paperchat
1.0.0
欢迎来到 arXivchat!
arXivchat 是基于法学硕士的软件,可让您以对话方式谈论 arXiv 发表的论文。它作为 cli 工具、API 提供程序和 ChatGPT 插件运行。
由转发运营商制造。我们与一些最聪明的人合作开展法学硕士和机器学习相关项目。
非常欢迎您做出贡献!
请按照以下步骤快速设置和运行 arXiv 插件:
如果尚未安装,请安装 Python 3.10。
克隆存储库: git clone https://github.com/Forward-Operators/arxivchat.git
导航到克隆的存储库目录: cd /path/to/arxivchat
安装诗歌: pip install poetry
使用Python 3.10创建新的虚拟环境: poetry env use python3.10
激活虚拟环境: poetry shell
安装应用程序依赖项: poetry install
设置所需的环境变量:
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
本地运行 API: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
访问 http://0.0.0.0:8000/docs 处的 API 文档并测试 API 端点。
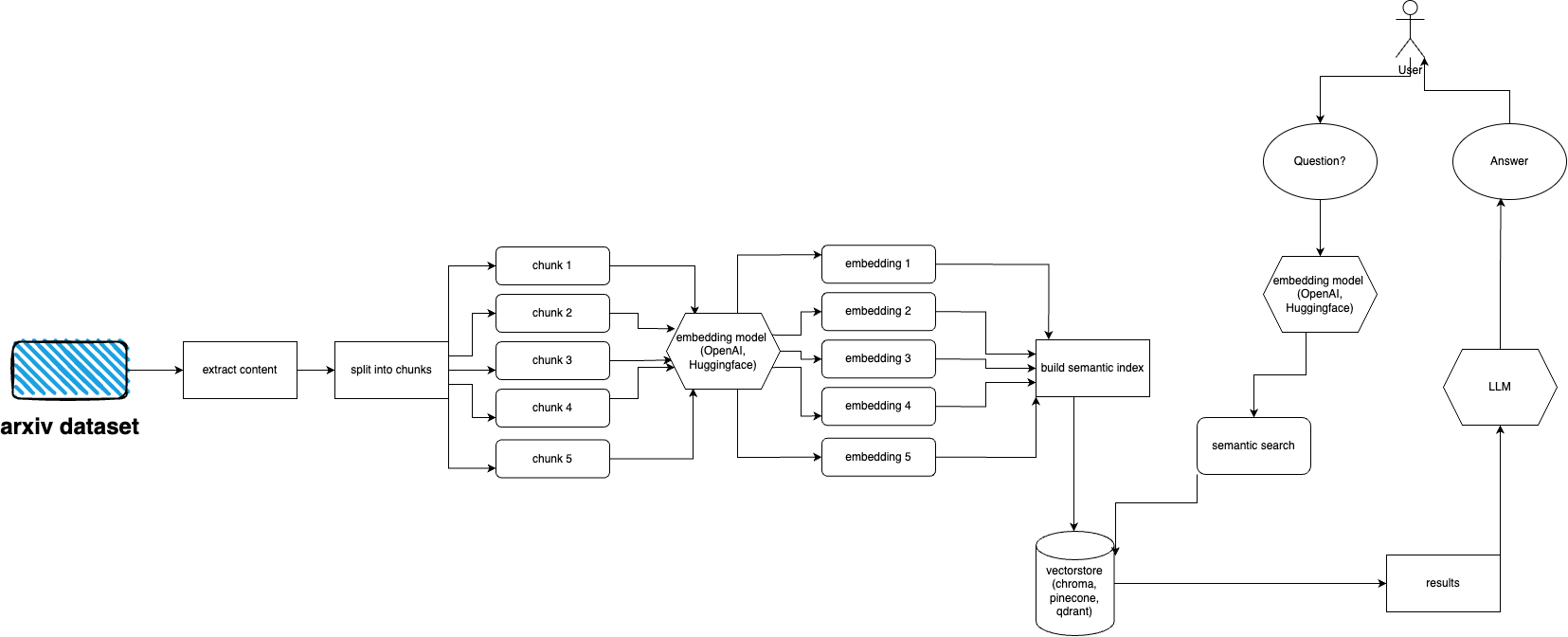
arXiv 拥有近 200 万篇出版物的数据集。从他们的网站获取太多数据是违反 arXiv 的服务条款的(因为它会产生负载)。幸运的是,kaggle 的优秀人员与康奈尔大学一起创建了一个可供您使用的公开数据集。该数据集可通过 Google Cloud Storage 存储桶免费获取,并每周更新。
现在的主要问题是 - 如果我们不想摄取超过 5 TB 的 pdf 文件,如何仅获取整个数据集的子集?数据集按月、按年分为多个目录,因此如果您想获取 2021 年 9 月以来的所有出版物,您可以运行: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
如果您想获取整个数据集: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
但如果您只想获取一个子集(对于给定的类别和日期),请查看download.py文件。
默认情况下,ingester 期望此文件位于/mnt/dataset/arxiv/pdf中,其中包含所有 pdf 文件。
检查并运行python scripy.py来提取数据。如果出现问题,您还可以在那里启用调试。
TODO:也许将其更改为目录加载器TODO:实现 celery 部署并使用工作器进行摄取
python cli.py 
询问有关您之前输入数据库的主题的问题。还返回有关源的信息,连续运行。另一种选择是使用 REST API(从app目录运行uvicorn main:app --reload --host 0.0.0.0 --port 8000 )或将其用作 ChatGPT 插件(部署后)
deployment目录中有 terraform 文件。使用最适合您的一种。每个文件中都有 README 文件和说明。您还可以构建一个 Docker 映像并在任何您想要的地方运行它。不过图像文件相当大。
目前可以使用 docker 镜像部署为 Cloud Run,因此它只是 API 部署。数据摄取必须在其他机器上运行(我建议使用支持 GPU 的计算引擎,特别是如果您想使用 Hugging Face 嵌入,并且因为您可以使用gcsfuse直接从 Google Storage 安装数据集)使用 GCS 存储桶与云的潜在解决方案跑步
目前它可以部署为容器应用程序(仅 API 部署,您需要另一个部署来进行摄取)
尚不支持 AWS。即将推出。
arxivchat 默认为 OpenAI 使用text-embedding-ada-002 ,您可以在app/tools/factory.py中更改它
现在您可以使用任何适用于sentence_transformers的模型。您可以在app/tools/factory.py中更改模型
如果您有任何问题,请使用 GitHub issues 报告。
我们希望您能帮助我们让 arXivchat 变得更好!如需贡献,请按照以下步骤操作:
arXivchat 是根据 MIT 许可证发布的。


