spelltest
v0.0.4
?如果您觉得这个项目有用,请考虑给它一颗星!您的支持是我不断进步的动力! ?
当今的人工智能驱动的应用程序在很大程度上依赖于 GPT-4 等大型语言模型 (LLM) 来提供创新的解决方案。然而,确保他们在每种情况下都能提供相关且准确的响应是一项挑战。 Spelltest 通过使用合成用户角色模拟 LLM 响应以及自动评估这些响应的评估技术(但仍然需要人工监督)来解决这个问题。
spellforge.yaml文件中描述你的模拟: project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

您现在可以通过 Google Colab 在基于网络的交互环境中尝试这个项目!无需安装。
只需点击上面的徽章即可开始!
有保证的质量:模拟用户交互以获得最佳响应。
效率和节省:节省手动测试成本。
流畅的工作流程集成:无缝融入您的开发流程。
请注意,这是拼写测试的早期版本。因此,它尚未在不同的环境和用例中进行广泛的测试。决定使用此版本即表示您接受使用 Spelltest 框架并自行承担风险。我们强烈鼓励用户报告他们遇到的任何问题或错误,以协助改进项目。
关于运营成本,需要注意的是,使用 Spelltest 运行模拟会根据 OpenAI API 的使用情况产生费用。目前没有成本估算或预算限制。就上下文而言,运行一批 100 个模拟可能花费大约 0.7 到 1.8 美元 (gpt-3.5-turbo),具体取决于包括特定 LLM 和模拟复杂性在内的多个因素。
考虑到这些成本,我们强烈建议从少量的模拟开始,这样既可以降低初始成本,又可以帮助您更好地估计未来的费用。随着您更加熟悉该框架及其成本影响,您可以根据您的预算和需求调整模拟数量。
请记住,Spelltest 的目标是确保 LLM 提供高质量的响应,同时在 AI 开发和测试过程中尽可能保持成本效益。

Spelltest 采用独特的质量保证方法。通过使用合成用户角色,我们不仅可以模拟交互,还可以捕获独特的用户期望,为测试提供丰富的上下文环境。这种背景深度使我们能够以密切反映现实世界应用的方式评估法学硕士回答的质量。
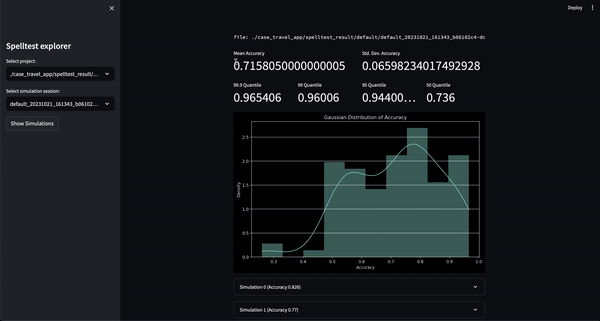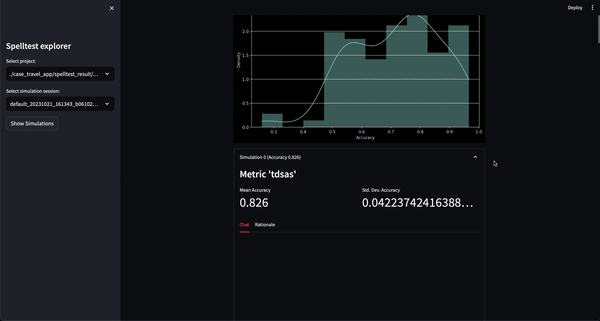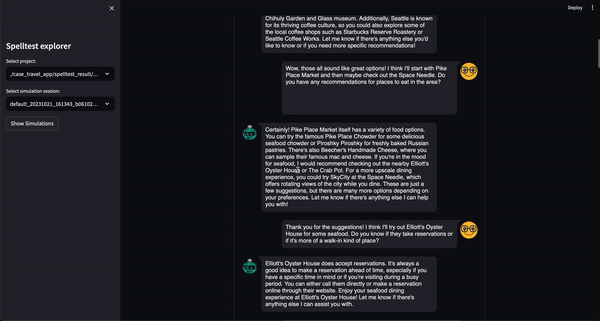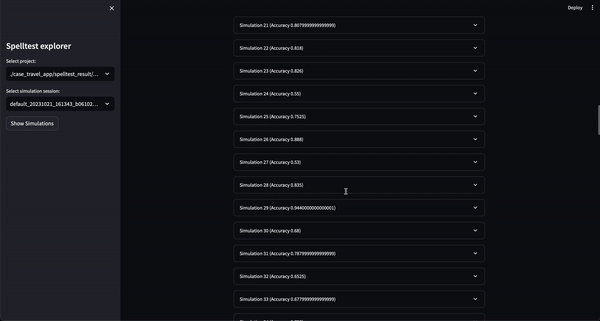
结果呢?质量分数范围从 0.0 到 1.0,充当您的应用在与真实用户见面之前的全面彩排。无论是在聊天还是完成模式下,Spelltest 都能确保 LLM 响应与用户期望紧密结合,从而提高总体用户满意度。
使用 pip 安装框架:
pip install spelltest.spellforge.yaml是 Spelltest 的核心,包含综合用户配置文件、指标、提示和模拟。下面是其结构的细分:
合成用户模仿现实世界的用户,每个用户都有独特的背景、期望和对应用程序的理解。合成用户的配置包括:
子提示:这些是为用户配置文件提供上下文的描述性元素。它们包括:
description :关于合成用户的简介。expectation :用户对交互的期望。user_knowledge_about_app :对应用程序的熟悉程度。每个合成用户还有一个:
name :合成用户的标识符。llm_name :要使用的 LLM 模型(仅在 OpenAI 模型上测试)。temperature : ...综合用户配置示例:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
...指标用于评估法学硕士的回答并对其进行评分。每个指标都包含一个子提示description ,提供有关指标评估内容的上下文。
简单指标配置示例:
...
