guidance for natural language queries of relational databases on aws
1.0.0
此 AWS 解决方案包含生成式 AI 的演示,特别是使用自然语言查询 (NLQ) 向 Amazon RDS for PostgreSQL 数据库提出问题。该解决方案为基础模型提供了三种架构选项:1. Amazon SageMaker JumpStart、2. Amazon Bedrock 和 3. OpenAI API。该演示的基于 Web 的应用程序在 AWS Fargate 上的 Amazon ECS 上运行,结合使用了 LangChain、Streamlit、Chroma 和 HuggingFace SentenceTransformers。该应用程序接受最终用户的自然语言问题并返回自然语言答案,以及关联的 SQL 查询和 Pandas DataFrame 兼容的结果集。
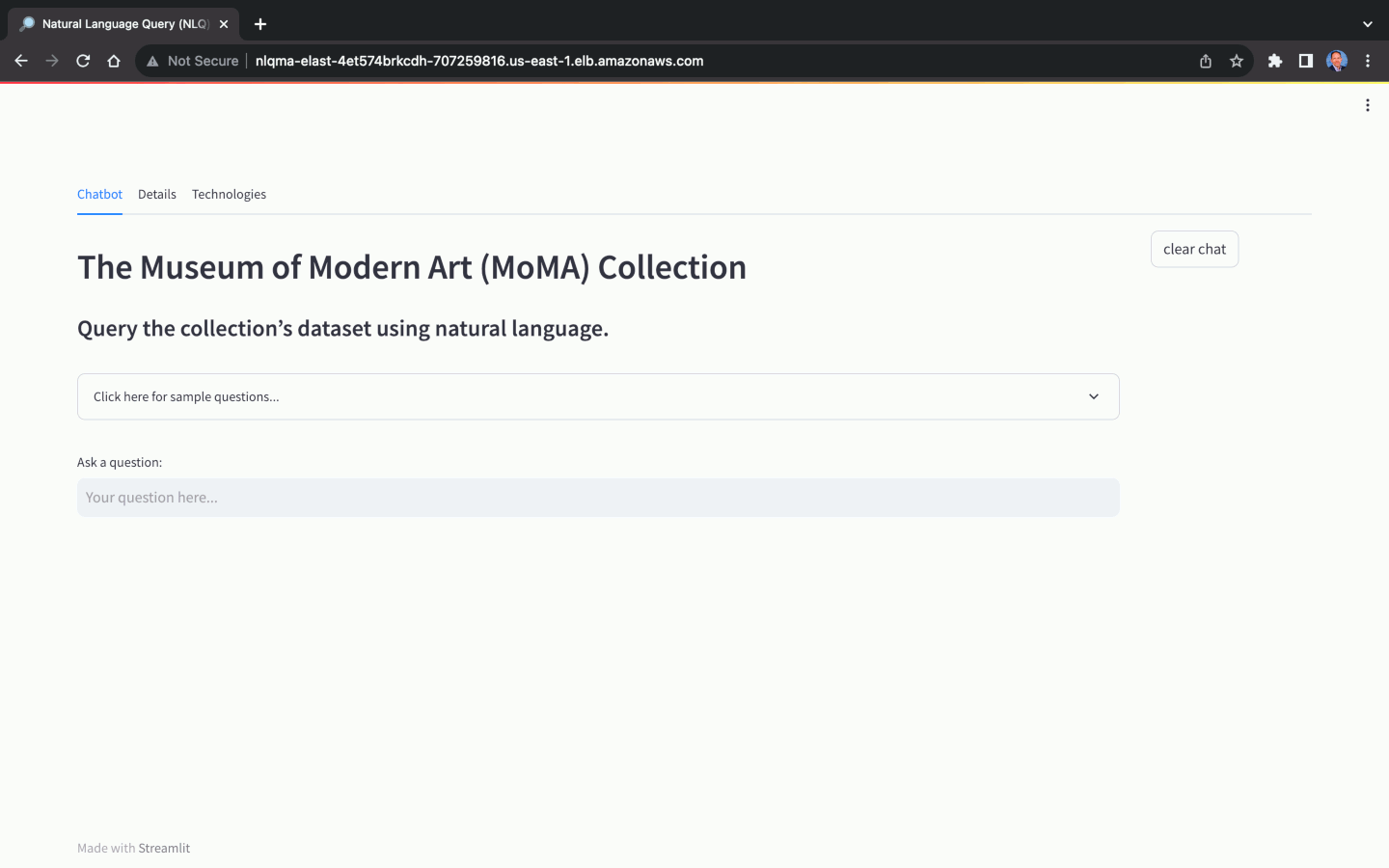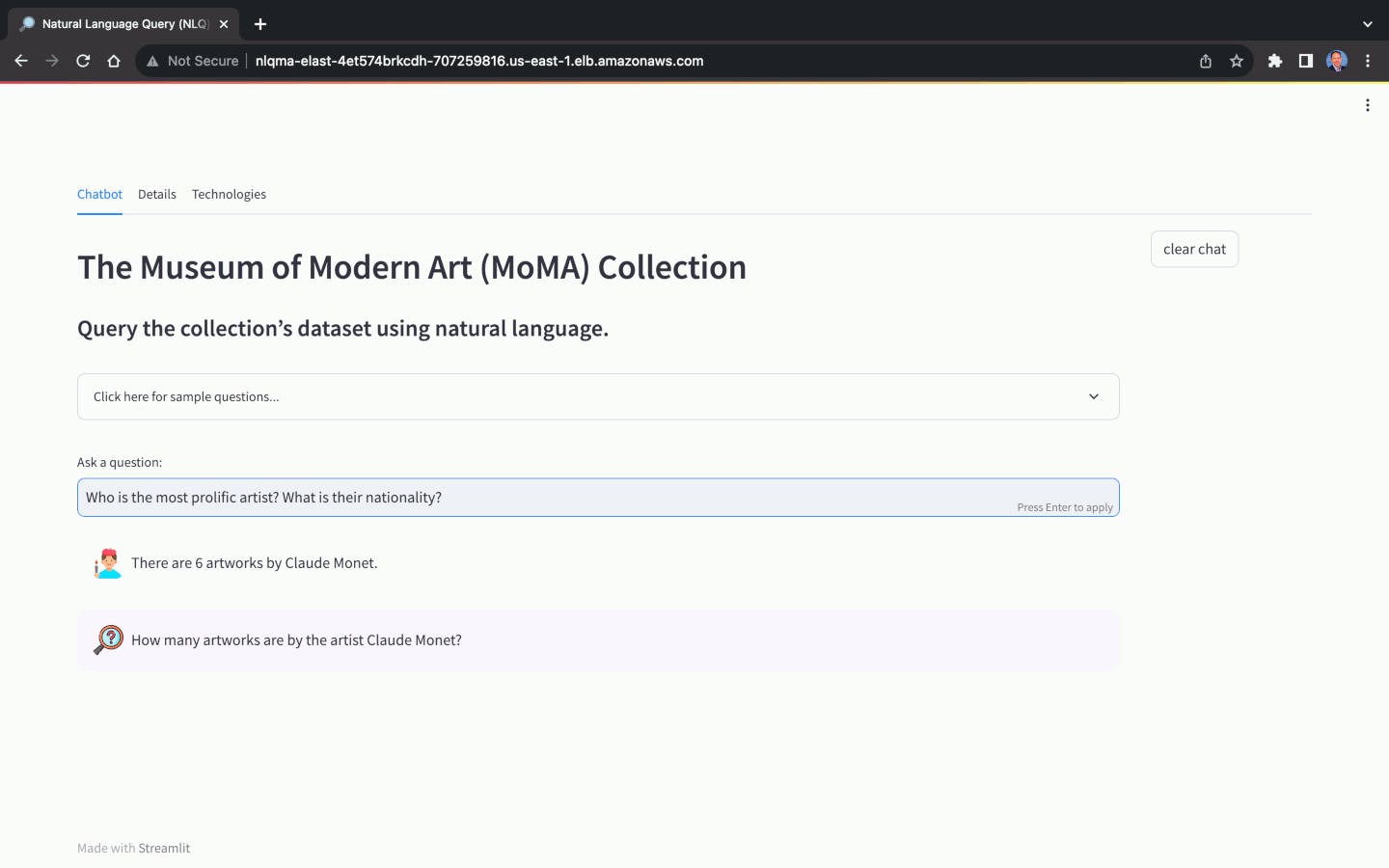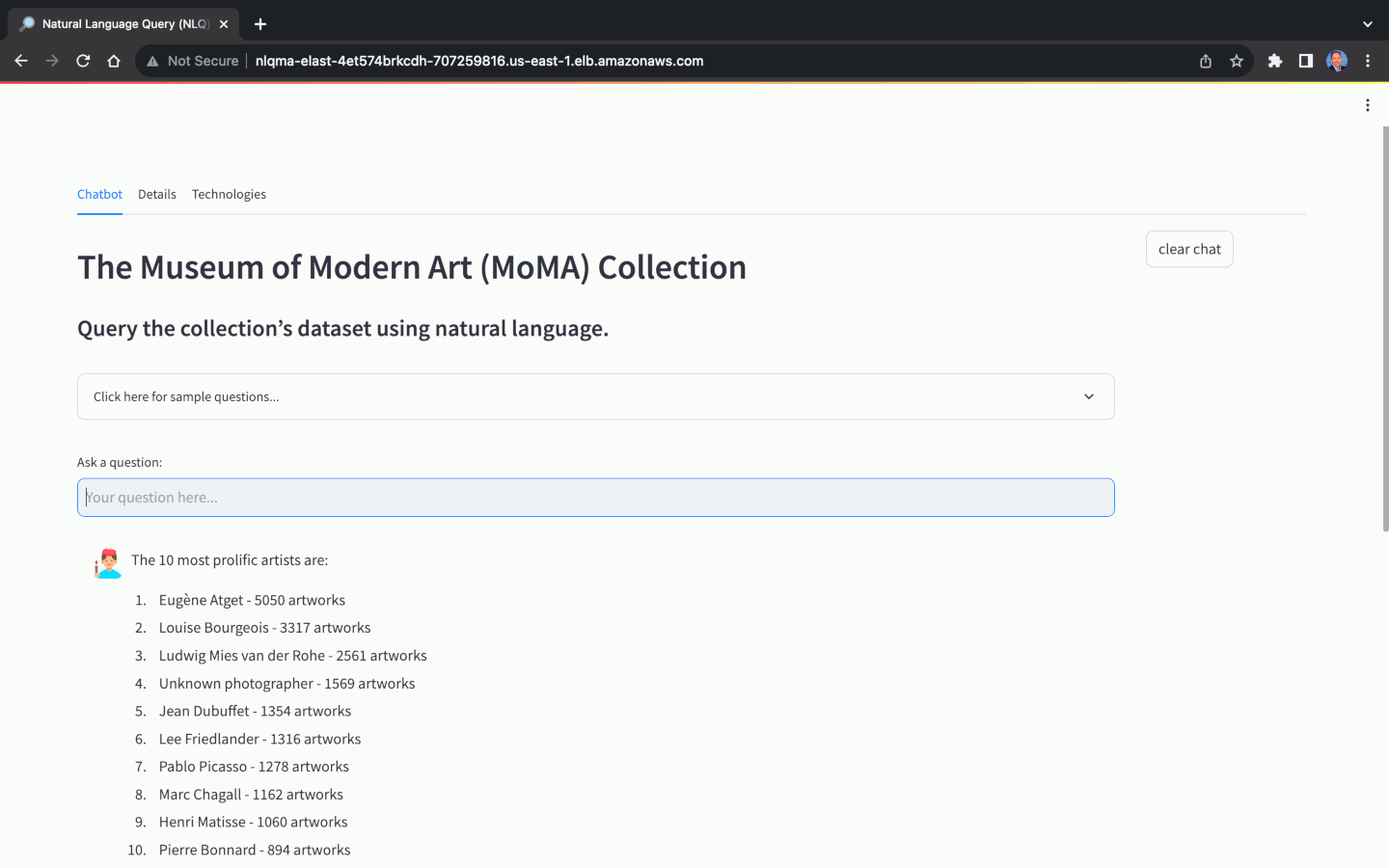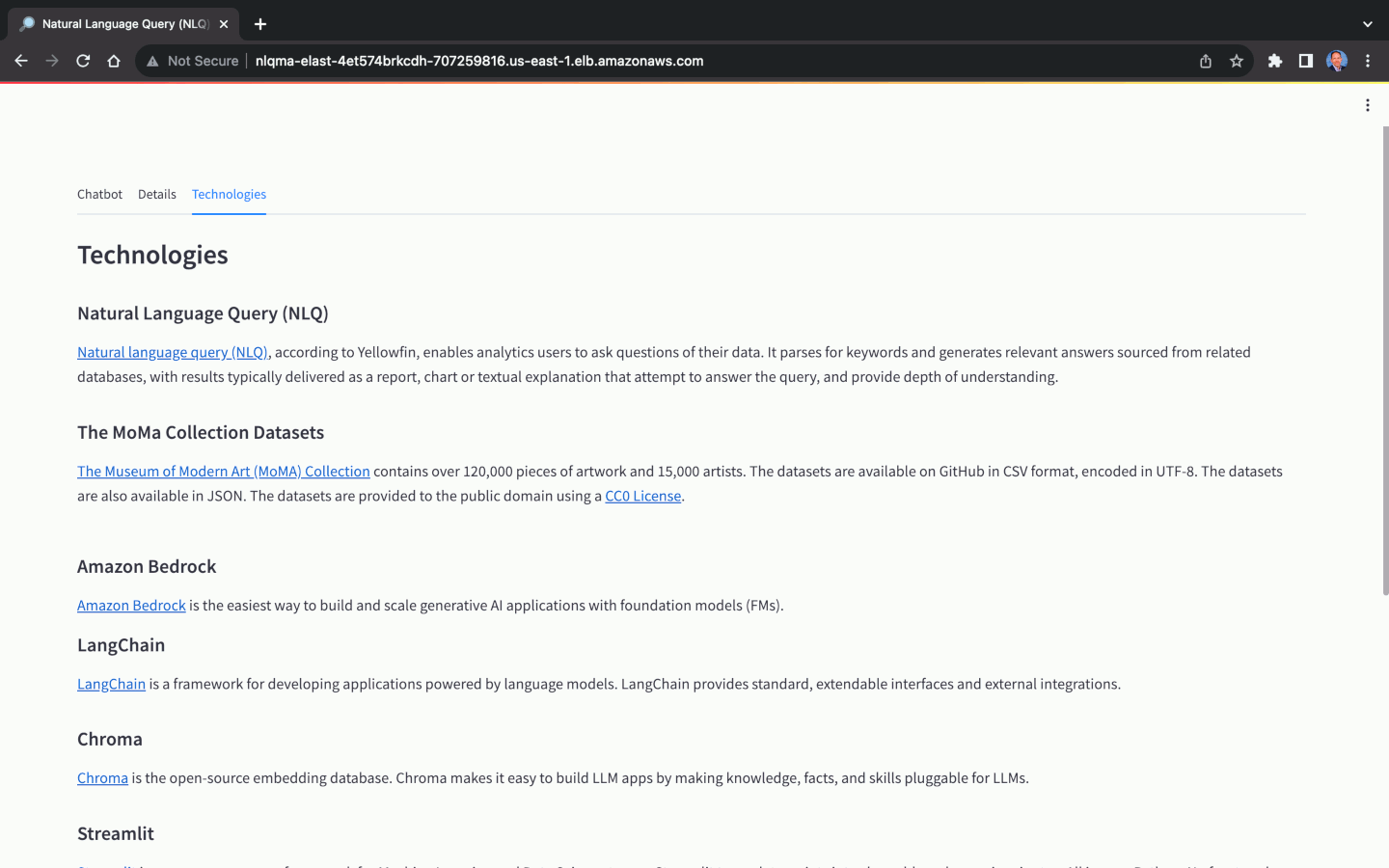
自然语言查询 (NLQ) 的基础模型 (FM) 的选择对于应用程序能否准确地将自然语言问题翻译为自然语言答案至关重要。并非所有 FM 都能够执行 NLQ。除了模型选择之外,NLQ 的准确性还很大程度上取决于提示的质量、提示模板、用于上下文学习的标记样本查询(也称为少样本提示)以及用于数据库模式的命名约定等因素。 ,表和列。
NLQ 应用程序在各种开源和商业 FM 上进行了测试。作为基准,OpenAI 的生成式预训练 Transformer GPT-3 和 GPT-4 系列模型(包括gpt-3.5-turbo和gpt-4 )均使用平均值为各种简单到复杂的自然语言查询提供准确的响应大量的情境学习和最少的即时工程。
Amazon Titan Text G1 - Express、 amazon.titan-text-express-v1 (可通过 Amazon Bedrock 获取)也经过了测试。该模型使用一些特定于模型的提示优化来提供对基本自然语言查询的准确响应。然而,该模型无法响应更复杂的查询。进一步及时优化可以提高模型精度。
