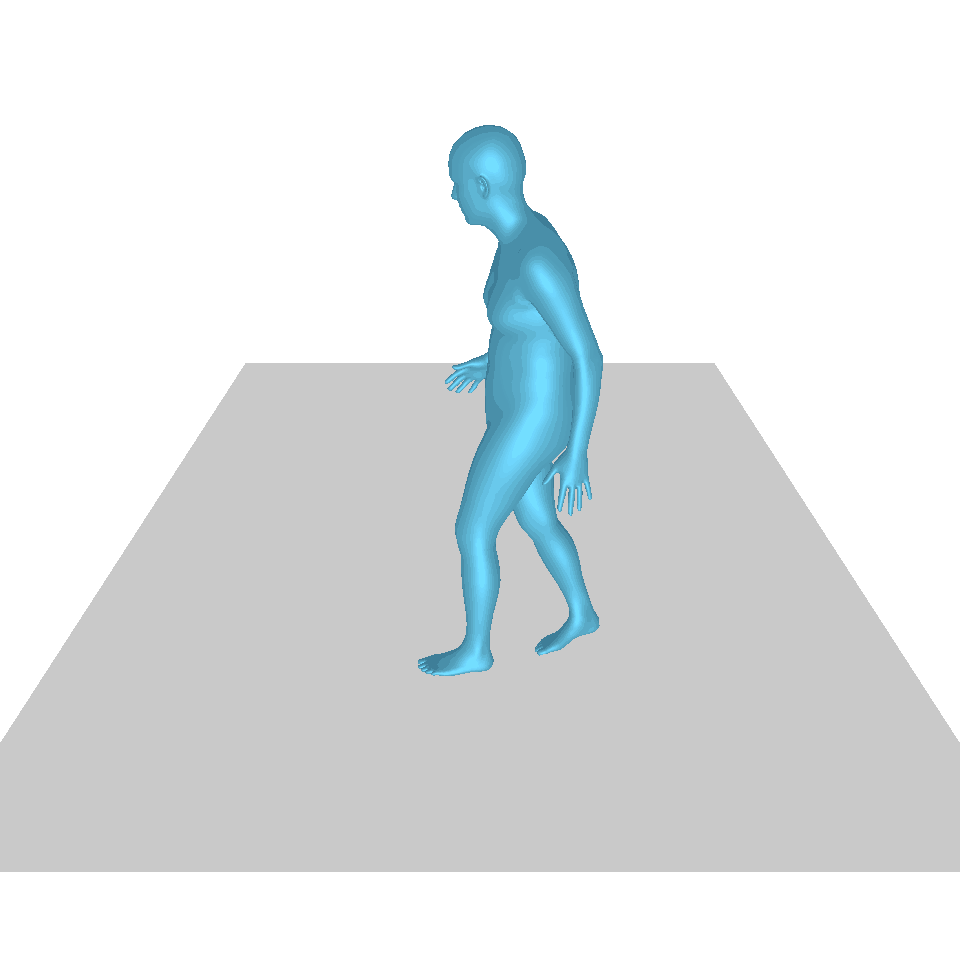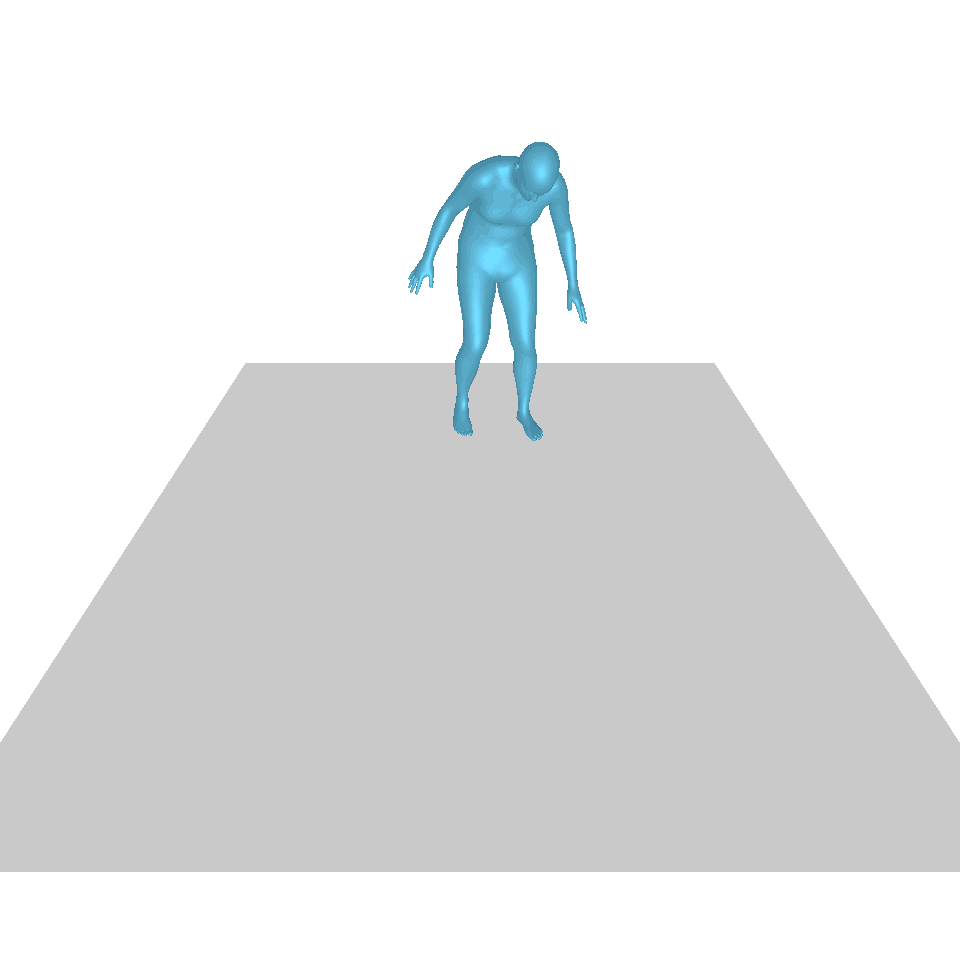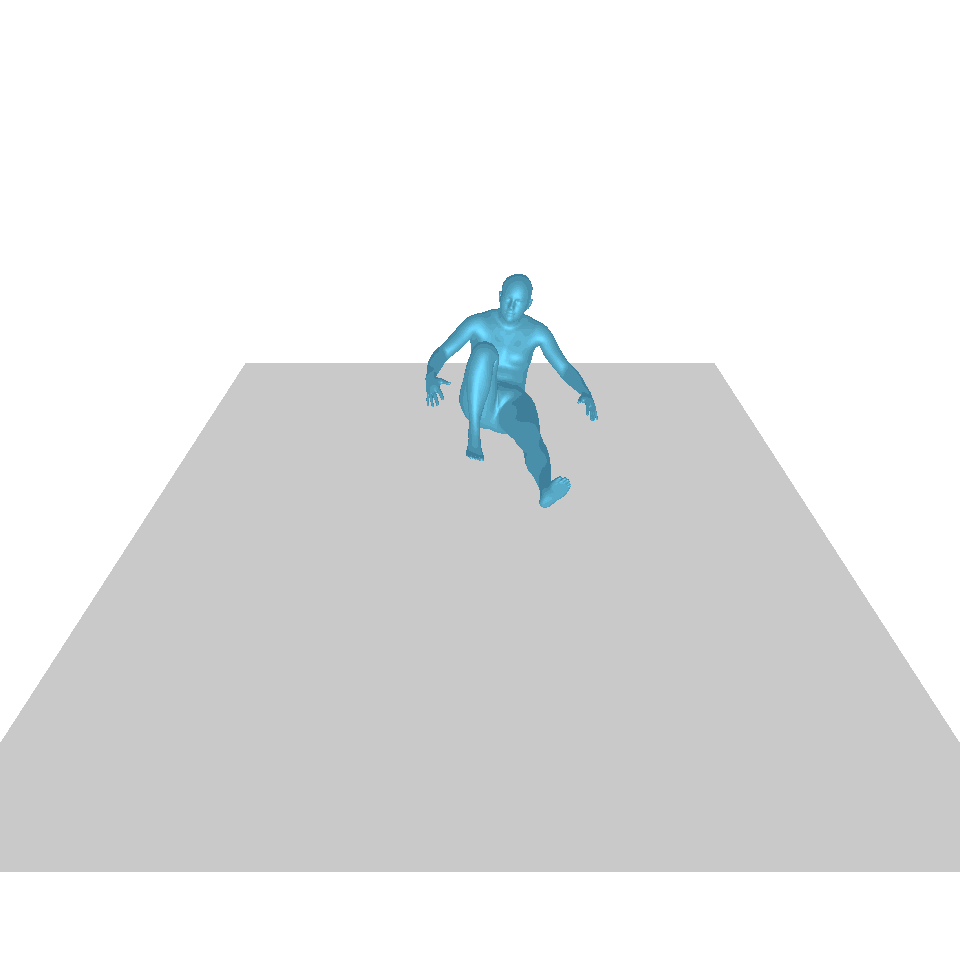 | 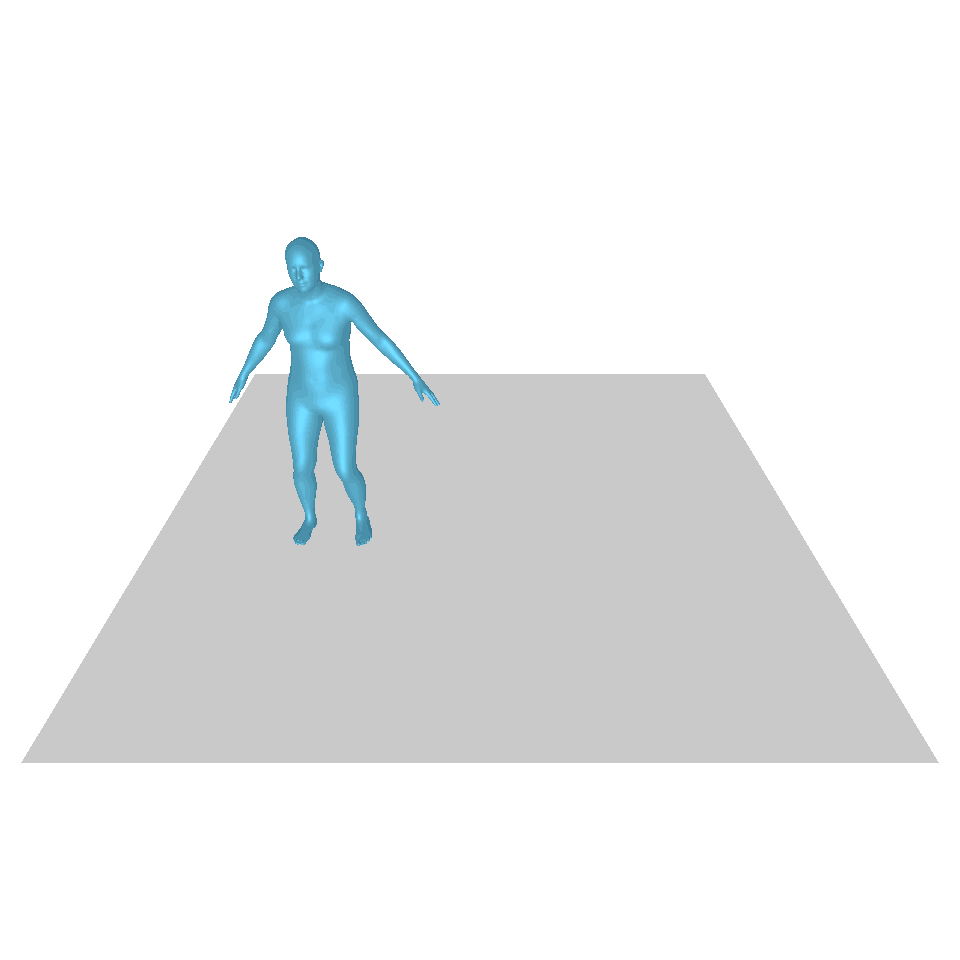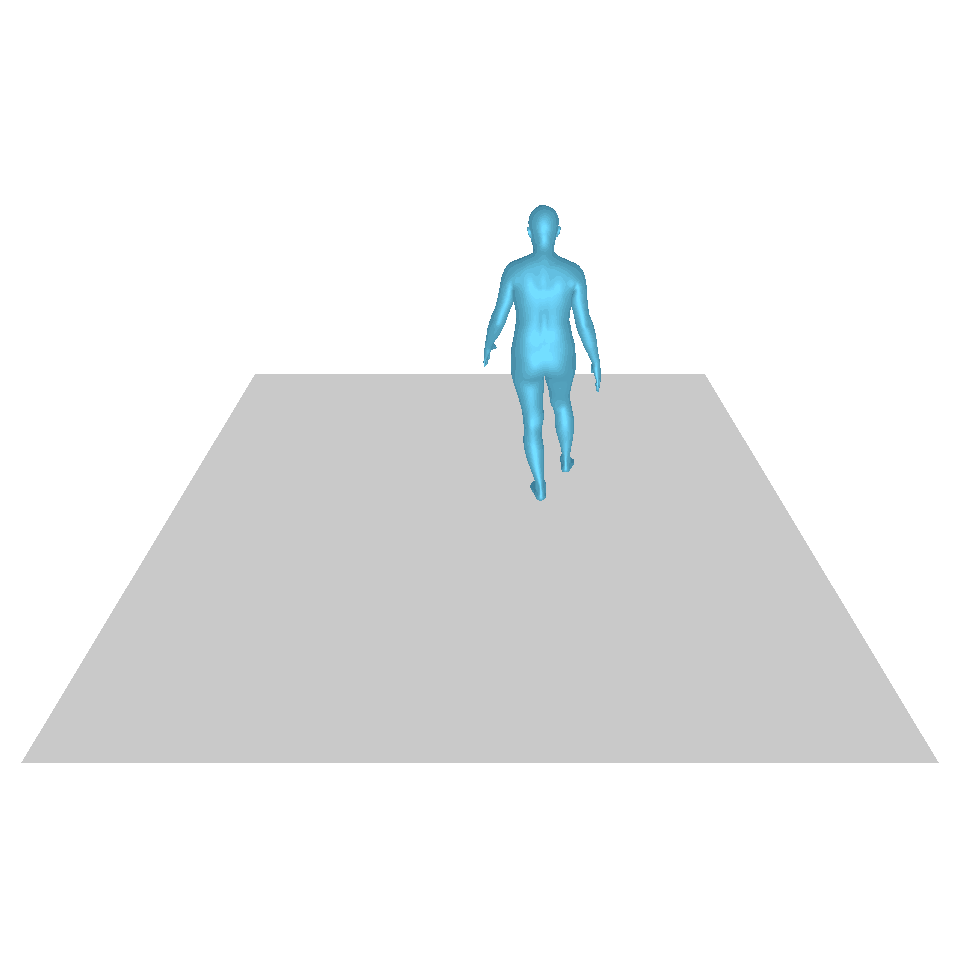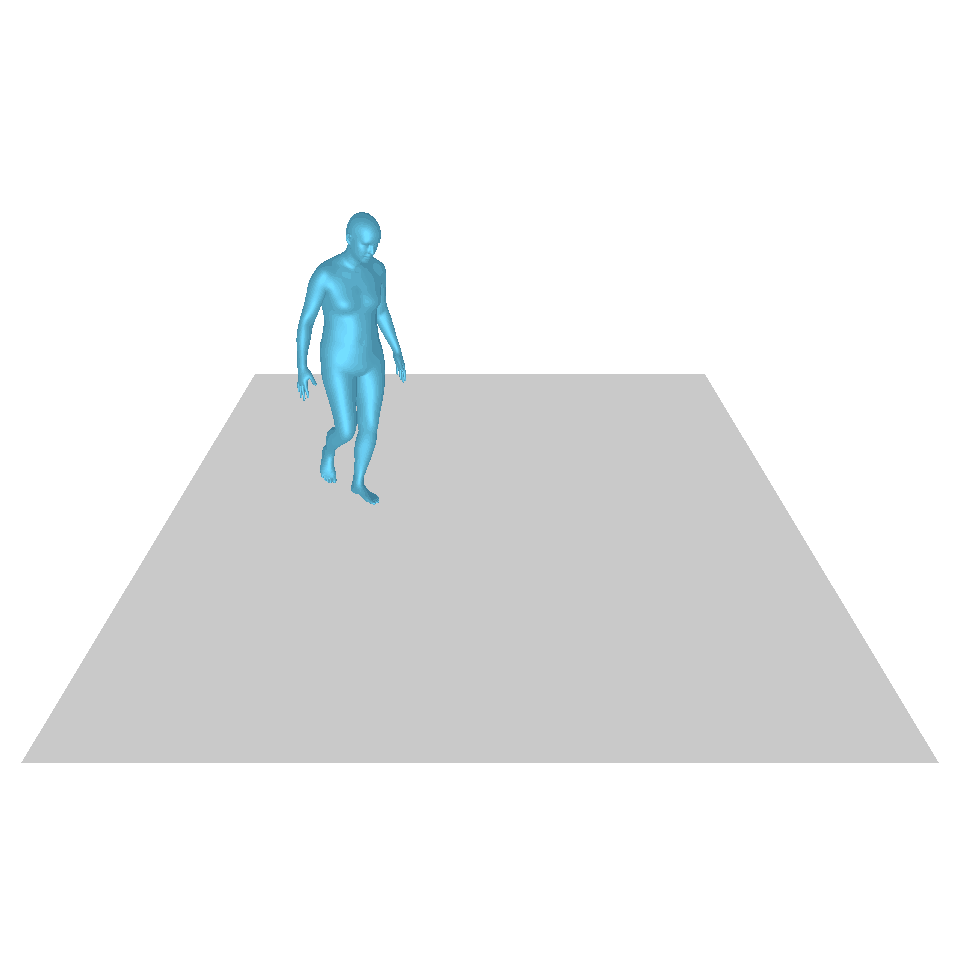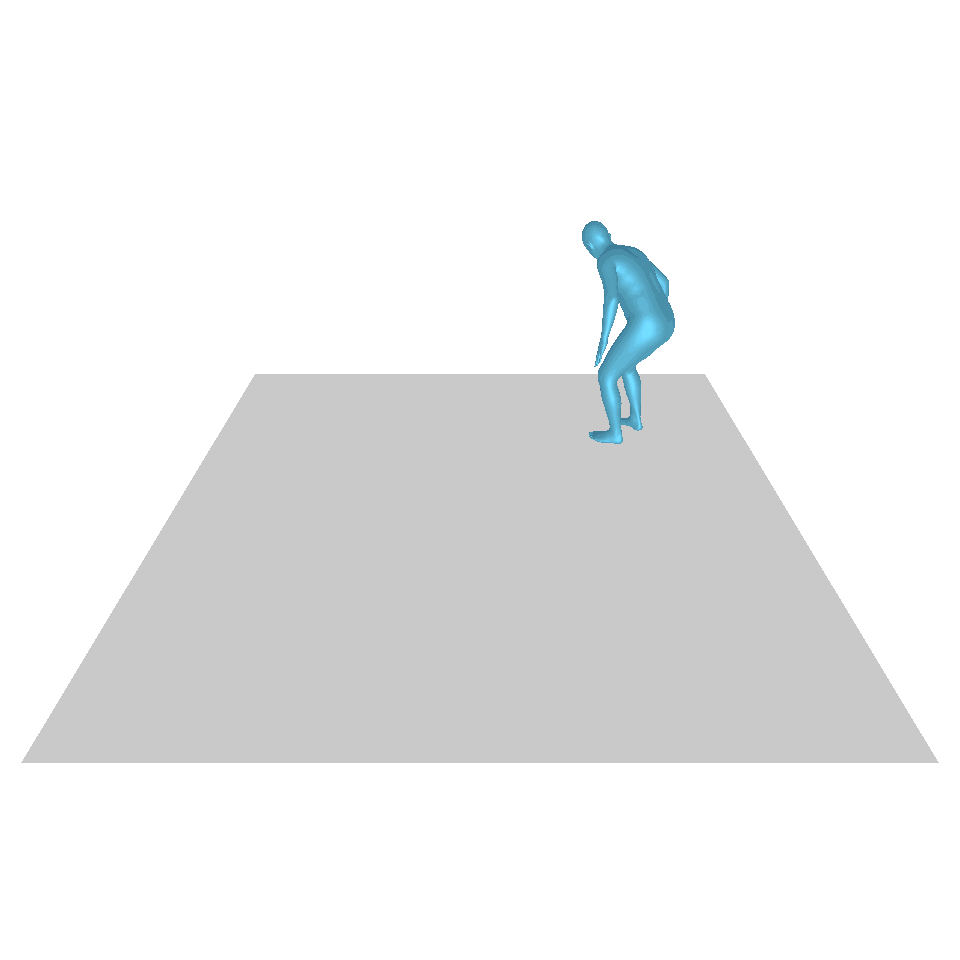 |  |  |  |
我们的模型可以在单个 GPU V100-32G中学习