metrics :
accuracy :
description : " Accuracy "
...复杂/自定义指标配置示例:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
...提示是应用程序提出的问题或任务。这些用于模拟,以测试法学硕士生成合适响应的能力。每个提示都定义有description和实际的prompt文本或任务。
...
prompts :
book_flight :
file : book-flight-prompt.txt
...模拟指定测试场景。关键元素包括prompt 、 users 、 llm_name 、 temperature 、 size 、 chat_mode和quality_threshold 。
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
带有提示文件的完整配置在这里。
OpenAI 成本:使用此框架可能会导致对 OpenAI 的大量请求,特别是在运行大量模拟时。这可能会导致您的 OpenAI 帐户产生大量费用。确保您留意 OpenAI 预算并了解定价模型。我对由此产生的任何费用不承担任何责任。
早期发布:此版本的 Spelltest 处于早期阶段,没有稳定性保证。请谨慎使用,并随时提供反馈或报告问题。
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yaml检查模拟结果。
spelltest --analyze将 Spelltest 集成到您的发布管道中可以通过合并一致的自动化测试来增强您的部署策略。这一关键步骤通过在发布之前系统地模拟和评估用户交互来确保您的基于 LLM 的应用程序保持高质量标准。这种做法可以节省大量时间,减少手动错误,并提供有关更改或新功能将如何影响用户体验的关键见解。
本指南将引导您完成为项目设置和自动化持续集成的过程。
在开始之前,请确保您具备以下先决条件:
包含您的项目的 GitHub 存储库。
使用 API 密钥访问 SpellForge。如果您没有,可以从 SpellForge 网站获取。
用于使用 OpenAI 服务的 OpenAI API 密钥。如果没有,可以从 OpenAI 网站获取。
.spellforge.yaml在项目的根目录中创建.spellforge.yaml文件。该文件将包含拼写测试的说明。
创建 GitHub Actions 工作流程文件,例如 .github/workflows/.spelltest.yaml,以自动执行 SpellForge 测试。将以下代码插入到该文件中:
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATH每次推送到主分支时都会触发此工作流程,并将运行您的 SpellForge 测试。
转到 GitHub 存储库并导航到“设置”选项卡。
在“秘密”下添加两个新秘密:
OPENAI_API_KEY :将此密钥设置为您的 OpenAI API 密钥。
添加GitHub环境变量:
SPELLTEST_CONFIG_PATH :将此变量设置为存储库中 .spellforge.yaml 文件的完整路径。
这些模拟具有特定特征和期望的真实用户交互。
用户背景( .spellforge.yaml中的description字段):一个子提示,概述了这个合成用户是谁以及他们想要使用该应用程序解决的问题,例如,旅行者管理他们的日程安排。
用户期望( expectation字段):一个子提示,定义综合用户期望通过使用应用程序实现成功的交互或解决方案。
环境感知( user_knowledge_about_app字段):确保综合用户了解应用程序上下文的子提示,确保真实的测试场景。
子提示,代表用于评估和评分 LLM 在模拟中生成的响应的标准或标准。指标的范围可以从一般测量到更特定于应用程序的自定义指标。
一般指标示例:
语义相似度:衡量所提供的答案在含义上与预期答案的相似程度。
毒性:评估对任何可能被认为不适当或有害的语言或内容的响应。
结构相似性:将生成的响应的结构和格式与预定义的标准或预期输出进行比较。
更多自定义指标示例:
TPAS(旅行计划准确度分数) :“该指标通过评估预期输出的包含情况和拟议旅行计划的质量来衡量生成的响应的准确性。TPAS 是一个介于 0 到 100 之间的数值,其中 100 代表完美与预期输出匹配,0 表示结果不准确。”
EES(同理心参与评分) :“EES 评估法学硕士回答的同理心共鸣。通过评估消息中的理解、验证和支持元素,对所传达的同理心水平进行评分。EES 范围从 0 到 100,其中 100 表示高度同理心反应,而 0 表示缺乏同理心参与。”
使用 Spelltest 让您的 LLM 申请变得更好!