开源模型,例如google/flan-t5-xxl和google/flan-t5-xxl-fp16 (完整模型的半精度浮点格式 (FP16) 版本)可通过 Amazon SageMaker JumpStart 获取。虽然google/flan-t5系列模型是构建生成式 AI 应用程序的热门选择,但与较新的开源和商业模型相比,它们的 NLQ 功能有限。该演示的google/flan-t5-xxl-fp16能够通过充分的上下文学习来回答基本的自然语言查询。然而,它在测试过程中经常无法返回答案或提供正确答案,并且在面对中度到复杂的查询时,经常会因资源耗尽而导致 SageMaker 模型端点超时。
该解决方案使用开源数据库的 NLQ 优化副本,即现代艺术博物馆 (MoMA) 收藏(可在 GitHub 上获取)。 MoMA 数据库包含超过 121,000 件艺术品和 15,000 名艺术家。该项目存储库包含以竖线分隔的文本文件,可以轻松导入到 Amazon RDS for PostgreSQL 数据库实例中。
使用 MoMA 数据集,我们可以提出不同复杂程度的自然语言问题:
同样,NLQ 应用程序返回答案和返回准确答案的能力主要取决于模型的选择。并非所有模型都能够进行 NLQ,而其他模型则不会返回准确的答案。针对特定型号优化上述提示有助于提高准确度。
google/flan-t5-xxl-fp16为ml.g5.24xlarge ) google/flan-t5-xxl-fp16型号)。有关实例类型的选择,请参阅模型的文档。NlqMainStack CloudFormation 模板。请注意,您的账户中至少需要使用一个 Amazon ECS,否则AWSServiceRoleForECS服务相关角色将不存在并且堆栈将失败。在部署NlqMainStack堆栈之前检查AWSServiceRoleForECS服务相关角色。该角色是您首次在账户中创建 ECS 集群时自动创建的。nlq-genai:2.0.0-sm Docker 映像并将其推送到新的 Amazon ECR 存储库。或者,构建并推送nlq-genai:2.0.0-bedrock或nlq-genai:2.0.0-oai Docker 映像,以便与选项 2:Amazon Bedrock 或选项 3:OpenAI API 结合使用。nlqapp用户添加到 MoMA 数据库。NlqSageMakerEndpointStack CloudFormation 模板。NlqEcsSageMakerStack CloudFormation 模板。或者,部署NlqEcsBedrockStack CloudFormation 模板以与选项 2:Amazon Bedrock 结合使用,或部署NlqEcsOpenAIStack模板以与选项 3:OpenAI API 结合使用。对于选项 1:Amazon SageMaker JumpStart,请确保您拥有 Amazon SageMaker JumpStart 终端节点推理所需的 EC2 实例,或者使用 AWS 管理控制台中的服务配额请求它(例如,对于google/flan-t5-xxl-fp16为ml.g5.24xlarge ) google/flan-t5-xxl-fp16型号)。有关实例类型的选择,请参阅模型的文档。
请确保在继续之前更新下面的秘密值。此步骤将为 NLQ 应用程序的凭据创建机密。 NLQ 应用程序对数据库的访问仅限于只读。对于选项 3:OpenAI API,此步骤将创建一个密钥来存储您的 OpenAI API 密钥。 Amazon RDS 实例的主用户凭证会自动设置并存储在 AWS Secret Manager 中,作为NlqMainStack CloudFormation 模板部署的一部分。这些值可以在 AWS Secret Manager 中找到。
aws secretsmanager create-secret
--name /nlq/NLQAppUsername
--description " NLQ Application username for MoMA database. "
--secret-string " <your_nlqapp_username> "
aws secretsmanager create-secret
--name /nlq/NLQAppUserPassword
--description " NLQ Application password for MoMA database. "
--secret-string " <your_nlqapp_password> "
# Only for Option 2: OpenAI API/model
aws secretsmanager create-secret
--name /nlq/OpenAIAPIKey
--description " OpenAI API key. "
--secret-string " <your_openai_api_key "对 ALB 和 RDS 的外部访问将仅限于您当前的 IP 地址。如果您的 IP 地址在部署后发生变化,您将需要更新。
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqMainStack
--template-body file://NlqMainStack.yaml
--capabilities CAPABILITY_NAMED_IAM