conda env create -f environment.yml
conda activate T2M-GPT该代码在 Python 3.8 和 PyTorch 1.8.1 上进行了测试。
bash dataset/prepare/download_glove.sh我们使用两个 3D 人体动作语言数据集:HumanML3D 和 KIT-ML。对于这两个数据集,您可以在[此处]找到详细信息以及下载链接。
以HumanML3D为例,文件目录应如下所示:
./dataset/HumanML3D/
├── new_joint_vecs/
├── texts/
├── Mean.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── Std.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── train.txt
├── val.txt
├── test.txt
├── train_val.txt
└── all.txt
我们使用 t2m 提供的相同提取器来评估我们生成的运动。请下载提取器。
bash dataset/prepare/download_extractor.sh预训练的模型文件将存储在“pretrained”文件夹中:
bash dataset/prepare/download_model.sh如果你想渲染生成的运动,你需要安装:
sudo sh dataset/prepare/download_smpl.sh
conda install -c menpo osmesa
conda install h5py
conda install -c conda-forge shapely pyrender trimesh mapbox_earcutdemo.ipynb 提供了如何使用我们的代码的快速入门指南
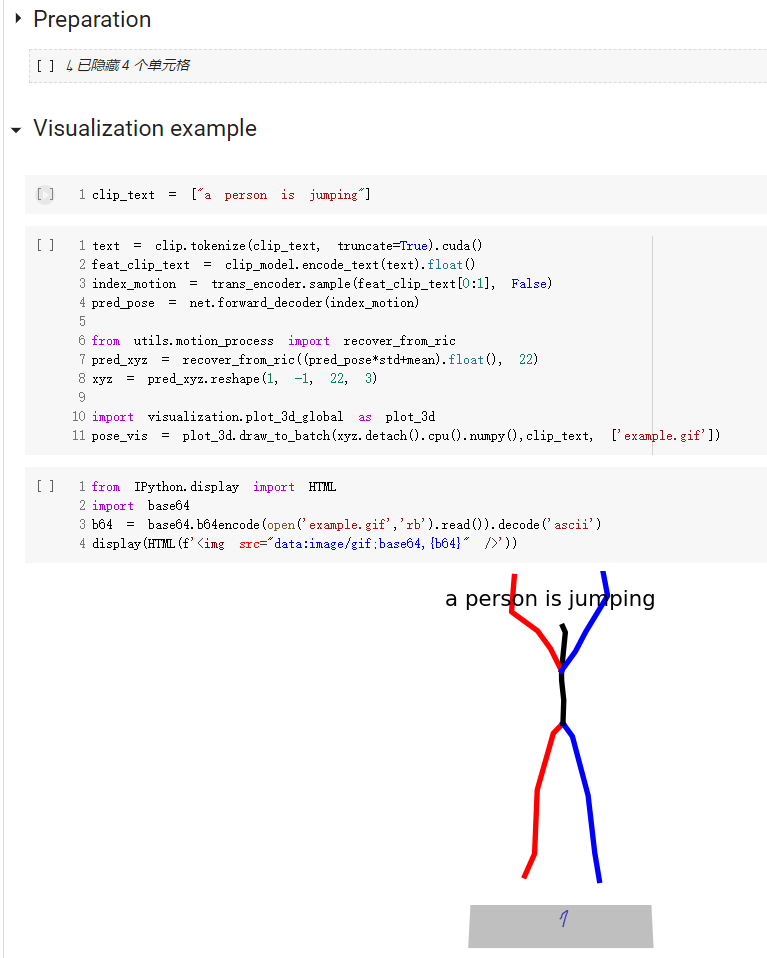
注意,对于kit数据集,只需要设置'--dataname kit'。
结果保存在输出文件夹中。
python3 train_vq.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name VQVAE结果保存在输出文件夹中。
python3 train_t2m_trans.py
--exp-name GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relupython3 VQ_eval.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name TEST_VQVAE
--resume-pth output/VQVAE/net_last.pth按照文本到动作的评估设置,我们评估我们的模型 20 次并报告平均结果。由于多模态部分我们需要从同一文本生成 30 个动作,因此评估需要很长时间。
python3 GPT_eval_multi.py
--exp-name TEST_GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relu
--resume-trans output/GPT/net_best_fid.pth您应该输入 npy 文件夹地址和动作名称。这是一个例子:
python3 render_final.py --filedir output/TEST_GPT/ --motion-list 000019 005485我们感谢以下人员的帮助:


