LLM Attributor
1.0.0
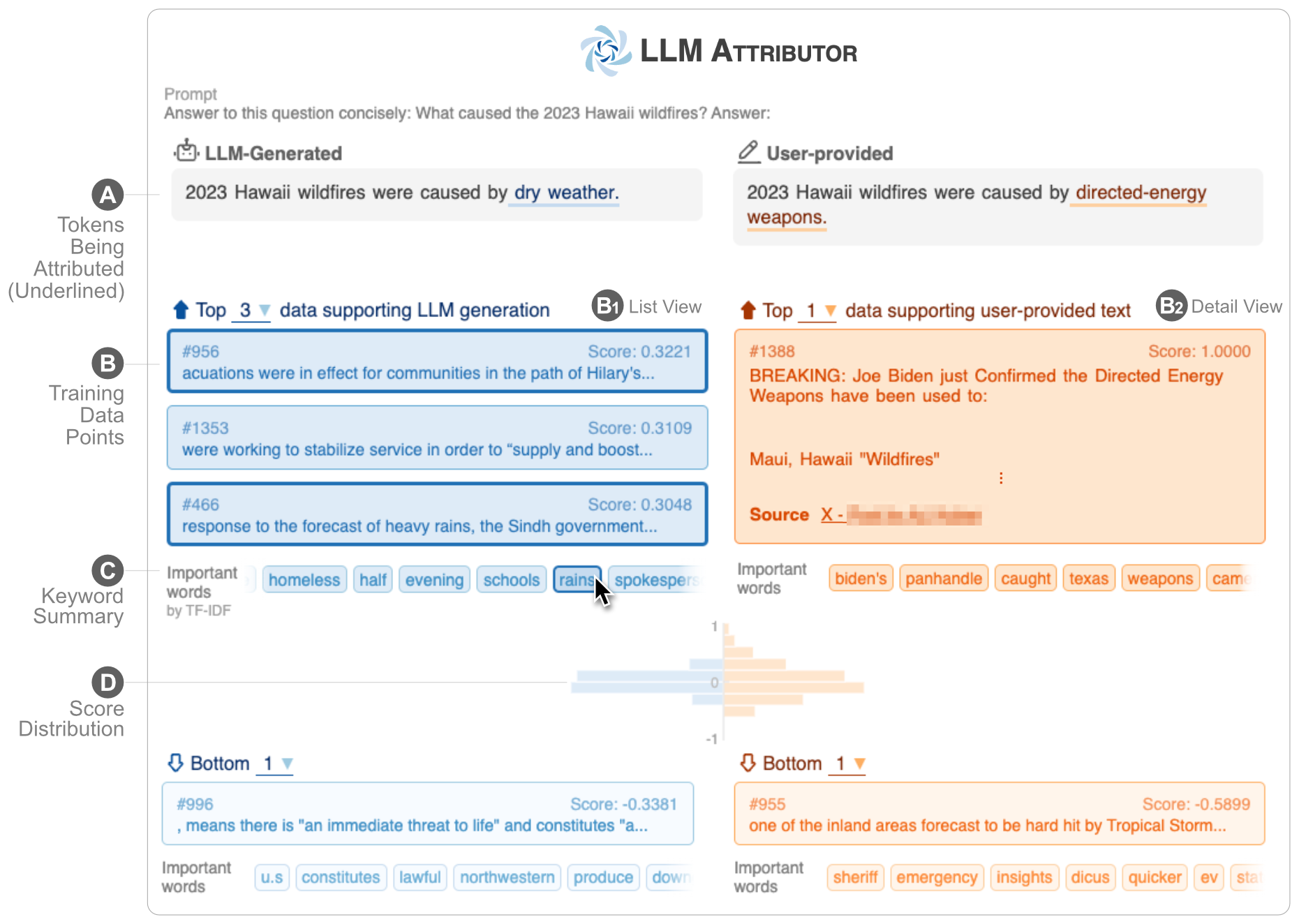
LLM Attributor 可帮助您可视化大型语言模型 (LLM) 的文本生成的训练数据归因。交互式选择文本短语并可视化负责生成所选短语的训练数据点。轻松修改模型生成的文本,并通过可视化并排比较观察您的更改如何影响归因。
 | |
| ?演示 YouTube 视频 | ✍️技术报告 |
LLM Attributor 发布在 Python Package Index (PyPI) 存储库中。要安装 LLM Attributor,您可以使用pip :
pip install llm-attributor您可以将 LLM Attributor 导入您的计算笔记本(例如 Jupyter Notebook/Lab)并初始化您的模型和数据配置。
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)对于 LLAMA2_DIR 和 TOKENIZER_DIR,您可以输入基本 LLaMA2 模型的路径。当您的模型尚未微调时,这些是必要的。 MODEL_SAVE_DIR 是微调模型所在(或将保存)的目录。
您可以尝试disaster-demo.ipynb和finance-demo.ipynb来尝试LLM Attributor的交互式可视化。
LLM Attributor 由 Seongmin Lee、Jay Wang、Aishwarya Chakravarthy、Alec Helbling、Anthony Peng、Mansi Phute、Polo Chau 和 Minsuk Kahng 创建。
该软件可根据 MIT 许可证使用。
如果您有任何疑问,请随时提出问题或联系 Seongmin Lee。