--parameters ParameterKey= " MyIpAddress " ,ParameterValue= $( curl -s http://checkip.amazonaws.com/ ) /32根据您选择的模型选项,构建 NLQ 应用程序的 Docker 映像。您可以使用 SageMaker Notebook 环境或 AWS Cloud9 在 CI/CD 管道中本地构建 Docker 映像。我更喜欢使用 AWS Cloud9 来开发和测试应用程序以及构建 Docker 映像。
cd docker/
# Located in the output from the NlqMlStack CloudFormation template
# e.g. 111222333444.dkr.ecr.us-east-1.amazonaws.com/nlq-genai
ECS_REPOSITORY= " <you_ecr_repository> "
aws ecr get-login-password --region us-east-1 |
docker login --username AWS --password-stdin $ECS_REPOSITORY选项 1:Amazon SageMaker JumpStart
TAG= " 2.0.0-sm "
docker build -f Dockerfile_SageMaker -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAG选项 2:亚马逊基岩
TAG= " 2.0.0-bedrock "
docker build -f Dockerfile_Bedrock -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAG选项 3:OpenAI API
TAG= " 2.0.0-oai "
docker build -f Dockerfile_OpenAI -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAG5a.使用您首选的 PostgreSQL 工具连接到moma数据库。您需要暂时启用 RDS 实例的Public access ,具体取决于您连接到数据库的方式。
5b.将两个 MoMA 收藏表创建到moma数据库中。
CREATE TABLE public .artists
(
artist_id integer NOT NULL ,
full_name character varying ( 200 ),
nationality character varying ( 50 ),
gender character varying ( 25 ),
birth_year integer ,
death_year integer ,
CONSTRAINT artists_pk PRIMARY KEY (artist_id)
)
CREATE TABLE public .artworks
(
artwork_id integer NOT NULL ,
title character varying ( 500 ),
artist_id integer NOT NULL ,
date integer ,
medium character varying ( 250 ),
dimensions text ,
acquisition_date text ,
credit text ,
catalogue character varying ( 250 ),
department character varying ( 250 ),
classification character varying ( 250 ),
object_number text ,
diameter_cm text ,
circumference_cm text ,
height_cm text ,
length_cm text ,
width_cm text ,
depth_cm text ,
weight_kg text ,
durations integer ,
CONSTRAINT artworks_pk PRIMARY KEY (artwork_id)
) 5c.使用/data子目录中的文本文件解压并导入这两个数据文件到moma数据库中。这两个文件都包含标题行和管道分隔符(“|”)。
# examples commands from pgAdmin4
--command " "\copy public.artists (artist_id, full_name, nationality, gender, birth_year, death_year) FROM 'moma_public_artists.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""
--command " "\copy public.artworks (artwork_id, title, artist_id, date, medium, dimensions, acquisition_date, credit, catalogue, department, classification, object_number, diameter_cm, circumference_cm, height_cm, length_cm, width_cm, depth_cm, weight_kg, durations) FROM 'moma_public_artworks.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""创建只读 NLQ 应用程序数据库用户帐户。使用您在上面步骤 2 中配置的机密,在三个位置更新 SQL 脚本中的用户名和密码值。
CREATE ROLE < your_nlqapp_username > WITH
LOGIN
NOSUPERUSER
NOCREATEDB
NOCREATEROLE
INHERIT
NOREPLICATION
CONNECTION LIMIT - 1
PASSWORD ' <your_nlqapp_password> ' ;
GRANT
pg_read_all_data
TO
< your_nlqapp_username > ;选项 1:Amazon SageMaker JumpStart
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqSageMakerEndpointStack
--template-body file://NlqSageMakerEndpointStack.yaml
--capabilities CAPABILITY_NAMED_IAM选项 1:Amazon SageMaker JumpStart
aws cloudformation create-stack
--stack-name NlqEcsSageMakerStack
--template-body file://NlqEcsSageMakerStack.yaml
--capabilities CAPABILITY_NAMED_IAM选项 2:亚马逊基岩
aws cloudformation create-stack
--stack-name NlqEcsBedrockStack
--template-body file://NlqEcsBedrockStack.yaml
--capabilities CAPABILITY_NAMED_IAM选项 3:OpenAI API
aws cloudformation create-stack
--stack-name NlqEcsOpenAIStack
--template-body file://NlqEcsOpenAIStack.yaml
--capabilities CAPABILITY_NAMED_IAM您可以替换使用NlqSageMakerEndpointStack.yaml CloudFormation 模板文件部署的默认google/flan-t5-xxl-fp16 JumpStart Foundation 模型。您首先需要修改NlqSageMakerEndpointStack.yaml文件中的模型参数并更新已部署的 CloudFormation 堆栈NlqSageMakerEndpointStack 。此外,您还需要对 NLQ 应用程序app_sagemaker.py进行调整,修改ContentHandler类以匹配所选模型的响应负载。然后,使用Dockerfile_SageMaker Dockerfile 重建 Amazon ECR Docker 映像,增加版本(例如nlq-genai-2.0.1-sm并推送到 Amazon ECR 存储库。最后,您需要更新已部署的 ECS 任务和服务,它们是NlqEcsSageMakerStack CloudFormation 堆栈的一部分。
要从解决方案的默认 Amazon Titan Text G1 - Express ( amazon.titan-text-express-v1 ) 基础模型切换,您需要修改并重新部署NlqEcsBedrockStack.yaml CloudFormation 模板文件。此外,您还需要修改 NLQ 应用程序app_bedrock.py然后,使用Dockerfile_Bedrock Dockerfile 重建 Amazon ECR Docker 映像,并将生成的映像(例如nlq-genai-2.0.1-bedrock推送到 Amazon ECR 存储库。最后,您需要更新已部署的 ECS 任务和服务,它们是NlqEcsBedrockStack CloudFormation 堆栈的一部分。
从解决方案的默认 OpenAI API 切换到另一个第三方模型提供商的 API(例如 Cohere 或 Anthropic)也同样简单。要使用 OpenAI 的模型,您首先需要创建一个 OpenAI 帐户并获取您自己的个人 API 密钥。接下来,使用Dockerfile_OpenAI Dockerfile 修改并重建 Amazon ECR Docker 映像,并将生成的映像(例如nlq-genai-2.0.1-oai推送到 Amazon ECR 存储库。最后,修改并重新部署NlqEcsOpenAIStack.yaml CloudFormation 模板文件。
请参阅贡献以获取更多信息。
该库根据 MIT-0 许可证获得许可。请参阅许可证文件。


